dfs 和bfs
来源:互联网 发布:淘宝装修全能助手 编辑:程序博客网 时间:2024/05/17 07:13
广度/宽度优先搜索(BFS)
【算法入门】
郭志伟@SYSU:raphealguo(at)qq.com
2012/04/27
1.前言
广度优先搜索(也称宽度优先搜索,缩写BFS,以下采用广度来描述)是连通图的一种遍历策略。因为它的思想是从一个顶点V0开始,辐射状地优先遍历其周围较广的区域,故得名。
一般可以用它做什么呢?一个最直观经典的例子就是走迷宫,我们从起点开始,找出到终点的最短路程,很多最短路径算法就是基于广度优先的思想成立的。
算法导论里边会给出不少严格的证明,我想尽量写得通俗一点,因此采用一些直观的讲法来伪装成证明,关键的point能够帮你get到就好。
2.图的概念
刚刚说的广度优先搜索是连通图的一种遍历策略,那就有必要将图先简单解释一下。
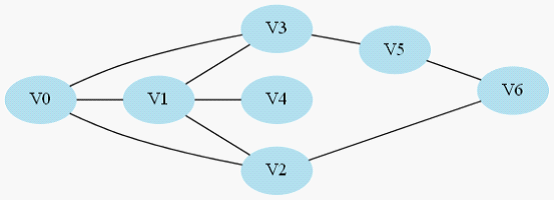
图2-1 连通图示例图
如图2-1所示,这就是我们所说的连通图,这里展示的是一个无向图,连通即每2个点都有至少一条路径相连,例如V0到V4的路径就是V0->V1->V4。
一般我们把顶点用V缩写,把边用E缩写。
3.广度优先搜索
3.1.算法的基本思路
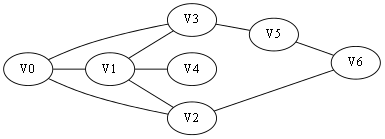
常常我们有这样一个问题,从一个起点开始要到一个终点,我们要找寻一条最短的路径,从图2-1举例,如果我们要求V0到V6的一条最短路(假设走一个节点按一步来算)【注意:此处你可以选择不看这段文字直接看图3-1】,我们明显看出这条路径就是V0->V2->V6,而不是V0->V3->V5->V6。先想想你自己刚刚是怎么找到这条路径的:首先看跟V0直接连接的节点V1、V2、V3,发现没有V6,进而再看刚刚V1、V2、V3的直接连接节点分别是:{V0、V4}、{V0、V1、V6}、{V0、V1、V5}(这里画删除线的意思是那些顶点在我们刚刚的搜索过程中已经找过了,我们不需要重新回头再看他们了)。这时候我们从V2的连通节点集中找到了V6,那说明我们找到了这条V0到V6的最短路径:V0->V2->V6,虽然你再进一步搜索V5的连接节点集合后会找到另一条路径V0->V3->V5->V6,但显然他不是最短路径。
你会看到这里有点像辐射形状的搜索方式,从一个节点,向其旁边节点传递病毒,就这样一层一层的传递辐射下去,知道目标节点被辐射中了,此时就已经找到了从起点到终点的路径。
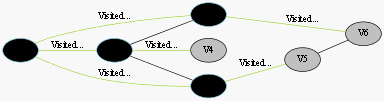
