决策树(Decision Tree)
来源:互联网 发布:mysql 5.7.17.tar.gz 编辑:程序博客网 时间:2024/06/05 20:49
决策树
引导
通俗来说,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑:

上图完整表达了这个女孩决定是否见一个约会对象的策略,其中绿色节点表示判断条件,橙色节点表示决策结果,箭头表示在一个判断条件在不同情况下的决策路径,图中红色箭头表示了上面例子中女孩的决策过程。这幅图基本可以算是一颗决策树,说它“基本可以算”是因为图中的判定条件没有量化,有了上面直观的认识,我们可以正式定义决策树了: 决策树是一个树结构。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
构造
构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能地“纯”。尽可能“纯”就是尽量让一个分裂子集中待分类项属于同一类别。分裂属性分为三种不同的情况:
1、属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2、属性是离散值且要求生成二叉决策树。此时使用属性划分的一个子集进行测试,按照“属于此子集”和“不属于此子集”分成两个分支。
3、属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
构造决策树的关键性内容是进行属性选择度量,属性选择度量是一种选择分裂准则,是将给定的类标记的训练集合的数据划分D“最好”地分成个体类的启发式方法,它决定了拓扑结构及分裂点split_point的选择。属性选择度量算法有很多,一般使用自顶向下递归分治法,并采用不回溯的贪心策略。这里介绍ID3常用算法。
ID3算法
从信息论知识中我们直到,期望信息越小,信息增益越大,从而纯度越高。所以ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。下面先定义几个要用到的概念。
设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:
其中pi表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量。
现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
而信息增益即为两者的差值:
ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂。下面我们继续用SNS社区中不真实账号检测的例子说明如何使用ID3算法构造决策树。为了简单起见,我们假设训练集合包含10个元素:
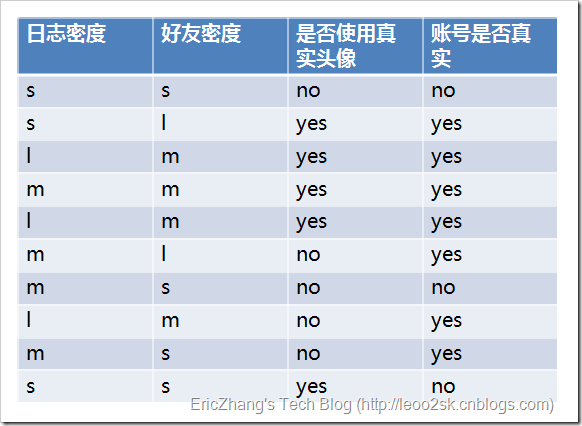
其中s、m和l分别表示小、中和大。
设L、F、H和R表示日志密度、好友密度、是否使用真实头像和账号是否真实,下面计算各属性的信息增益。
因此日志密度的信息增益是0.276。
用同样方法得到H和F的信息增益分别为0.033和0.553。
因为F具有最大的信息增益,所以第一次分裂选择F为分裂属性,分裂后的结果如下图表示:
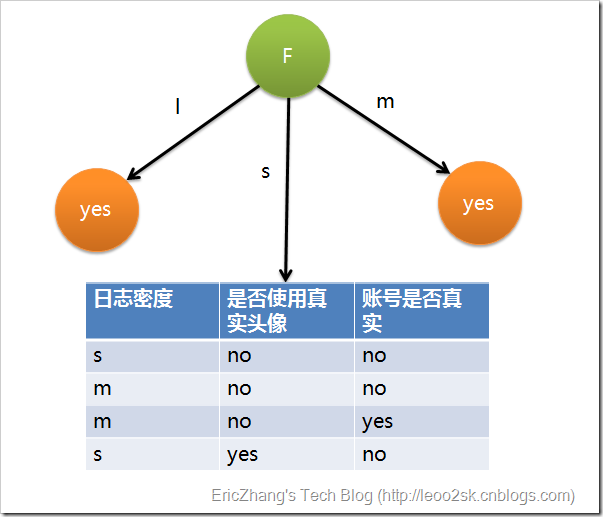
在上图的基础上,再递归使用这个方法计算子节点的分裂属性,最终就可以得到整个决策树。上面为了简便,将特征属性离散化了,其实日志密度和好友密度都是连续的属性。对于特征属性为连续值,可以如此使用ID3算法:先将D中元素按照特征属性排序,则每两个相邻元素的中间点可以看做潜在分裂点,从第一个潜在分裂点开始,分裂D并计算两个集合的期望信息,具有最小期望信息的点称为这个属性的最佳分裂点,其信息期望作为此属性的信息期望。
Python代码实现
<span style="font-family:Microsoft YaHei;">#_*_ coding:utf-8 _*_import operatorfrom math import logimport matplotlib.pyplot as pltdef createDataSet():#数据集和标签dataSet = [[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no']]labels = ['no surfacing', 'flippers']return dataSet, labelsdef calcShannonEnt(dataSet):#计算熵numEntries = len(dataSet)labelCounts = {}for featVec in dataSet:currentLabel = featVec[-1]if currentLabel not in labelCounts.keys():labelCounts[currentLabel] = 0labelCounts[currentLabel] += 1shannonEnt = 0.0for key in labelCounts: prob = float(labelCounts[key]) / numEntries shannonEnt -= prob * log(prob, 2)return shannonEntdataSet, labels = createDataSet()shannonEnt = calcShannonEnt(dataSet)def