用CHI检验提取文本特征词
来源:互联网 发布:算法之美 中文版 pdf 编辑:程序博客网 时间:2024/04/30 13:40
0 背景
还是老师的文本分类的大作业。。。在对文本数据集分词并且除去停用词以后,我们就必须进行文本特征词的提取。所谓特征词就是可以代表此篇文章或者此类文章的一些词语。特征词提取的算法有很多,在此篇博客中讲的是CHI检验。CHI检验让我觉得概率论还是没有白学的。。。
1 CHI检验基础
卡方检定一个应用的场景是独立性检验。“独立性检定”验证从两个变数抽出的配对观察值组是否互相独立(例如:每次都从A国和B国各抽一个人,看他们的反应是否与国籍无关)。参考维基百科的皮尔森卡方检定,独立性检验的步骤如下:
1)计算卡方检定的统计值“ 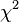 ”:把每一个观察值和理论值的差做平方后、除以理论值、再加总。
”:把每一个观察值和理论值的差做平方后、除以理论值、再加总。
”:把每一个观察值和理论值的差做平方后、除以理论值、再加总。 2)计算 统计值的自由度“ ”。
”。
统计值的自由度“”。 3)依据研究者设定的置信水准,查出自由度为 的卡方分配临界值,比较它与第1步骤得出的 统计值,推论能否拒绝虚无假设。
的卡方分配临界值,比较它与第1步骤得出的 统计值,推论能否拒绝虚无假设。 这些知道大体意思就可以了,上面的步骤是抄的维基百科上的,太学术了,先别打。。。。再看下面的就明白了。。。
2 CHI检验应用于文本特征词提取
在文本的特征词提取中,我们关注的是某个词term与类别C的是不是存在比较强的相关性,如果是,那么term就具有表征此类文章的能力,即term可以作为此类文本的特征词。那怎么表示某个词term与某个类别C的相关性呢,没错,CHI检验可以完成这个工作。学习概率论检验这一块的时候我们知道,t检验、卡方检验、F检验开始的时候都必须的有个假设。在文本分类中一般的假设是,“term和C是相互独立的”。接下来我们要算的就是CHI<term,C>的值是多少,这个值越大,就说明与假设的情况偏离的越远,就越说明term和C是相关的。好了,那怎么计算CHI值呢,先上一张图。
特征选择
1.属于“体育”
2.不属于“体育”
总
1.包含“篮球”
A
B
A+B
2.不包含“篮球”
C
D
C+D
总
A+C
B+D
A代表的是体育类文档中包含词语“篮球”的文档数,B,C,D同理。结合上面的讲的独立性检验的步骤,对于此表格的运算步骤如下所示:
1) 再看标题1下的独立性检验的步骤。对于A所在的表格,A的理论值应该是

因为A为实际值,也就是观测值,所以根据步骤1

同理有



最终

整理有

因为N,A+C,B+D是确定的,对每一个单词的计算也都是一样的,所以可以把它们省略掉。最终我们只需要计算的是

其实,我也不懂为啥这四个加一加就是 检验了。。。但是也不需要懂是不?
检验了。。。但是也不需要懂是不? 2)根据自由度df的计算公式 ,可以算出自由度为1。r为表格的行数,c为列数。其实也好理解了,当表格中四个单元格的某一个单元格的数值确定了,其它三个单元格的数值就随之确定了。这不就是自由度为1吗。迎合我们求篮球和体育的问题,自由度为1也就可以理解成,我们只是求“篮球”与体育的相关性。假设上面的四格表变成了(2,3)的表格,那自由度就为2了,那就不仅求的是“篮球”与体育的相关性了,还有“篮球”与娱乐(打比方,也可以是别的类别)的相关性了。
,可以算出自由度为1。r为表格的行数,c为列数。其实也好理解了,当表格中四个单元格的某一个单元格的数值确定了,其它三个单元格的数值就随之确定了。这不就是自由度为1吗。迎合我们求篮球和体育的问题,自由度为1也就可以理解成,我们只是求“篮球”与体育的相关性。假设上面的四格表变成了(2,3)的表格,那自由度就为2了,那就不仅求的是“篮球”与体育的相关性了,还有“篮球”与娱乐(打比方,也可以是别的类别)的相关性了。
,可以算出自由度为1。r为表格的行数,c为列数。其实也好理解了,当表格中四个单元格的某一个单元格的数值确定了,其它三个单元格的数值就随之确定了。这不就是自由度为1吗。迎合我们求篮球和体育的问题,自由度为1也就可以理解成,我们只是求“篮球”与体育的相关性。假设上面的四格表变成了(2,3)的表格,那自由度就为2了,那就不仅求的是“篮球”与体育的相关性了,还有“篮球”与娱乐(打比方,也可以是别的类别)的相关性了。 3)置信水准的确定以后,那多少数量的词语表征此类文档就确定了,也就是特征词的个数确定了,也确定了VSM空间向量模型中的维数。那么怎么确定这个置信水准呢?在上面算出每个词语与每个类别的CHI值之后,我们可以选取前a%大的词语作为我们的特征词。至于a的选取问题可以根据分类器的准确率调节。一开始的时候我们可以随便取一个值。
3. CHI检验的缺点
在上面的例子中其实可以看出,只要包含“篮球”的文章就会相应的+1,并没有考虑每个词在每篇文章中的词频,所以就是CHI的含义就是“只要出现过”!这样的话就会夸大低频词的作用,因为在选择特征词时把低频词和高频词放在了同样的高度上。这就是著名的“低频词缺陷”!改进的方法有很多种,这是我在网上看到的一种改进方案,不过只是交大作业嘛,所以。。。END!
0 0
- 用CHI检验提取文本特征词
- 文本分类 特征选取之CHI开方检验
- 文本分类 特征选取之CHI开方检验
- 文本分类-开方检验做特征提取的原理
- 卡方检验用于文本分类中的特征提取
- 文本特征词提取算法
- 文本特征提取
- 文本特征提取
- sklearn文本特征提取
- 文本特征提取
- sklearn文本特征提取
- 文本特征提取
- 文本特征提取
- sklearn文本特征提取
- 文本特征提取
- 文本特征提取
- 文本特征提取
- JAVA 文本特征提取
- DIV+CSS实操四:经管系网页内容模块内容添加(一)
- 看kali教程的一些总结(i春秋上的kali吧教程)
- XDU-1015 无聊的Light Light (贪心)
- 看!数据分析领域中最为人称道的七种降维方法
- 谈下自己编程的能力和一些项目
- 用CHI检验提取文本特征词
- 【拔苗计划】linux学习笔记——netstat命令学习
- 各种编程语言的深度学习库整理大全
- JSON需要的jar包和和String类型转JSON
- 利用firebug调试控件样式
- 倒油题目(Java源代码)
- 1099. Build A Binary Search Tree (30)
- VC6LineNumberAddin.dll 在win7x64下的注册问题
- Android实现自定义的相机


