Hadoop集群WordCount详解
来源:互联网 发布:淘宝店铺头像在线制作 编辑:程序博客网 时间:2024/04/28 01:32
Hadoop集群WordCount详解
- MapReduce理论介绍
- MapReduce处理过程
- MapReduce代码
1.MapReduce 理论介绍
1.1 MapReduce编程模型
MapReduce采用”分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是”任务的分解与结果的汇总”。
在Hadoop中,用于执行MapReduce任务的机器角色有两个:一个是JobTracker;另一个是TaskTracker,JobTracker是用于调度工作的,TaskTracker是用于执行工作的。一个Hadoop集群中只有一台JobTracker。
在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来。
需要注意的是,用MapReduce来处理的数据集(或任务)必须具备这样的特点:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
1.2 MapReduce处理过程
在Hadoop中,每个MapReduce任务都被初始化为一个Job,每个Job又可以分为两种阶段:map阶段和reduce阶段。这两个阶段分别用两个函数表示,即map函数和reduce函数。map函数接收一个
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: wordcount <in> <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1);}在MR程序中,首先创建一个Job,并进行配置,然后通过调用Job的waitForCompletion方法将Job提交到MapReduce集群。这个过程中,Job存在两种状态:Job.JobState.DEFINE和Job.JobState.RUNNING,创建一个Job后,该Job的状态为Job.JobState.DEFINE,Job内部通过JobClient基于org.apache.hadoop.mapred.JobSubmissionProtocol协议提交给JobTracker,然后该Job的状态变为Job.JobState.RUNNING。
运行WorkCount
1.准备工作
1)创建本地示例文件
首先在”/home/hadoop”目录下创建文件夹”file”。
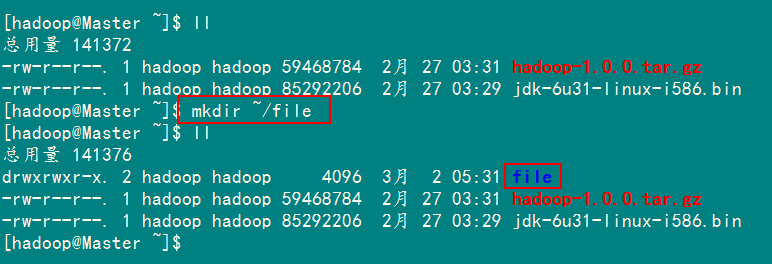
接着创建两个文本文件file1.txt和file2.txt,使file1.txt 内容为”Hello World”,而file2.txt的内容为”Hello Hadoop”。
2)在HDFS上创建输入文件夹


- 3)上传本地file中文件到集群的input目录下

2 运行例子
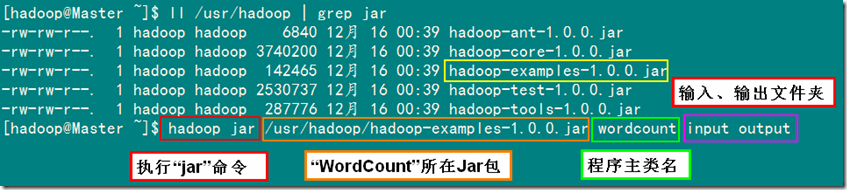
1)在集群上运行WordCount程序
备注:以input作为输入目录,output目录作为输出目录。
已经编译好的WordCount的Jar在”/usr/hadoop”下面,就是”hadoop-examples-1.0.0.jar”,所以在下面执行命令时记得把路径写全了,不然会提示找不到该Jar包。
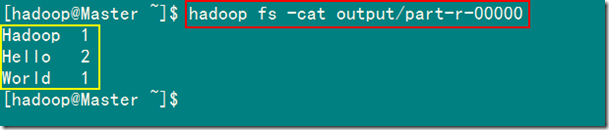
3 查看结果
- 1)查看HDFS上output目录内容

- 2)查看结果输出文件内容
3WordCount源码分析
Hadoop提供了如下内容的数据类型,这些数据类型都实现了WritableComparable接口,以便用这些类型定义的数据可以被序列化进行网络传输和文件存储,以及进行大小比较。
BooleanWritable:标准布尔型数值ByteWritable:单字节数值DoubleWritable:双字节数FloatWritable:浮点数IntWritable:整型数LongWritable:长整型数Text:使用UTF8格式存储的文本NullWritable:当<key,value>中的key或value为空时使用- Hadoop集群WordCount详解
- Hadoop集群 WordCount运行详解
- Hadoop集群系列7:WordCount运行详解
- Hadoop集群WordCount详解(二)
- Hadoop集群系列7:WordCount运行详解(1)
- hadoop集群运行wordcount步骤
- hadoop集群运行运行wordcount
- 配置Hadoop集群+WordCount案例
- 配置Hadoop集群+WordCount案例
- [Hadoop] WordCount运行详解
- hadoop WordCount运行详解
- hadoop 执行Wordcount详解
- Hadoop Wordcount 程序 详解
- Hadoop WordCount 详解
- Hadoop WordCount运行详解
- Hadoop-WordCount运行详解
- Hadoop示例程序WordCount详解
- Hadoop示例程序WordCount详解
- 关于while(geline(cin,s))语句执行解释
- 二叉树中所有节点的左右子树相互交换 递归与非递归程序
- 练习三 1003
- Android 中Textview字体加粗
- nyoj 148 fibonacci数列(二)
- Hadoop集群WordCount详解
- Mac下安装opencv-python
- 解决 U盘安装Centos后拔除U盘无法启动问题方法,重新建立引导分区
- 起泡法排序
- 常用小方法的整理(1)
- jQuery mobile 监听页面的各种生命周期
- 2 变量、常量、printf、scanf
- MTK Camera 开机启动流程
- gnirtSafoslewoVesreveR.345


