并查集(union-find)学习报告
来源:互联网 发布:qq游戏宝宝淘宝 编辑:程序博客网 时间:2024/06/03 21:05
并查集(union-find)
并查集多用于检查动态连通性,具体参照算法第四版chapter1.5。
1、可检查两点是否在同一连通分量。
2、某一连通分量中有多少顶点
- UnionFind的API
- union-find基本实现
/** * * Created by zzhy on 2015/12/22. */public class UF { private int count = 0; private int id[]; public UF(int N) { count = N; id = new int[N]; for (int i = 0 ; i < N;i++) { id[i] = i; } } public int getCount() { return count; } public boolean connected(int p, int q) { return find(p) == find(q); } /** * 连接 p q * 如果p q 不在同一连接分量,则将pq连接 * 即:将p的值 都赋值为 q 的值,同时将--count * * @param p p * @param q q */ public void union(int p, int q) { } /** * * @param p p * @return p的值 */ public int find(int p) { }}这份代码是我们对UF的基本实现,他维护了一个整型数组id[],使得find()对于处在同一分量中的触点返回的值相同。union()方法在操作的时候必须要保证这一点。
对于find和union的实现基本分为三种
1. quick-find
2. quick-union
3. weighted-quick-union
- quick find:
在维护数组id[]时,保证了在同一分量中的顶点值相同,所以在find()时,只需要返回该元素的对应id即可。在connected(p,q)时只需要判断id[p]==id[q].
为了调用union(p,q),先判断两点是否已经在同一分量中,如果已在同一分量中,则不执行任何操作,否则将所有与pID相同的id值都更改为qID,此时即将两者归并为同一分量中。

/** * * @param p p * @return p的值 */ public int find(int p) { return id[p]; } /** * 连接 p q * 如果p q 不在同一连接分量,则将pq连接 * 即:将p的值 都赋值为 q 的值,同时将--count * * @param p p * @param q q */ public void union(int p, int q) { int pId = find(p); int qId = find(q); if (pId == qId) { return; } for (int i = 0 ; i < id.length ; i ++) { if (id[i] == pId) { id[i] = qId; } } --count;// StdArrayIO.print(id); }
quick-find 算法中,每次find()时只需要访问数组一次,而归并两个分量的union()操作数组次数在(N+3)~(2N+1)之间。
由于在添加的时候,至少需要调用N-1次的union,所以至少需要访问数组(N+3)(N-1)次,即N^2次
quick-union
该算法主要是用来提高union方法的速度,此时id数组赋予了同之前不一样的意义,该数组中存储的是另一触点的名称(也可能是自己)——我们将这种联系称为链接,在find方法时,通过给定的触点,依次查找id,直到达到根节点,即指向自己的节点(id[p] == p)。
在调用union(p,q)方法的时候,只需要将p的根节点保存为p的根节点即可。
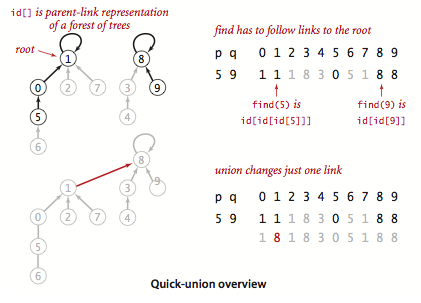
public int find(int p) { while (p != id[p]) { p = id[p]; } return p; } public void union(int p, int q) { int pRoot = find(p); int qRoot = find(q); if (pRoot!=qRoot) { id[pRoot] = qRoot; count--; } }加权quick-union算法
加权quick-union算法是对quick-union算法的改进,与quick-union算法不同的是,在每次union的时候,先判断p、q树的大小,将小树的根节点连接到大树的根节点上,此时需要一个单独的数组,sz[]来保存每个根节点对应的分量大小,初始化为0 。
public int find(int p) { while (p != id[p]) { p = id[p]; } return p; } public void union(int p, int q) { int pRoot = find(p); int qRoot = find(q); if (pRoot!=qRoot) { if(sz[pRoot]<sz[qRoot]){ id[pRoot] = qRoot; sz[qRoot] += sz[pRoot] }else{ id[qRoot] = pRoot; sz[pRoot] += sz[qRoot] } count--; } }- 并查集(union-find)学习报告
- 算法学习 并查集(Union-Find) (转)
- 并查集算法(Union-Find)
- 并查集(Union-Find Set)
- Union-Find 算法(并查集)
- 并查集:Union-Find(1)
- 并查集算法(union-find)
- 并查集(Union Find)
- 并查集(Union Find)简介
- uva11987Almost Union-Find (并查集)
- 并查集(Union-find Sets)
- 并查集(Union-Find)
- Union Find 并查集
- 并查集Union--Find
- 并查集Union-Find
- union-find(并查集)
- 并查集- Union-Find
- union find(并查集)
- 从僵尸网络追踪到入侵检测 第9章 Nepenthesp 配置二
- 如何在UEFI模式下安装64位win7系统
- poj 2109
- shell学习笔记
- 前端工程化-我们需要做什么
- 并查集(union-find)学习报告
- Hadoop科普文—常见的45个问题解答
- 【Lightoj】1214 - 能否整除(同余定理)
- 设计模式(二)单例模式的七种写法
- Repeater控件使用(含删除,分页功能)
- php输出需要的学号
- IE兼容性问题web.config设置
- 值得学习的C语言开源项目
- 关于初始化数据的总结