splitDataSet(dataSet, axis, value):#分裂数据集retDataSet = []for featVec in dataSet:if featVec[axis] == value:reducedFeatVec = featVec[:axis]reducedFeatVec.extend(featVec[axis+1:])retDataSet.append(reducedFeatVec)return retDataSetretDataSet = splitDataSet(dataSet, 0, 0)def chooseBestFeatureToSplit(dataSet):#选择最优属性进行分裂numFeatures = len(dataSet[0]) - 1baseEntropy = calcShannonEnt(dataSet)bestInfoGain = 0.0bestFeature = -1for i in range(numFeatures):featList = [example[i] for example in dataSet]uniqueVals = set(featList)newEntropy = 0.0for value in uniqueVals:subDataSet = splitDataSet(dataSet, i, value)prob = len(subDataSet)/float(len(dataSet))newEntropy += prob * calcShannonEnt(subDataSet)infoGain = baseEntropy - newEntropyif (infoGain > bestInfoGain):bestInfoGain = infoGainbestFeature = ireturn bestFeatureindex = chooseBestFeatureToSplit(dataSet)def majorityCnt(classList):#多数表决classCount = {}for vote in classList:if vote not in classCount.keys():classCount[vote] = 0classCount[vote] += 1sortedClassCount = sorted(classCount.iteritems(), key = operator.itemgetter(1), reverse = True)return sortedclassCount[0][0]def createTree(dataSet, labels):#构建决策树classList = [example[-1] for example in dataSet]if classList.count(classList[0]) == len(classList):return classList[0]if len(dataSet[0]) == 1: return majorityCnt(classList)bestFeat = chooseBestFeatureToSplit(dataSet)bestFeatLabel = labels[bestFeat]myTree = {bestFeatLabel:{}}del(labels[bestFeat])featValues = [example[bestFeat] for example in dataSet]uniqueVals = set(featValues)for value in uniqueVals:subLabels = labels[:]myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)return myTreemyTree = createTree(dataSet, labels)#画出决策树代码decisionNode = dict(boxstyle = "sawtooth", fc = "0.8")leafNode = dict(boxstyle = "round4", fc = "0.8")def plotNode(nodeTxt, centerPt, parentPt, nodeType):createPlot.ax1.annotate(nodeTxt, xy = parentPt, xytext = centerPt, va = "center", ha = "center", bbox = nodeType, arrowprops = dict(arrowstyle = "<-"))def createPlot(inTree):fig = plt.figure(1, facecolor = 'pink')fig.clf()axprops = dict(xticks=[], yticks=[])createPlot.ax1 = plt.subplot(111, frameon = False, **axprops)plotTree.totalW = float(getNumLeafs(inTree))#3plotTree.totalD = float(getTreeDepth(inTree))#2plotTree.xOff = -0.5/plotTree.totalWplotTree.yOff = 1.0plotTree(inTree, (0.5,1.0), '')plt.show()def getNumLeafs(myTree):numLeafs = 0firstStr = myTree.keys()[0]secondDict = myTree[firstStr]for key in secondDict.keys():if type(secondDict[key]).