神经网络_学习笔记1215
来源:互联网 发布:nginx 域名指向目录 编辑:程序博客网 时间:2024/04/30 23:20
1、理解神经网络,首先是我们要理解最基本的神经元模型:

这个“神经元”是一个以 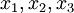 及截距
及截距 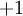 为输入值的运算单元,其输出为
为输入值的运算单元,其输出为 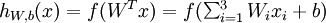 ,其中函数
,其中函数 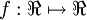 被称为“激活函数”。激活函数,不是指这个函数去激活什么,而是指如何把“激活的神经元的特征”通过函数把特征保留并映射出来。就比如激活函数中有阀值函数,即根据加权后的输出值,来判断输出{1,0}中的一个值。激活函数众所周知有tanh,sigmoid,ReLU等。
被称为“激活函数”。激活函数,不是指这个函数去激活什么,而是指如何把“激活的神经元的特征”通过函数把特征保留并映射出来。就比如激活函数中有阀值函数,即根据加权后的输出值,来判断输出{1,0}中的一个值。激活函数众所周知有tanh,sigmoid,ReLU等。
tanh 是设置一个值,大于0.5通过的为1,不然就为0。
sigmoid 采用S形函数。
ReLU 简单而粗暴,大于0的留下,否则一律为0。
比如如下的这样一个神经网络:

其中直线上的数字为权重,即是上式中的W。圆圈中的数字为阀值,即是定义式中函数f的一个参数(对于阀值函数来说就是阀值的值)。比如,第二层,如果输入大于1.5则输出1,否则0;第三层,如果输入大于0.5,则输出1,否则0。我们来一步步算。

第一层阀值是1.5,所以除了R1其他输出都是0。

第二层同理。
2、所谓神经网络就是将许多个单一“神经元”联结在一起,这样,一个“神经元”的输出就可以是另一个“神经元”的输入。例如,下图就是一个简单的神经网络:

我们使用圆圈来表示神经网络的输入,标上“+1”的圆圈被称为偏置节点,也就是截距项。神经网络最左边的一层叫做输入层,最右的一层叫做输出层。中间所有节点组成的一层叫做隐藏层,因为我们不能在训练样本集中观测到它们的值。同时可以看到,以上神经网络的例子中有3个输入单元(偏置单元不计在内),3个隐藏单元及1个输出单元。
我们用 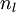 来表示网络的层数,本例中
来表示网络的层数,本例中 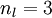 ,我们将第
,我们将第  层记为
层记为 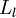 。本例神经网络有参数
。本例神经网络有参数 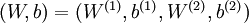 ,其中
,其中 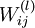 是第 层第
是第 层第  单元与第
单元与第 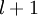 层第
层第  单元之间的联接参数(其实就是连接线上的权重),
单元之间的联接参数(其实就是连接线上的权重), 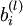 是第 层第 单元的偏置项。因此在本例中,
是第 层第 单元的偏置项。因此在本例中, 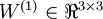 ,
, 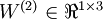 。注意,没有其他单元连向偏置单元(即偏置单元没有输入),因为它们总是输出 。同时,我们用
。注意,没有其他单元连向偏置单元(即偏置单元没有输入),因为它们总是输出 。同时,我们用 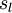 表示第 层的节点数(偏置单元不计在内)。
表示第 层的节点数(偏置单元不计在内)。
我们用 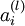 表示第 层第 单元的激活值(输出值)。当
表示第 层第 单元的激活值(输出值)。当 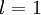 时,
时, 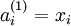 ,也就是第 个输入值(输入值的第 个特征)。对于给定参数集合
,也就是第 个输入值(输入值的第 个特征)。对于给定参数集合 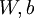 ,我们的神经网络就可以按照函数
,我们的神经网络就可以按照函数 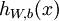 来计算输出结果。本例神经网络的计算步骤如下:
来计算输出结果。本例神经网络的计算步骤如下:

3、Element-Wise Operations:
对于一个向量或者是矩阵这种多元素的变量,Element-Wise Operations在于其运算是对每一个元素操作的。即,如果是加号,那么就每一个元素都要加上一个确定的值。
参考文章:
http://ufldl.stanford.edu/wiki/index.php/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C
https://www.douban.com/note/348196265/
- 神经网络_学习笔记1215
- 人工神经网络学习笔记_英文字母识别
- 人工神经网络学习笔记_传递函数汇总
- 人工神经网络学习笔记_性能优化
- 神经网络与深度学习_吴恩达 学习笔记(一)
- 深度学习与神经网络_吴恩达 学习笔记(二)
- 【学习笔记1】吴恩达_卷积神经网络_第一周卷积神经网络(1)
- 【学习笔记2】吴恩达_卷积神经网络_第一周卷积神经网络(2)
- 人工神经网络学习笔记_训练函数汇总
- 人工神经网络学习笔记_各个参数的确定
- 人工神经网络学习笔记_Hamming网络_竞争网络
- 人工神经网络学习笔记_Hopfield网络_递归网络
- [DeeplearningAI笔记]改善深层神经网络_深度学习的实用层面1.9_归一化normalization
- 斯坦福机器学习_神经网络
- 机器学习_初识神经网络
- 机器学习_算法_神经网络_BP
- 人工神经网络学习笔记
- 神经网络学习笔记
- Eclipse 修改web项目名称
- 当编译VC项目时提示不能打开生成的动态库.dll或者.exe文件
- 64位Ubuntu无法安装 lib32stdc++6问题
- 延迟是AR/VR体验的基础
- 在Async中使用Toast
- 神经网络_学习笔记1215
- java面试题
- 掌握设计模式
- 师父
- LeetCode 21:Merge Two Sorted Lists
- Android应用架构
- Qt中网络编程(网络接口,TCP,UDP)
- SQL注入与防范(PreparedStatement的优点)----JDBC-3
- hw员工培养计划


