第二章、解析资源文件
来源:互联网 发布:福建广电网络 编辑:程序博客网 时间:2024/05/29 14:31
第二章、解析资源文件
FBREADER github https://github.com/geometer/FBReaderJ
在这一章中我们将介绍代码解析资源文件来获得显示在进度条上的文字的流程。
解析流程中涉及的核心类有ZMLZMLProcessor、ZLXMLParser、ZLXMLReader三个类以及ZLTreeResource类。
ZMLZMLProcessor、ZLXMLParser、ZLXMLReader这三个类是读取xml文件的核心类。
关于xml文件的读取流程,我们在第四章“XML文件处理 -- 读取”中还会详细介绍。不过,第四章中介绍的读取流程比这一章节中介绍的流程要来得复杂。复杂的原因是,这章中涉及读取的资文件都是正常的xml文件,读取时无需作特殊处理。而第四章中介绍的读取流程是针对epub文件内部的xml文件,epub文件是压缩过的(关于epub文件的内部组成可以参考第四章“epub文件处理 -- epub文件内部组成”),所以必须先把epub文件中的一部分解压成正常的xml文件,然后才能开始正常读取流程。
说到这里,我们有必要先来介绍一下关于FBReader程序自己定义的三种文件格式类以及资源文件、epub文件又都对应着哪类文件格式。
FBReader的自定义文件格式类分别在org.geometerplus.zlibrary.core.filesystem包与org.amse.ys.zip包里面。

org.geometerplus.zlibrary.core.filesystem包里面,
ZLFile类是基类,ZLResourceFile、ZLPhysicalFile、ZLArchiveFile是ZLFile类的子类,ZLZipEntryFile是ZLArchiveFile的子类。
ZLResourceFile类专门用来处理资源文件,这一章中要解析的assets文件夹下的资源文件都可以ZLResourceFile类来处理。
ZLPhysicalFile类专门用来处理普通文件,eoub文件就可以用一个ZLPhysicalFile类来代表。
ZLZipEntryFile类用来处理epub文件内部的xml文件,这个类会在第五章“epub文件处理 -- 解压epub文件”中出现。
这三个文件类都实现了getInputStream抽象方法,不用的文件类会通过这个方法获得针对当前文件类的字节流类。
AndroidAssetsFile类(ZLResourceFile类的子类)的getInputStream方法会返回AssetInputStream类,这个类可以将资源文件转换成byte数组。
ZLPhysicalFile类的getInputStream方法会返回FileInputStream类,这个类可以将普通的文件转换成byte数组。
ZLZipEntryFile类的getInputStream方法会返回FileInputStream类,这个类可以将epub内部压缩过的xml文件转换成可以正常解析的byte数组
转换的流程请会在第五章“epub文件处理 -- 解压epub文件”中详细介绍。
继续回到读取xml文件的核心类ZMLZMLProcessor、ZLXMLParser、ZLXMLReader。
解析核心类调用顺序
这三个核心类的调用顺序一般是这样的:
1、ZLXMLReaderAdapter抽象类的子类(ResourceTreeReader类)里面的read方法调用ZLXMLProcessor类的read方法

2、ZLXMLProcessor类的read方法通过AndroidAssetsFile类(ZLResourceFile类的子类)的getInputStream方法获取一个针对资源文件的字节流类(AssetInputStream类),并以这个字节流类为参数初始化了一个针对资源文件的字符流类。接着,就调用了ZLXMLParser类的doIt方法。

3、 ZLXMLParser类的doIt方法利用字符流类将文件转换成一个char数组。再利用for循环迭代byte数组的过程中,doIt方法又反过来调用ZLXMLReaderAdapter抽象类的子类(ResourceTreeReader类)的startElementHandler与endElementHandler方法对byte数组中元素所代表的不同节点进行操作。
PS:当大家读到第六章“epub文件处理 -- 解析 container文件与.opf文件”的时候,我们还会再来回顾这三个核心类的调用顺序。

介绍完读取xml文件的三个核心类之后,再来介绍下ZLTreeResource类。ZLTreeResource类是ZLResource类的子类,ZLTreeResource类多了myChildren和myRoot属性。ZLTreeResource类多出的两个属性可以用来表示母节点以及子节点。读取xml文件的三个核心类会配合ZLTreeResource类将xml资源文件转换成一个层级数据结构。
核心类已经介绍完毕了,下面来看下详细的源码。
UIUtil类中的wait方法
首先回到UIUtil类中的wait方法,这个方法调用了ZLResource类中的resourse静态方法。

