PHP Web服务的价值
来源:互联网 发布:qq for mac 10.8 编辑:程序博客网 时间:2024/04/29 22:31
据我所知,Web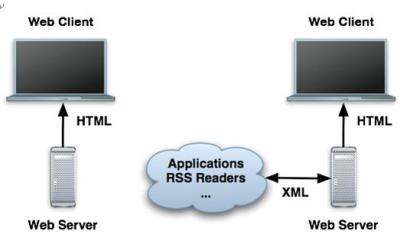
图1能更好地解释这个理论:
图1. 传统的web应用程序与面向服务的架构(SOA)
左侧为传统的web应用程序。
我经常听到人们谈论完全基于服务的应用服务器。这对于后端技术来说可能不错。但是对于普通的web应用程序,您总是希望它同时支持HTML和XML接口。拥有两种接口的一项好处在于,它强制您将业务逻辑集中到一个位置(可能是一个“中间层”),因此HTML和XML接口都可以与数据库通信并获得相同的结果。
允许web应用程序通过XML与其他程序通信的价值对您来说可能显而易见,但是对我来说并非如此,至少最初是这样。因此本文讲述一个示例,演示通过在应用程序中设置XML接口可以实现哪些功能。首先讲述简单的HTML前端,然后显示如何构建XML接口并添加各种阅读器(包括Ajax、RSS和Adobe Flex)。
文章应用程序
首先讲述的测试应用程序是数据库中有一个文章列表的程序。清单1显示了这个数据库。
清单 1. articles.sql
DROP TABLE IF EXISTS articles;
CREATE TABLE articles (
id INTEGER NOT NULL AUTO_INCREMENT,
title VARCHAR(255),
author VARCHAR(255),
description TEXT,
PRIMARY KEY( id ) );
INSERT INTO articles VALUES ( null,
'What I like about dogs', 'Megan Herrington',
'Everything that I love about dogs I learned in preschool' );
INSERT INTO articles VALUES ( null,
'Making action movies', 'Jack Herrington',
'How to script, produce and direct Hong Kong action flicks' );
INSERT INTO articles VALUES ( null,
'Super Paper Mario Tips', 'Lori Herrington',
'Everything you need to know to win at Paper Mario' );
INSERT INTO articles VALUES ( null,
'Why I bark', 'Oso Herrington',
'' );
该程序非常简单。它包含一个存储文章列表的简单表格;每篇文章都有标题、作者和描述。
清单2显示此表格的详细HTML前端。
清单2. articles.php
<html>
<head><title>Articles</title></head>
<body>
<?php
require_once( "DB.php" );
$db =& DB::Connect( 'mysql://root@localhost/articles1', array() );
if (PEAR::isError($db)) { die($db->getMessage()); }
$res = $db->query( "SELECT * FROM articles" );
$rows = array();
while( $res->fetchInto($row, DB_FETCHMODE_ASSOC) ) {
?>
<div class="title"><?php echo( $row['title'] ) ?></div>
<div class="author"><?php echo( $row['author'] ) ?></div>
<?php if ( strlen( $row['description'] ) > 0 ) { ?>
<div class="description"><?php echo( $row['description'] ) ?></div>
<?php } ?>
<br/>
<?php } ?>
</body>
</html>
如果一切工作正常并且设置了此数据库,就能在浏览器中导航到此页面时显示图2所示的页面。
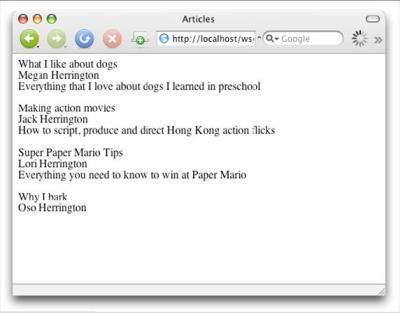
图2. 文章页面
看到的内容并不多,但是我希望这个示例尽量简单。主要是因为后面的内容不容易处理。
提供XML接口的一个主要原因是人们不必编写清单3所示的代码。
清单 3. fetch.rb
require 'net/http'
articles = []
Net::HTTP.start('localhost', 80) { |http|
response = http.get('/ws/articles.php')
body = response.body
body.scan( /(<div class="title">.*?)<br//>/m ) { |item|
title = item[0].scan( /<div class="title">(.*?)<//div>/ )
author = item[0].scan( /<div class="author">(.*?)<//div>/ )
description = item[0].scan( /<div class="description">(.*?)<//div>/ )
title = title[0][0] if ( title[0].length > 0 )
author = author[0][0] if ( author[0].length > 0 )