__name__ == 'dict':numLeafs += getNumLeafs(secondDict[key])else:numLeafs += 1return numLeafsdef getTreeDepth(myTree):maxDepth = 0firstStr = myTree.keys()[0]secondDict = myTree[firstStr]for key in secondDict.keys():if type(secondDict[key]).__name__ == 'dict':thisDepth = 1 + getTreeDepth(secondDict[key])else:thisDepth = 1if thisDepth > maxDepth: maxDepth = thisDepthreturn maxDepthdef plotMidText(cntrPt, parentPt, txtString):xMid = (parentPt[0] - cntrPt[0])/2.0 + cntrPt[0]yMid = (parentPt[1] - cntrPt[1])/2.0 + cntrPt[1]createPlot.ax1.text(xMid, yMid, txtString)def plotTree(myTree, parentPt, nodeTxt):numLeafs = getNumLeafs(myTree)depth = getTreeDepth(myTree)firstStr = myTree.keys()[0]cntrPt = (plotTree.xOff + (1.0+float(numLeafs))/2.0/plotTree.totalW,plotTree.yOff)plotMidText(cntrPt, parentPt, nodeTxt)plotNode(firstStr, cntrPt, parentPt, decisionNode)secondDict = myTree[firstStr]plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalDfor key in secondDict.keys():if type(secondDict[key]).__name__ == 'dict':plotTree(secondDict[key], cntrPt, str(key))else:plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalWplotNode(secondDict[key], (plotTree.xOff, plotTree.yOff),cntrPt,leafNode)plotMidText((plotTree.xOff, plotTree.yOff),cntrPt, str(key))plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalDcreatePlot(myTree)</span>
补充说明
如果属性用完了怎么办
剪枝
在实际构造决策树时,通常要进行剪枝,这时为了处理由于数据中的噪声和离群点导致的过分拟合问题。剪枝有两种:
先剪枝——在构造过程中,当某个节点满足剪枝条件,则直接停止此分支的构造。
后剪枝——先构造完成完整的决策树,再通过某些条件遍历树进行剪枝。
- 3.决策树Decision Tree
- 决策树(Decision Tree)
- 决策树(Decision Tree)
- 决策树(Decision Tree)
- 决策树decision tree分析
- 决策树(Decision Tree)
- 决策树Decision Tree
- 决策树Decision tree简析
- Decision Tree决策树
- 决策树(Decision tree)
- 决策树(Decision Tree)
- 决策树(Decision tree)
- 决策树(decision tree)
- 决策树Decision tree
- 决策树(Decision Tree)
- 决策树(Decision Tree)
- 决策树decision tree
- Decision Tree(决策树)
- Redis Hash(哈希)
- 2016 NOI冬令营
- Vmware下设置linux服务器可以被局域网内其他机器访问步骤
- 图形处理(七)基于热传播的测地距离计算-Siggraph 2013
- nginx sendfile 参数解释
- 决策树(Decision Tree)
- 数据库修改过表或字段后,更新dbml
- Android设计模式源码解析之外观模式(Facade)
- java特种兵读书笔记(5-1)——并发之基础介绍
- IE6下margin双倍边距Bug的处理办法
- android L SystemProperties属性解析
- Codeforces Round #271 (Div. 2) E. Pillars(线段树优化DP)
- 图形处理(八)点云重建(上)点云滤波、尖锐特征边增采样、移除离群点
- React Native 入门环境搭建