ZLResource类resourse静态方法
resource方法中又调用了ZLTressResource类中的buildTree方法。

ZLTressResource类buildTree方法
buildTree方法中定义了ourRoot属性,作为母节点。同时,还设置了ourLanguag和our'Country两个属性,还记得我之前说的assets/resourses/application这个资源文件夹中默认文件uk.xml吗?就是在这里设置的。接着buildTree方法调用了ZLTreeResource类中loadData方法(无参数loadData以及两参数loadData)。

ZLTreeResource类loadData方法
无参数的loadData方法首先初始化了ResourceTreeReader类,然后又调用了两参数的loadData方法,这个方法中调用了ResourceTreeReader类中的readDocument方法。


ResourceTreeReader类readDocument方法
readDocument方法中设置了myStack属性,之后所有的资源文件数据都会加载到myStack属性之中。再接着就是ResourceTreeReader类的read方法了,这个方法负责读取xml格式的资源文件。

ResourceTreeReader类read方法
看到ResourceTreeReader类(ZLXMLProcessor类的子类)的read的方法,大家应该是很熟悉的吧。因为我们刚刚介绍过这个方法。三个读取xml文件的调用顺序就是从“ZLXMLReader接口某一个实现类(ResourceTreeReader类)里面的read方法”开始的。在调用顺序的第三步,资源文件会被一个字符流类转换成一个byte数组。然后利用for循环迭代byte数组,通过ResourceTreeReader类的startElementHandler与endElementHandler方法对byte数组中元素所代表的不同节点进行操作。
在继续介绍解析流程之前,我们先来介绍下xml格式的资源文件集体的内容是如何的。资源文件的位置在application和zlibrary两个文件夹里面。

我们来看一下读取的xml格式的资源文件的大致结构:

文件都是有不同层级的node标签组成的。
现在,我们继续解析流程。
ResourceTreeReader类startElementHandler方法、endElementHandler方法
我们之前有说过,readDocument方法中设置了myStack变量,之后所有的资源文件数据都会加载到myStack属性之中。注意,myStack变量其实就是一个ArrayList。
现在,我们不妨来模拟一下单步调试,看看myStack变量的变化。

假设,waiMessage是第一个节点,程序刚刚读到第一个节点。

代码读取到waitMessage节点开始标签右边的“>”时候,会触发ResourceTreeReader类中的startElementHandler方法。

此时,代码就会得到name的值(132行),但value为nul(135行),因为waitMessage的节点没有value的属性嘛。
接下来就是获得peek变量(137行)。请注意,myStack一开始是有加入一个root变量的。所以,myStack变量所指向ArrayList的是有一个元素的。这个元素相当于一个“根节点”,而此时我们就将获得这个“根节点”。

然后,程序将新建的HashMap赋值给了代表“根节点”的peek变量的myChildren的属性(144行),这就相当于为“根节点”增加一个空的“子节点”。然后代码又初始化了一个ZLTreeResource类(150行),这个类其实就代表了waitMessage的节点。接下来,代码将这个类赋值给了node变量,并将node加入到刚刚创建的HashMap(152行)。这样,就相当于waitMessage节点代替了空的“子节点”,成为了“根节点”的“子节点”了。最后,代码又将代表waitMessage节点的node加入了myStack变量所指向ArrayList里面(159行)。