我们采用示例图来说明这个过程,在搜索的过程中,初始所有节点是白色(代表了所有点都还没开始搜索),把起点V0标志成灰色(表示即将辐射V0),下一步搜索的时候,我们把所有的灰色节点访问一次,然后将其变成黑色(表示已经被辐射过了),进而再将他们所能到达的节点标志成灰色(因为那些节点是下一步搜索的目标点了),但是这里有个判断,就像刚刚的例子,当访问到V1节点的时候,它的下一个节点应该是V0和V4,但是V0已经在前面被染成黑色了,所以不会将它染灰色。这样持续下去,直到目标节点V6被染灰色,说明了下一步就到终点了,没必要再搜索(染色)其他节点了,此时可以结束搜索了,整个搜索就结束了。然后根据搜索过程,反过来把最短路径找出来,图3-1中把最终路径上的节点标志成绿色。
整个过程的实例图如图3-1所示。
 初始全部都是白色(未访问)
初始全部都是白色(未访问)
 即将搜索起点V0(灰色)
即将搜索起点V0(灰色)
 已搜索V0,即将搜索V1、V2、V3
已搜索V0,即将搜索V1、V2、V3
 ……终点V6被染灰色,终止
……终点V6被染灰色,终止
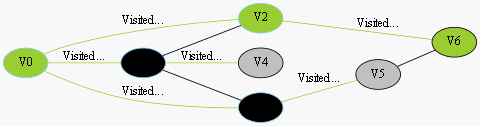 找到最短路径
找到最短路径
图3-1 寻找V0到V6的过程
3.2.广度优先搜索流程图
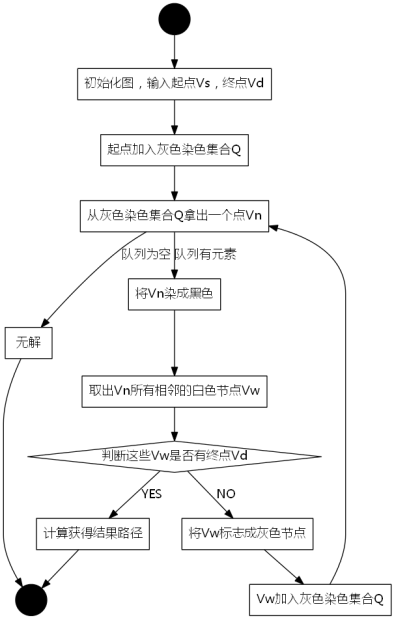
图3-2 广度优先搜索的流程图
在写具体代码之前有必要先举个实例,详见第4节。
4.实例
第一节就讲过广度优先搜索适用于迷宫类问题,这里先给出POJ3984《迷宫问题》。
《迷宫问题》
定义一个二维数组:
int maze[5][5] = {
0, 1, 0, 0, 0,
0, 1, 0, 1, 0,
0, 0, 0, 0, 0,
0, 1, 1, 1, 0,
0, 0, 0, 1, 0,
};
它表示一个迷宫,其中的1表示墙壁,0表示可以走的路,只能横着走或竖着走,不能斜着走,要求编程序找出从左上角到右下角的最短路线。
题目保证了输入是一定有解的。
也许你会问,这个跟广度优先搜索的图怎么对应起来?BFS的第一步就是要识别图的节点跟边!
4.1.识别出节点跟边
节点就是某种状态,边就是节点与节点间的某种规则。
对应于《迷宫问题》,你可以这么认为,节点就是迷宫路上的每一个格子(非墙),走迷宫的时候,格子间的关系是什么呢?按照题目意思,我们只能横竖走,因此我们可以这样看,格子与它横竖方向上的格子是有连通关系的,只要这个格子跟另一个格子是连通的,那么两个格子节点间就有一条边。
如果说本题再修改成斜方向也可以走的话,那么就是格子跟周围8个格子都可以连通,于是一个节点就会有8条边(除了边界的节点)。
4.2.解题思路
对应于题目的输入数组:
0, 1, 0, 0, 0,
0, 1, 0, 1, 0,
0, 0, 0, 0, 0,
0, 1, 1, 1, 0,
0, 0, 0, 1, 0,
我们把节点定义为(x,y),(x,y)表示数组maze的项maze[x][y]。
于是起点就是(0,0),终点是(4,4)。按照刚刚的思路,我们大概手工梳理一遍:
初始条件:
起点Vs为(0,0)
终点Vd为(4,4)
灰色节点集合Q={}
初始化所有节点为白色节点
开始我们的广度搜索!
