spark yarn-client和yarn-cluster
来源:互联网 发布:苹果电脑怎么选 知乎 编辑:程序博客网 时间:2024/05/22 12:02
大数据系列零基础由入门到实战视频
问题导读
1.Spark在YARN中有几种模式?
2.Yarn Cluster模式,Driver程序在YARN中运行,应用的运行结果在什么地方可以查看?
3.由client向ResourceManager提交请求,并上传jar到HDFS上包含哪些步骤?
4.传递给app的参数应该通过什么来指定?
5.什么模式下最后将结果输出到terminal中?
Spark在YARN中有yarn-cluster和yarn-client两种运行模式:
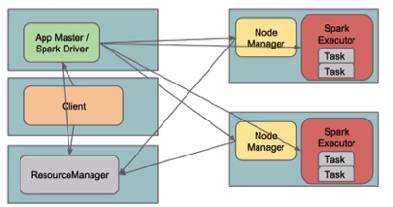
I. Yarn ClusterSpark Driver首先作为一个ApplicationMaster在YARN集群中启动,客户端提交给ResourceManager的每一个job都会在集群的worker节点上分配一个唯一的ApplicationMaster,由该ApplicationMaster管理全生命周期的应用。因为Driver程序在YARN中运行,所以事先不用启动Spark Master/Client,应用的运行结果不能在客户端显示(可以在history server中查看),所以最好将结果保存在HDFS而非stdout输出,客户端的终端显示的是作为YARN的job的简单运行状况。
by @Sandy Ryza

by 明风@taobao
从terminal的output中看到任务初始化更详细的四个步骤:
1. 由client向ResourceManager提交请求,并上传jar到HDFS上
这期间包括四个步骤:
a). 连接到RM
b). 从RM ASM(ApplicationsManager )中获得metric、queue和resource等信息。
c). upload app jar and spark-assembly jar
d). 设置运行环境和container上下文(launch-container.sh等脚本)
这期间包括四个步骤:
a). 连接到RM
b). 从RM ASM(ApplicationsManager )中获得metric、queue和resource等信息。
c). upload app jar and spark-assembly jar
d). 设置运行环境和container上下文(launch-container.sh等脚本)
2. ResouceManager向NodeManager申请资源,创建Spark ApplicationMaster(每个SparkContext都有一个ApplicationMaster)
3. NodeManager启动Spark App Master,并向ResourceManager AsM注册
4. Spark ApplicationMaster从HDFS中找到jar文件,启动DAGscheduler和YARN Cluster Scheduler
5. ResourceManager向ResourceManager AsM注册申请container资源(INFO YarnClientImpl: Submitted application)
6. ResourceManager通知NodeManager分配Container,这时可以收到来自ASM关于container的报告。(每个container的对应一个executor)
7. Spark ApplicationMaster直接和container(executor)进行交互,完成这个分布式任务。
需要注意的是:
a). Spark中的localdir会被yarn.nodemanager.local-dirs替换
b). 允许失败的节点数(spark.yarn.max.worker.failures)为executor数量的两倍数量,最小为3.
c). SPARK_YARN_USER_ENV传递给spark进程的环境变量
d). 传递给app的参数应该通过–args指定。
部署:
环境介绍:
hdp0[1-4]四台主机
hadoop使用CDH 5.1版本: hadoop-2.3.0+cdh5.1.0+795-1.cdh5.1.0.p0.58.el6.x86_64
直接下载对应2.3.0的pre-build版本http://spark.apache.org/downloads.html
下载完毕后解压,检查spark-assembly目录:
然后输出环境变量HADOOP_CONF_DIR/YARN_CONF_DIR和SPARK_JAR(可以设置到spark-env.sh中)
如果使用cloudera manager 5,在Spark Service的操作中可以找到Upload Spark Jar将spark-assembly上传到HDFS上。
Spark Jar Location (HDFS)
spark_jar_hdfs_path
/user/spark/share/lib/spark-assembly.jar
默认值
The location of the Spark jar in HDFS
Spark History Location (HDFS) spark.eventLog.dir
/user/spark/applicationHistory
默认值
The location of Spark application history logs in HDFS. Changing this value will not move existing logs to the new location.
提交任务,此时在YARN的web UI和history Server上就可以看到运行状态信息。
II. yarn-client
(YarnClientClusterScheduler)查看对应类的文件
在yarn-client模式下,Driver运行在Client上,通过ApplicationMaster向RM获取资源。本地Driver负责与所有的executor container进行交互,并将最后的结果汇总。结束掉终端,相当于kill掉这个spark应用。一般来说,如果运行的结果仅仅返回到terminal上时需要配置这个。
在yarn-client模式下,Driver运行在Client上,通过ApplicationMaster向RM获取资源。本地Driver负责与所有的executor container进行交互,并将最后的结果汇总。结束掉终端,相当于kill掉这个spark应用。一般来说,如果运行的结果仅仅返回到terminal上时需要配置这个。
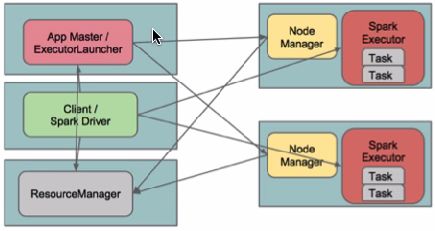
客户端的Driver将应用提交给Yarn后,Yarn会先后启动ApplicationMaster和executor,另外ApplicationMaster和executor都 是装载在container里运行,container默认的内存是1G,ApplicationMaster分配的内存是driver- memory,executor分配的内存是executor-memory。同时,因为Driver在客户端,所以程序的运行结果可以在客户端显 示,Driver以进程名为SparkSubmit的形式存在。
配置YARN-Client模式同样需要HADOOP_CONF_DIR/YARN_CONF_DIR和SPARK_JAR变量。
提交任务测试:
##最后将结果输出到terminal中
转自:http://www.aboutyun.com/thread-12294-1-1.html
0 1
- spark yarn-client和yarn-cluster
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark-submit模式yarn-cluster和yarn-client的区别
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark下Yarn-Cluster和Yarn-Client的区别
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- spark中yarn-client和yarn-cluster区别
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark Yarn-cluster 与 Yarn-client
- Spark on Yarn-cluster与Yarn-client
- Spark Yarn-cluster与Yarn-client
- spark on yarn中yarn-cluster与yarn-client区别
- POJ 1700 dp题解
- PHP 错误问题集合
- Swift中文教程(九) 类与结构
- CityHorizon-线段树
- Go语言使用CGO获取Windows的CPU使用率
- spark yarn-client和yarn-cluster
- mfc常见面试题
- iOS开发笔记--声明全局变量
- java提高篇(十二)-----equals()
- Android6.0 storage目录sd卡存储的路径创建
- 从技术细节看美团的架构
- Swift中文教程(十) 属性
- DE20 Derivative Formulas
- 神经网络算法