继续往下,程序开始读取下面的downloadingFile节点开始标签右边的“>”的时候,同样的流程会再走一遍。与前一次的的区别是,程序这一次会直接获得刚刚被加入myStack变量所的指向ArrayList里面的代表waitMessage节点的node变量(137行),但此时代表waiMessage节点的peek变量的myChildren属性是null,这就代表底waitMessage节点下是没有任何“子节点”的。接着,代码初始化了一个children变量,也就是初始化了一个HashMap(142行),然后将代表downloadingFile节点的node加入了children变量所指向的HashMap里面,这就相当于给waiMessage节点加入一个空的“子节点”(144行)。此时,node被设置为null(141行),程序于是初始化一个空的node(150行),也就是初始化一个ZLTreeResource类,然后把downloadingFile节点的name、value信息赋给node变量所指向的ZLTreeResource类。接着,代表downloadingFile节点的node变量加入到了children变量指向的HashMap(152行),这就相当于downloadingFile节点代替了空的“子节点”,成为了waiMessage节点的“子节点”了。最后,与之前一样,代码又将代表downloadingFile节点的node变量加入了myStack变量所指向的ArrayList里面(160行)。
接下来,程序会读到代表downloadingFile节点结束标签里的“/”(代表waiMessage节点结束标签里的“/”一直要到这个节点里面的所有子节点全部被读取完毕后才会被读到),于是ResourceTreeReader类中的endElementHandler方法被调用。这个方法的作用就是将myStack变量里面所指向的ArrayList里的最后一个元素删除了。
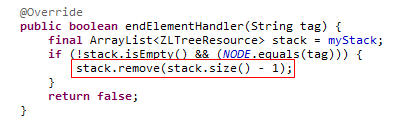
这个动作其实就是把刚刚加入myStack变量的代表downloadingFile节点的node变量删除了。删除这个节点的作用是什么呢?它的作用就是,当下一次再进入startElementHandler方法是,代码会从ArrayList中读出代表waitMessage节点的node,然后代表“子节点”的node就会加到这个node的myChildren属性里面。当waitMessage节点所有的子节点都读完的时候,waiMessage节点的结束斜杠就会触发endElementHandler方法,从而将代表waiMessage节点的node从myStack变量所指向的ArrayList里面删除。这样一来,waitMessage节点之后的节点就会被直接加到代表根节点的node的myChildren里面去,相当于与waitMessage节点一样成为根节点的子节点。
总结来说,startElementHandler方法里面的增加元素与endElementHandler方法中的删除元素配合起来就将xml文件里面的数据以一种层级式的结构读取到了内存里面。
Ok,资源文件已经被读取出来,并以层级结构存储在内存中了。接下来就从这个结构中寻找要在屏幕上要显示的字,其实就是loadingBook这个节点的值。

UIUtil类的wait方法会调用ZLTreeResource类getResource方法来获取这个节点的值

ZLTreeResource类getResource方法
现在回到ZLTreeResource类中的resource方法,现在我们已经从ZLTreeResource类的buildTree方法中跳出,开始对对根节点调用getResource方法,寻找匹配节点
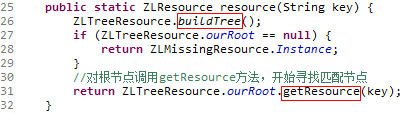
ZLTreeResource类getResource方法:这个方法其实就是一层一层找每个节点的子节点有没有想要的节点。其实,如果节点的名字都不重复的话,这里直接使用递归也是可以的。

ZLTreeResource类updateLanguage方法
最后,再补充下,默认的资源文件时uk.xml,程序是怎么知道我们的手机应该是使用zh.xml的中文资源文件呢?其实就是在ZLTreeResource类的updateLanguage方法。这个方法

好了,到这为止,第一个章节就结束了。在这个章节中,我们做的事情其实并不多,只是获得了加载书籍时,显示在屏幕上的字;但是在这个过程我们却已经接触了FBReader中几个非常核心的概念。我们现在再来回顾下这几个核心的概念。
- 第二章、解析资源文件
- Symbian 资源文件解析
- Symbian 资源文件解析
- Symbian 资源文件解析
- Symbian 资源文件解析
- Symbian 资源文件解析
- Symbian 资源文件解析
- Symbian 资源文件解析
- Symbian 资源文件解析 .
- MapleStory文件资源解析
- 第二十六章 配置包范围国际化资源文件
- 第二十七章 配置Action范围国际化资源文件
- properties 资源文件解析工具
- 解析properties资源文件(转载)
- 解析Qt资源文件使用
- 第二章 PX4-Pixhawk-RCS启动文件解析
- 第二章 PX4-Pixhawk-RCS启动文件解析
- 第二章 URL与资源
- 909422229__2、希尔排序(也称最小增量排序)程序员必须知道的8大排序和3大查找
- RS-485收发的零延时自动转换电路(转)
- python 正则表达式re.findall
- LIGHT OJ 1136 - Division by 3【找规律】
- 伸展树(Splay tree)学习小结
- 第二章、解析资源文件
- enctype="multipart/form-data"
- 归并排序
- 909422229__3、简单选择排序
- SystemCallStub与KiFastSystemCall的关系
- openstack学习资源与学习路线
- on_each_cpu_cond
- urlretrieve方法的使用
- Python的GIL是什么鬼,多线程性能究竟如何