description = ( description.length > 0 ) ? description[0][0] : ''
articles.push( { :title => title,
:author => author, :description => description } )
}
}
p articles
这是基于Ruby的“屏幕截取器”。这个脚本以一个大文本字符串获取页面,然后使用一组复杂的正则表达式解析页面的标题、作者和描述元素。
在命令行运行时,将看到清单4所示的代码。
清单4. 运行fetch.rb
% ruby fetch.rb
[{:author=>"Megan Herrington", :description=>"Everything that I love about dogs I
learned in preschool", :title=>"What I like about dogs"}, {:author=>"Jack
Herrington", :description=>"How to script, produce and direct Hong Kong action
flicks", :title=>"Making action movies"}, {:author=>"Lori Herrington",
:description=>"Everything you need to know to win at Paper Mario", :title=>"Super
Paper Mario Tips"}, {:author=>"Oso Herrington", :description=>"", :title=>"Why I
bark"}]
是的,它获得了数据,但是不能获得这些元素的ID,因为HTML没有ID。
您可能想知道为什么我选择使用Ruby实现。这主要是因为它很酷,并且易于阅读,可是这里却看不到这些优点。但这不是Ruby的错。屏幕截取器本身就很复杂。它们难于编写、易于出错、难以维护,即使对接口的HTML稍加修改就可能崩溃。本文中的所有屏幕截取器代码都只有一个目的:说服您对数据设置XML接口。如果您的数据很有趣,人们就能通过某种途径找到它。如果您不支持XML,当您更新站点以“美化”界面时,就会获得屏幕截取,并且触怒客户。
添加XML服务
因此,为了避免屏幕截取问题,并制作一些炫酷的程序来使用我们的数据,我将对表格编写一个XML接口,如清单5所示。
清单5. artxml.php
<?php
require_once( "DB.php" );
$db =& DB::Connect( 'mysql://root@localhost/articles1', array() );
if (PEAR::isError($db)) { die($db->getMessage()); }
$dom = new DomDocument();
$dom->formatOutput = true;
$root = $dom->createElement( "articles" );
$dom->appendChild( $root );
$res = $db->query( "SELECT * FROM articles" );
$rows = array();
while( $res->fetchInto($row, DB_FETCHMODE_ASSOC) ) {
$art = $dom->createElement( "article" );
$art->setAttribute( 'id', $row['id'] );
$root->appendChild( $art );
$title = $dom->createElement( "title" );
$title->appendChild( $dom->createTextNode( $row['title'] ) );
$art->appendChild( $title );
$author = $dom->createElement( "author" );
$author->appendChild( $dom->createTextNode( $row['author'] ) );
$art->appendChild( $author );
$desc = $dom->createElement( "description" );
$desc->appendChild( $dom->createTextNode( $row['description'] ) );
$art->appendChild( $desc );
}
header( "Content-type: text/xml" );
echo $dom->saveXML();
?>
在命令行运行此脚本时,将获得清单6所示的输出。
清单6. 文章XML
% php artxml.php
<?xml version="1.0"?>
<articles>
<article id="1">
<title>What I like about dogs</title>
<author>Megan Herrington</author>
<description>Everything that I love about dogs I learned in
preschool</description>
</article>
<article id="2">
<title>Making action movies</title>
<author>Jack Herrington</author>
<description>How to script, produce and direct Hong Kong action
flicks</description>
</article>
...
