文本特征词提取算法
来源:互联网 发布:javac 执行java文件 编辑:程序博客网 时间:2024/05/16 15:24
在文本分类中,需要先对文本分词,原始的文本中可能由几十万个中文词条组成,维度非常高。另外,为了提高文本分类的准确性和效率,一般先剔除决策意义不大的词语,这就是特征词提取的目的。本文将简单介绍几种文本特征词提取算法。
信息增益(IG)
对于一个系统,其信息熵为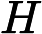

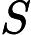



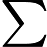
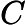
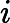
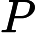


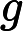
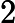

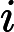
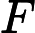
对特征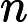
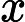
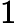
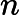

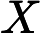
在分类中,特征词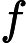
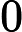

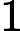
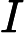
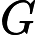

信息增益提取特征词步骤:
1,统计正负分类的文档数,记为
N1, N2. 2, 统计每个词在正文档出现的频率(A),负文档出现的频率(B),正文档不出现的频率(C),负文档不出现的频率(D).
3,计算信息熵
H(S)=−(N1N2+N1log(N1N1+N2)+N2N1+N2log(N1N1+N2)) 4,计算每个词
w的信息增益 IG(w)=H(S)+A+BN1+N2(AA+Blog(AA+B)+BA+Blog(BA+B)) +A+BN1+N2(AA+Blog(AA+B)+BA+Blog(BA+B)) 5,按照信息增益的大小排序,取topxx就行。
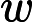
卡方校验(chi-square)
卡方检验最基本的思想就是通过观察实际值与理论值的偏差来确定理论的正确与否。具体做的时候常常先假设两个变量确实是独立的(“原假设”),然后观察实际值(观察值)与理论值(这个理论值是指“如果两者确实独立”的情况下应该有的值)的偏差程度,如果偏差足够小,我们就认为误差是很自然的样本误差,是测量手段不够精确导致或者偶然发生的,两者确确实实是独立的,此时就接受原假设;如果偏差大到一定程度,使得这样的误差不太可能是偶然产生或者测量不精确所致,我们就认为两者实际上是相关的,即否定原假设,而接受备择假设。
假设理论值是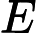
这个公式就是卡方检验使用的差值衡量公式,
特征选择属于体育不属于体育总计包含“足球”单词ABA+B不包含“足球”单词CDC+D总计A+CB+DN
如果“足球”与体育不相关,则体育类文章包含“足球”的比例等同于所有文章包含“足球”的比例,所以A的理论值是
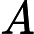

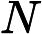
卡方差值
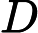
同样可以求出
 足球体育)
足球体育)卡方检验的缺点:只考虑了词是否出现,而没有考虑出现了多少次,容易夸大低频词的价值。如一个单词a在一类文章中都出现一次,而另外一个单词b在该类99%的文章中都出现了10次,但是b计算出来的卡方值要小于a,所以,在筛选的时候,容易筛掉单词b,这就是“低频词缺陷”,通常,考虑也需要考虑词频。
卡方提取特征词步骤:
1,统计正负分类的文档数,记为
N1, N2. 2, 统计每个词在正文档出现的频率(A),负文档出现的频率(B),正文档不出现的频率(C),负文档不出现的频率(D).
3,计算卡方
χ2=D11+D12+D21+D22=N(AD−BC)2(A+C)(A+B)(B+D)(C+D) 5,按照卡方值从大到小,取topxx就行。
- 文本特征词提取算法
- 用CHI检验提取文本特征词
- 文本特征提取
- 文本特征提取
- sklearn文本特征提取
- 文本特征提取
- sklearn文本特征提取
- 文本特征提取
- 文本特征提取
- sklearn文本特征提取
- 文本特征提取
- 文本特征提取
- 文本特征提取
- JAVA 文本特征提取
- sklearn文本特征提取
- NLP中的语言模型及文本特征提取算法
- 文本特征提取方法研究
- 文本特征提取方法研究
- Redis基础总结
- 使用 TF-Slim 设计复杂网络
- ListView实现全选,单选删除
- js实现点击按钮弹出上传文件的窗口
- matplotlib基础__之__绘制散点图
- 文本特征词提取算法
- python抓取几大票房统计系统数据的之专资办票房数据库
- 域名备案新手百问,备案问题一站解决
- linux文件管理系统Ext以及inode的概述
- MVP
- 有用
- C++宏定义详解
- PHP有关的设计模式
- 在for循环遍历列表的过程中不能删除列表中的元素