手工执行步骤【PS:你可以直接看图4-1】:
1.起始节点Vs变成灰色,加入队列Q,Q={(0,0)}
2.取出队列Q的头一个节点Vn,Vn={0,0},Q={}
3.把Vn={0,0}染成黑色,取出Vn所有相邻的白色节点{(1,0)}
4.不包含终点(4,4),染成灰色,加入队列Q,Q={(1,0)}
5.取出队列Q的头一个节点Vn,Vn={1,0},Q={}
6.把Vn={1,0}染成黑色,取出Vn所有相邻的白色节点{(2,0)}
7.不包含终点(4,4),染成灰色,加入队列Q,Q={(2,0)}
8.取出队列Q的头一个节点Vn,Vn={2,0},Q={}
9.把Vn={2,0}染成黑色,取出Vn所有相邻的白色节点{(2,1), (3,0)}
10.不包含终点(4,4),染成灰色,加入队列Q,Q={(2,1), (3,0)}
11.取出队列Q的头一个节点Vn,Vn={2,1},Q={(3,0)}
12. 把Vn={2,1}染成黑色,取出Vn所有相邻的白色节点{(2,2)}
13.不包含终点(4,4),染成灰色,加入队列Q,Q={(3,0), (2,2)}
14.持续下去,知道Vn的所有相邻的白色节点中包含了(4,4)……
15.此时获得了答案
起始你很容易模仿上边过程走到终点,那为什么它就是最短的呢?
怎么保证呢?
我们来看看广度搜索的过程中节点的顺序情况:

图4-1 迷宫问题的搜索树
你是否观察到了,广度搜索的顺序是什么样子的?
图中标号即为我们搜索过程中的顺序,我们观察到,这个搜索顺序是按照上图的层次关系来的,例如节点(0,0)在第1层,节点(1,0)在第2层,节点(2,0)在第3层,节点(2,1)和节点(3,0)在第3层。
我们的搜索顺序就是第一层->第二层->第三层->第N层这样子。
我们假设终点在第N层,因此我们搜索到的路径长度肯定是N,而且这个N一定是所求最短的。
我们用简单的反证法来证明:假设终点在第N层上边出现过,例如第M层,M<N,那么我们在搜索的过程中,肯定是先搜索到第M层的,此时搜索到第M层的时候发现终点出现过了,那么最短路径应该是M,而不是N了。
所以根据广度优先搜索的话,搜索到终点时,该路径一定是最短的。
4.3.代码
我给出以下代码用于解决上述题目(仅仅只是核心代码):
- /**
- * 广度优先搜索
- * @param Vs 起点
- * @param Vd 终点
- */
- bool BFS(Node& Vs, Node& Vd){
- queue<Node> Q;
- Node Vn, Vw;
- int i;
- //用于标记颜色当visit[i][j]==true时,说明节点访问过,也就是黑色
- bool visit[MAXL][MAXL];
- //四个方向
- int dir[][2] = {
- {0, 1}, {1, 0},
- {0, -1}, {-1, 0}
- };
- //初始状态将起点放进队列Q
- Q.push(Vs);
- visit[Vs.x][Vs.y] = true;//设置节点已经访问过了!
- while (!Q.empty()){//队列不为空,继续搜索!
- //取出队列的头Vn
- Vn = Q.front();
- Q.pop();
- for(i = 0; i < 4; ++i){
- Vw = Node(Vn.x+dir[i][0], Vn.y+dir[i][1]);//计算相邻节点
- if (Vw == Vd){//找到终点了!
- //把路径记录,这里没给出解法
- return true;//返回
- }
- if (isValid(Vw) && !visit[Vw.x][Vw.y]){
- //Vw是一个合法的节点并且为白色节点
- Q.push(Vw);//加入队列Q
- visit[Vw.x][Vw.y] = true;//设置节点颜色
- }
- }
- }
- return false;//无解
- }
5.核心代码
为了方便适用于大多数的题解,抽取核心代码如下:
- /**
- * 广度优先搜索
- * @param Vs 起点
- * @param Vd 终点
- */
- bool BFS(Node& Vs, Node& Vd){
- queue<Node> Q;
- Node Vn, Vw;
- int i;
- //初始状态将起点放进队列Q
- Q.push(Vs);
- hash(Vw) = true;//设置节点已经访问过了!
- while (!Q.empty()){//队列不为空,继续搜索!