这非常直观。有一个根文章标记,它包含一组文章标记。每个文章标记都有id属性(包含记录的数字id),以及存储相应数据的作者和描述标记。
我使用了PHP中的XML文档对象模型(Document Object Model,DOM)功能,而不是手动编写标记。这样DOM将为我处理所有XML节点平衡和编码工作。这是确保页面返回的XM总是有效的简便方式。强烈推荐使用XML DOM功能来输出XML。所有主要的web语言都支持构建和导出XML DOM。
获取XML
上文中我展示了从HTML中提取数据的HTML和Ruby代码。既然拥有了此XML服务,下面将观察获得相同数据的Ruby代码片断,但是这次使用XML语言。清单7显示了XML提取代码。
清单7. fetchxml.rb
require 'net/http'
require 'rexml/document'
articles = []
Net::HTTP.start('localhost', 80) { |http|
response = http.get('/ws/artxml.php')
body = response.body
doc = REXML::Document.new body
doc.each_element( '/articles/article' ) { |art|
articles.push( {
:id => art.attributes['id'],
:title => art.elements['title'].text,
:author => art.elements['author'].text,
:description => art.elements['description'].text
} )
}
}
p articles
这更简单。仍然能以相同的方式获得页面,但是将页面内存提供给REXML库,并使用XML功能轻松快捷地获得id、标题、作者和描述数据。此代码易于阅读、易于维护并且不会崩溃,除非XML格式发生变化,但这不太可能。
作为比较,我使用C#编写了相同的代码以显示如何使用两种不同的语言阅读单个数据源。如清单8所示。
清单8. WebServiceTest.cs
using System;
using System.IO;
using System.Net;
using System.Xml;
namespace wstest1
{
class WebServiceTest
{
[STAThread]
static void Main(string[] args)
{
HttpWebRequest r = (HttpWebRequest)WebRequest.Create(
"http://localhost/ws/artxml.php" );
WebResponse res = r.GetResponse();
string sPage;
StreamReader reader = new StreamReader( res.GetResponseStream() );
sPage = reader.ReadToEnd();
reader.Close();
res.Close();
XmlDocument doc = new XmlDocument();
doc.LoadXml( sPage );
foreach( XmlElement elArticle in doc.GetElementsByTagName( "article" ) )
{
string sTitle = (elArticle.SelectSingleNode( "title" )).InnerXml;
string sAuthor = (elArticle.SelectSingleNode( "author" )).InnerXml;
string sDescription = (elArticle.SelectSingleNode( "description"
)).InnerXml;
int nID = Int32.Parse( elArticle.Attributes["id"].Value );
}
}
}
}
解决了本文中最难以处理的部分后,下面应该讨论有趣的事情了,比如以其他方式使用XML可以实现什么功能。
在XSLT中使用XML
等等,我刚才是不是说最难以处理的部分已经解决了?哦,不好意思,还有另外一项。结果发现使用XML Style Sheet或XSL可以快速设置XML数据格式。清单9所示的代码设置web服务(从articles.php页面写入到HTML)所返回的XML代码的格式。
清单9. articles.xsl
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns="http://www.w3.org/TR/xhtml1/strict">
<xsl:output method="html" indent="yes" encoding="iso-8859-1" />
<xsl:template match="/">
<html>
<head><title>Article list</title></head>
<body>
<xsl:for-each select="/articles/article">
<div class="title"><xsl:value-of select="title"/></div>
<div class="author"><xsl:value-of select="author"/></div>
<xsl:if test="string-length( description ) > 0">
<div class="description"><xsl:value-of select="description"/></div>
</xsl:if>
</xsl:for-each>
</body></html>
</xsl:template>
</xsl:stylesheet>
读起来有点不太容易,但是这是您的XSL。基本上,XSL是模式匹配器,我定义了匹配传入XML树的根标记的XSL模板。它输出HTML报头,然后使用for-each循环遍历每篇文章,并输出标题、作者和描述的值(如果有)。
此样式表可以附加到XML输出本身,大多数浏览器将使用它将XML呈现到HTML以自动显示。怎么样!
