hadoop:基于Streaming实现作业提交
来源:互联网 发布:您的网络存在安全风险 编辑:程序博客网 时间:2024/06/05 00:35
Hadoop入门教程:基于Streaming实现作业提交,通过执行2.4.2中Streaming方式的编译命令后,会得到可执行程序WordcountMap和WordcountReduce,分别为词频统计的Map和Reduce,然后就可以使用Hadoop Streaming命令来实现作业提交。提交运行脚本的命令如下:
#!/bin/bash
#提交运行脚本
HADOOP_VERSION=1.0.4
Work_path=/home/nuoline/swordcount #用户程序所在目录
HADOOP_HOME=/home/nuoline/Hadoop-$HADOOP_VERSION
streaming=$HADOOP_HOME/contrib/streaming/Hadoop-streaming-$HADOOP_VERSION.jar
$HADOOP_HOME/bin/Hadoop jar $streaming \
-f?ile $Work_path/WordcountMap \
-mapper WordcountMap \
-f?ile $Work_path/WordcountReduce \
-reducer WordcountReduce \
-input /usr/nuoline/wordcount/sinput \
-output /usr/nuoline/wordcount/soutput \
-numReduceTasks 1 \
-jobconf MapRed.job.name="MyWordcount"
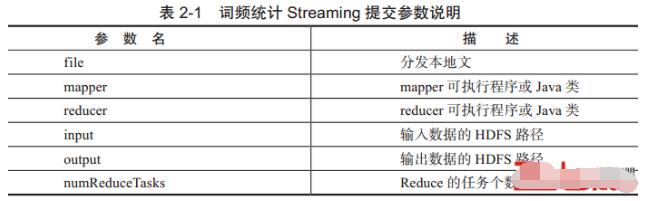
在上述提交运行脚本的命令中需要指定HADOOP_HOME环境变量。Streaming命令中最基本的参数说明如表2-1所示。
Streaming用户非常灵活,用户在提交作业到Hadoop集群之前最好能在本地测试一下。本地测试可以使用Linux命令来模拟Hadoop处理流程,命令如下:
cat input.txt / WordcountMap / sort / WordcountReduce > output.txt
input.txt是词频统计的测试用例,output.txt是输出,需要注意的是Map之后需要sort命令,这是因为在Hadoop中Map处理完之后会依据键key进行排序,如果程序在本地测试正常,就可以安全地将其提交到Hadoop上运行。Streaming本身还有很多用法,更详细的内容将在后续章节进行详细介绍。来源:CUUG官网
- hadoop:基于Streaming实现作业提交
- Hadoop:基于Pipes实现作业提交
- hadoop:基于Streaming实现的编译
- 非负矩阵分解算法基于hadoop streaming的实现
- python基于Hadoop Streaming实现简单的WordCount
- hadoop 作业提交
- Hadoop作业提交分析
- Hadoop作业提交跟踪
- Hadoop作业提交解决
- hadoop:Streaming接口实现
- Hadoop作业提交之客户端作业提交
- 基于Oozie实现MapReduce作业的自动提交功能
- 【Hadoop代码笔记】Hadoop作业提交之客户端作业提交
- hadoop之作业提交过程
- Hadoop 作业提交、查看、终止
- Hadoop作业提交终极解决
- Hadoop的作业提交过程
- Hadoop作业提交的方法
- 垂直居中应用
- 转载-------为什么要内存对齐 Data alignment: Straighten up and fly right
- 算法系列博客之写在前面的话
- orbslam2-基础理论(4)词袋
- JNI和NDK的学习总结
- hadoop:基于Streaming实现作业提交
- MongoDB备份与恢复
- 构建大数据产品-目录
- 基于JQuery的Ajax
- android 适配性完全攻略
- 1-4-2实例代码
- Android性能优化之被忽视的Memory Leaks
- 自定义ListView的下拉刷新控件
- RocketMQ性能压测分析