- //取出队列的头Vn
- Vn = Q.front();
- //从队列中移除
- Q.pop();
- while(Vw = Vn通过某规则能够到达的节点){
- if (Vw == Vd){//找到终点了!
- //把路径记录,这里没给出解法
- return true;//返回
- }
- if (isValid(Vw) && !visit[Vw]){
- //Vw是一个合法的节点并且为白色节点
- Q.push(Vw);//加入队列Q
- hash(Vw) = true;//设置节点颜色
- }
- }
- }
- return false;//无解
- }
深度优先搜索(DFS)
【算法入门】
郭志伟@SYSU:raphealguo(at)qq.com
2012/05/12
1.前言
深度优先搜索(缩写DFS)有点类似广度优先搜索,也是对一个连通图进行遍历的算法。它的思想是从一个顶点V0开始,沿着一条路一直走到底,如果发现不能到达目标解,那就返回到上一个节点,然后从另一条路开始走到底,这种尽量往深处走的概念即是深度优先的概念。
你可以跳过第二节先看第三节,:)
2.深度优先搜索VS广度优先搜索
2.1演示深度优先搜索的过程
还是引用上篇文章的样例图,起点仍然是V0,我们修改一下题目意思,只需要让你找出一条V0到V6的道路,而无需最短路。
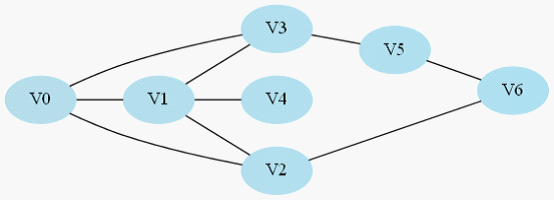
图2-1 寻找V0到V6的一条路(无需最短路径)
假设按照以下的顺序来搜索:
1.V0->V1->V4,此时到底尽头,仍然到不了V6,于是原路返回到V1去搜索其他路径;
2.返回到V1后既搜索V2,于是搜索路径是V0->V1->V2->V6,,找到目标节点,返回有解。
这样搜索只是2步就到达了,但是如果用BFS的话就需要多几步。
2.2深度与广度的比较
(你可以跳过这一节先看第三节,重点在第三节)
从上一篇《【算法入门】广度/宽度优先搜索(BFS) 》中知道,我们搜索一个图是按照树的层次来搜索的。
我们假设一个节点衍生出来的相邻节点平均的个数是N个,那么当起点开始搜索的时候,队列有一个节点,当起点拿出来后,把它相邻的节点放进去,那么队列就有N个节点,当下一层的搜索中再加入元素到队列的时候,节点数达到了N2,你可以想想,一旦N是一个比较大的数的时候,这个树的层次又比较深,那这个队列就得需要很大的内存空间了。
于是广度优先搜索的缺点出来了:在树的层次较深&子节点数较多的情况下,消耗内存十分严重。广度优先搜索适用于节点的子节点数量不多,并且树的层次不会太深的情况。
那么深度优先就可以克服这个缺点,因为每次搜的过程,每一层只需维护一个节点。但回过头想想,广度优先能够找到最短路径,那深度优先能否找到呢?深度优先的方法是一条路走到黑,那显然无法知道这条路是不是最短的,所以你还得继续走别的路去判断是否是最短路?