Ajax
从应用程序中导出XML的最可能的理由是为了能够在web客户端中使用。客户端的JavaScript可以在加载页面之后从服务器请求XML,并以它所选择的任何方式(经常根据用户输入动态更改)呈现,并且不需要刷新页面。
清单10显示了一个基于Ajax的简单表格,它呈现来自XML feed的数据。
清单10. ajax.html
<html><head>
<script src="prototype.js"></script>
</head>
<body><table id="articles"></table>
<script>
new Ajax.Request( 'artxml.php', {
method: 'get',
onSuccess: function( transport ) {
var artTags = transport.responseXML.getElementsByTagName( 'article' );
for( var a = 0; a < artTags.length; a++ ) {
var author =
artTags[a].getElementsByTagName('author')[0].firstChild.nodeValue;
var title = artTags[a].getElementsByTagName('title')[0].firstChild.nodeValue;
var description =
artTags[a].getElementsByTagName('description')[0].firstChild.nodeValue;
var elTR = $('articles').insertRow( -1 );
var elTD1 = elTR.insertCell( -1 );
elTD1.innerHTML = author;
var elTD2 = elTR.insertCell( -1 );
elTD2.innerHTML = title;
var elTD3 = elTR.insertCell( -1 );
elTD3.innerHTML = description;
}
}
} );
</script></body></html>
此代码使用Prototype.js库从数据库访问数据,然后使用浏览器中的XML DOM功能访问作者、标题和描述字段。然后,使用HTML DOM函数针对数据集中的每篇文章向“articles”表格添加新行和单元格。
图3显示了Ajax代码在浏览器中的输出。
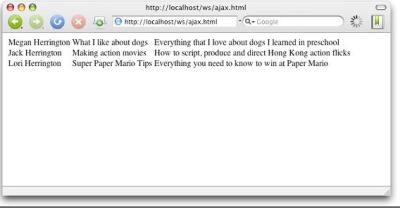
图3. 页面的Ajax版本
这是非常基础的示例,但是完全不必向
使用Flex访问XML
下一代内容丰富的Internet应用程序框架(如Adobe Flex)是基于XML产生和发展起来的。因此可以轻松使用和显示XML数据。观察清单11所示的示例Flex应用程序。
清单11. wstest.mxml
<?xml version="1.0" encoding="utf-8"?>
<mx:Application xmlns:mx="http://www.adobe.com/2006/mxml" layout="vertical">
<mx:XML id="articles" source="http://localhost/ws/artxml.php" />
<mx:DataGrid dataProvider="{articles..article}" width="400">
<mx:columns>
<mx:Array>
<mx:DataGridColumn dataField="author" headerText="Author" />
<mx:DataGridColumn dataField="title" headerText="Title" />
<mx:DataGridColumn dataField="description" headerText="Description" />
</mx:Array>
</mx:columns>
</mx:DataGrid>
</mx:Application>
其中并没有实际代码,仅仅是对XML数据源的引用,然后此数据源被传送到DataGrid控件。图4显示了输出。
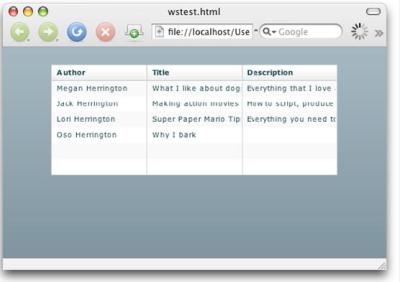
图4. 列表的Flex版本
是不是很酷?实现此功能不需要任何代码。这只是Flex 和ActionScript使用XML可以实现的基本功能。ActionScript有一个内置的语言扩展,名为E4X。借助E4X,可以像使用“点标注”语法一样简单地导航XML文档树。这意味着没有太多沉闷的XML DOM方法,仅仅是直观对象和数组引用,就像内存中有任何其他数据结构一样。
标准化
我使用了仅适于本示例的XML风格。但是也可以使用标准XML格式实现,如RSS。清单12中的代码以RSS格式显示了相同数据库输出。
清单12. artrss.php
<?php
require_once( "DB.php" );
$db =& DB::Connect( 'mysql://root@localhost/articles1', array() );
if (PEAR::isError($db)) { die($db->getMessage()); }
$dom = new DomDocument();
$dom->formatOutput = true;
$rss = $dom->createElement( "rss" );
$rss->setAttribute( "version", "0.91" );
$dom->appendChild( $rss );