于是深度优先搜索的缺点也出来了:难以寻找最优解,仅仅只能寻找有解。其优点就是内存消耗小,克服了刚刚说的广度优先搜索的缺点。
3.深度优先搜索
3.1.举例
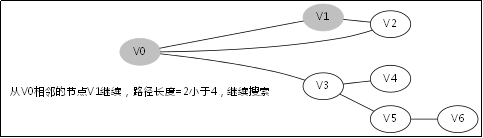
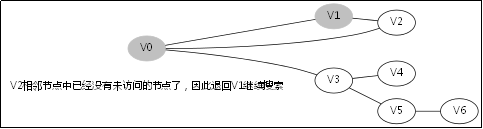
给出如图3-1所示的图,求图中的V0出发,是否存在一条路径长度为4的搜索路径。

图3-1
显然,我们知道是有这样一个解的:V0->V3->V5->V6。
3.2.处理过程


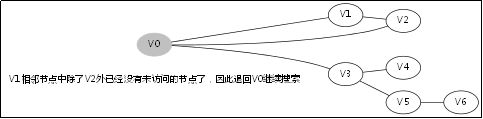
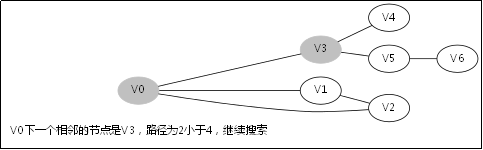
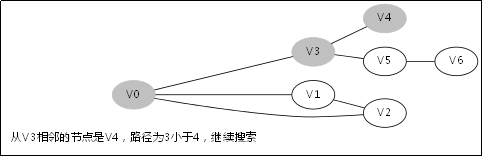
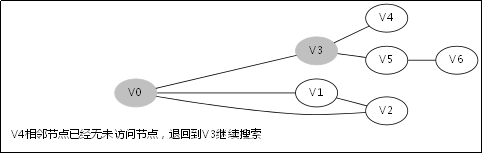
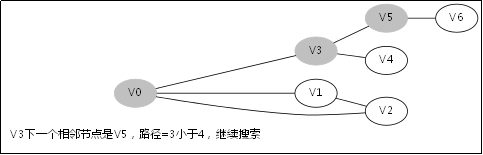
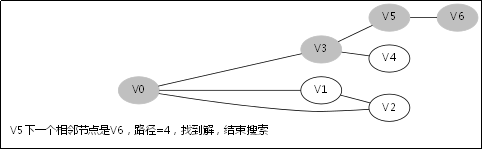
3.3.对应例子的伪代码
这里先给出上边处理过程的对应伪代码。
- /**
- * DFS核心伪代码
- * 前置条件是visit数组全部设置成false
- * @param n 当前开始搜索的节点
- * @param d 当前到达的深度,也即是路径长度
- * @return 是否有解
- */
- bool DFS(Node n, int d){
- if (d == 4){//路径长度为返回true,表示此次搜索有解
- return true;
- }
- for (Node nextNode in n){//遍历跟节点n相邻的节点nextNode,
- if (!visit[nextNode]){//未访问过的节点才能继续搜索
- //例如搜索到V1了,那么V1要设置成已访问
- visit[nextNode] = true;
- //接下来要从V1开始继续访问了,路径长度当然要加
- if (DFS(nextNode, d+1)){//如果搜索出有解
- //例如到了V6,找到解了,你必须一层一层递归的告诉上层已经找到解
- return true;
- }
- //重新设置成未访问,因为它有可能出现在下一次搜索的别的路径中
- visit[nextNode] = false;
- }
- //到这里,发现本次搜索还没找到解,那就要从当前节点的下一个节点开始搜索。
- }
- return false;//本次搜索无解
- }
- DFS和BFS
- BFS和DFS模板
- BFS和DFS算法
- BFS和DFS算法
- BFS和DFS
- dfs 和 bfs 解析
- POJ3083 -- BFS和DFS
- bfs 和 dfs 专题
- 关于BFS和DFS
- DFS和BFS模板
- bfs和dfs 模板
- 算法-DFS和BFS
- 【图】BFS和DFS
- dfs和bfs
- acm bfs和dfs
- bfs和dfs
- dfs 和bfs
- DFS和BFS
- angular directive简介
- 【codeforce】-697B-Barnicle(科学计数化十进制)麻烦!
- POJ 2236 Wireless Network
- java web学习过程中偶遇的中文乱码问题
- picasso-强大的Android图片下载缓存库
- dfs 和bfs
- BaseAdapter的使用
- Radar Installation
- 2016 Multi-University Training Contest 2 1005 Eureka
- Android自定义主题样式详解(结合自定义title栏讲解)
- gdb工作的基本原理
- Java 集合ArrayList与Vector的详解
- VNC和CUDA安装冲突
- UVA 10791 Minimum Sum LCM