$root = $dom->createElement( "channel" );
$rss->appendChild( $root );
$rtitle = $dom->createElement( "title" );
$rtitle->appendChild( $dom->createTextNode( "Article list" ) );
$root->appendChild( $rtitle );
$rdesc = $dom->createElement( "description" );
$rdesc->appendChild( $dom->createTextNode( "The article list" ) );
$root->appendChild( $rdesc );
$res = $db->query( "SELECT * FROM articles" );
$rows = array();
while( $res->fetchInto($row, DB_FETCHMODE_ASSOC) ) {
$art = $dom->createElement( "item" );
$root->appendChild( $art );
$title = $dom->createElement( "title" );
$title->appendChild( $dom->createTextNode( $row['title'] ) );
$art->appendChild( $title );
$title = $dom->createElement( "link" );
$title->appendChild( $dom->createTextNode(
"http://myhost/showarticle.php?id=".$row['id'] ) );
$art->appendChild( $title );
$desc = $dom->createElement( "description" );
$desc->appendChild( $dom->createTextNode( $row['description'] ) );
$art->appendChild( $desc );
}
header( "Content-type: text/xml" );
echo $dom->saveXML();
?>
此方法的好处在于,除了可以阅读XML的任何自定义代码之外,还可以使用所有的RSS工具。例如,可以在feed中指向我的Firefox浏览器,就会创建可以放到工具栏并检查更新的“活动书签”,如图5所示。
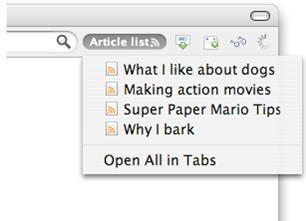
图5. 使用Firefox的RSS feed
当然,不是所有数据都能方便地设置为RSS格式,这没什么问题。但是如果可以成为RSS、RDF或任何其他方便的XML格式。那么最好遵循这些格式,而不是自己发明。
结束语
希望本文能够使您以正确的角度理解应用程序的web服务。我知道并没有讲述所有REST、XML/RPC或SOAP基础知识。有很多文章讨论过这些技术,多年以来,技术人员已经历过很多基于标准的噩梦。相反,我希望展示从应用程序中获得XML数据并以实用的方式使用它是件多么轻松的事情。如果我成功了,请写信告知我并展示从您的应用程序中提取的XML数据。也许我们可以使用其他web服务一起完成一个mash-up。
资源
Flex是基于开放源码的内容丰富的Internet应用程序开发环境,由Adobe提出。
?REST是简单的web服务标准,用来更直接地映射到HTTP协议。
SOAP是HTTP协议之上的高级的对象方法调用协议。
XML/RPC是HTTP协议之上的中间层方法调用协议,与SOAP相比,是略微轻量级的协议。
?RSS是聚合标准,用于博客条目和新文章之类的内容。
Google的Reader服务就是web浏览器或智能电话的强大、免费的RSS管理器。
?Prototype.js是免费的JavaScript库,可以帮助编写易于维护的跨浏览器Ajax代码。
相关技术文章:
Flex中的MySQL管理
利用Adobe AIR创建桌面对话应用程序
相关下载资源:
Flex Builder 3 Beta下载
Adobe AIR SDK Beta下载
- PHP Web服务的价值
- PHP Web服务的价值
- PHP Web服务的价值
- php web服务的价值
- PHP Web服务的价值
- 服务,服务,服务的价值!
- web服务nginx和php的相互关系
- PHP开发Web服务
- 结合 Web 服务和Pocket PC Phone Edition 创造价值
- GIS的核心价值——服务
- 服务价值特征分布的演化预测
- 服务机器人附加价值的最大化
- 应用NuSoap构建新型的基于PHP的Web服务
- 批处理技术对Web开发者的价值
- 价值5000元的web报表分享
- PHP的WEB服务编程工具---NuSoap介绍[转]
- 使用 PHP 开发基于 Web 服务的应用程序
- 使用 PHP 开发基于 Web 服务的应用程序
- 新版CCNA考试大纲
- 在Spring的应用中,用ref的属性指定依赖的3种模式比较
- 我的美丽天使(My Fair Angel)全剧情攻略
- ubuntu 与xp共享文件--成功
- ORA-12545:因目标主机或对象不存在解决
- PHP Web服务的价值
- prototype.js学习(2)
- extremcomponents
- SQL得到数据库的字段类型,及长度
- LPC2131 UART使用方法简介
- HTML颜色代码表
- MFC编程(一)
- 读取文本文件内指定行数的字符串并赋值给一个变量
- 详解交换机连接方式


