Cassandra 故障探测原理--Accrual Failure Detector
来源:互联网 发布:linux file命令 编辑:程序博客网 时间:2024/05/19 18:45
背景
众所周知,故障探测(failure detector)是分布式系统的基础模块,用于探测各种服务(数据库、缓存)、节点(主机、云主机、容器)、进程等服务的状态。在分布式环境下应用需要调整故障检测以适用于不同的QOS需求,而传统的故障探测算法只能提供bool结果对探测进行决断。传统的探测方法主要通过周期心跳Heartbeat和超时时间Timout来处理,当在固定timeout时间内没有收到心跳则断定该节点失效并进行相关逻辑处理。那问题出来了:这个timeout设置为多久呢?timeout跟heartbeat的关系如何?不同环境下网络等都可能不同(如局域网内通信、异地数据中心通信、跨机房),如何在不同环境下对timeout进行设置呢?心跳信号过短是不是会造成网络拥塞?
来来来,看如何解决上述问题:Accrual Failure Detector是日本的学着Naohiro Hayashibara等人提出的失败探测算法,国内暂时对该算法没有很好的中文定义,从其实现来看暂且定义为:累积型失败探测(对历史数据进行累积与分析),本文就是在对该算法的理解上并针对Cassnadra的实现进行了分析,如有纰漏之处,求指正。
Accrual failure detector(累积型失败探测)的创新在于:产生结果是被监测的节点或服务失效(crash)的置信度(the degree of confidence),置信度是随着时间变化的连续的值。累积型失败探测通过一个固定大小窗口(WS)存储收到心跳信号的间隔时间,通过这个窗口对心跳信号均值及方差进行分析,生成一个置信度。分布式应用可以根据自身的QOS需求定义适合自己的suspicion threshold(可信度阈值),定义一个较低的threshold会导致探测到一个real creash时间短,但是其正确性不高;定义一个较高的 threshold会导致特测到real crash的时间长,但是其正确性高。
Accrual Failure Detector应用举 例。在一个分布式系统中,有一个master server和多个worker server, master server需要把很多job分发到worker server上。很显然,master server需要探测worker server的状态。利用Accrual failuer detector,当某个worker server的置信度达到low threshold时,master server不向此worker server派发新的job;当置信度达到moderate threshold时,master server会把在此woker server上的job派发到其它的worker server;当置信度达到high threshold,master server会把释放关于此worker server的通信资源(比如关闭socket)。
failure detector基本概念
定义:q表示探测服务、p表示被探测服务,通过q来探测p的状态
■基本概念之一:Unreliable failure detectors
failure detectors是不可靠的,原因是crash server很难与 slow server区分。
■基本概念之二:Quality of service of failure detectors
定义1 (Detection time TD):探测时间是指被检测服务p crash后直到q探测到P crash这段时间
定义2 (Average mistake rate _M): 探测出错率
■探测方法一:Heartbeat failure detectors
q监控p,p会定期的向q发送心跳,发送心跳的间隔记为△i。q在△to时间内没有收到新的心跳,则认为p已经crash。△tr定义为消息在网路上传输的时延。
第一个方案,把△to(Timeout 超时时间)设定为一个固定的值。缺点:当△to设置的过低时,crash很快会被检测到,但是结果的正确性不高。反之,crash被检测到时间长,但正确性高。
第二个方案,根据心跳的网络时延△tr (不同的网络环境下网络时延肯定不同,比如从杭州到帝都北京的网络时延肯定比中国到山姆大叔纽约的时延小)和 心跳发送间隔△i 来确定△to。缺点:需要依赖△i,因为不能保证发送心跳的规律性以及短间隔的时间导致不准确,同时操作系统的调度也会影响这个时间。
■探测方法二:Adaptive failure detectors
该方法能够自适应网络的变化,在心跳周期不变的情况下随着网络状况不断的变化,△to也会随着变化。Chen-FD提出一种算法,根据最近一段时间收到心跳的间隔来预测收到下个心跳的时间的边界值,△to根据这个预测时间计算一次(只会一次)。作者提供了2个版本的协议:基于同步时钟和基于异步时钟的。 Bertier-FD也提出一种算法基本与上相同,不同的是在Chen的算法的基础上增加了round-trip time(网络往返时间)的考虑。测试表明:Bertier-FD 算法比 Chen-FD算法 更快的检测到crash,但是其正确性降低了。
在上述两种探测方法中如何确定心跳发送间隔△i 一直都是焦点所在。 从常识来看,△i应该由应用自己的需求来确定。但是△i不能单纯的根据自己的需求来确定,很多学着认为其应该由下层的系统(网络,OS)来确定,如果△i远远小于△tr,故障特测时间由 △tr确定,减小△i不会减少故障特测时间,相反还会增加网络拥塞,从而增加△tr,进而增加故障探测时间;如果△i远远大于△tr,故障特测时间由△i 确定,增加△i会增大故障特测时间,且不会明显的减少网络负载。所以△i应该与平均△tr相当。
传统失败探测和accrual failure detector对比:
传统失败探测和累积型失败探测(accrual failure detector)进行比较,左边为传统型探测方法,所有的应用都依赖于一个解释器和探测器,这样就相当于针对不同的应用采用一刀切的方式决定其状态,而累积型失败探测(accrual failure detector)中解释器和探测器是分割的,每个应用可以实现自己的解释器,两者通过suspicion level进行连接,从而实现不同的应用可以设置不同的节点失败可疑级别实现自己的个性化策略。

Accrual failure detector原理:
server q 探测 p,输出值由如下函数表示,suspiction level of p 表示p crash的怀疑级别。

此函数必须满足如下属性:
1、如果p已经crash,值随着t趋近与无穷大。
2、如果p已经crash,存在一个时间段,此时间段后,其值是单调递增的。
3、如果p是alive,值有一个上限(upper bound)。
4、如果p是alive,存在一个时间段,此时间段后,其值为0。
Accrual failure detector实现
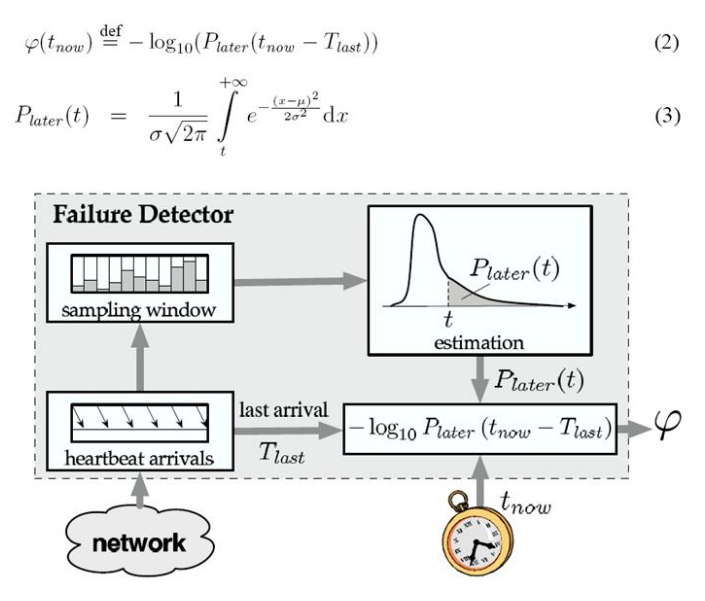
设计一个队列,存储收到心跳的间隔,队列的大小是一个固定值(称为window size),当收到新的心跳后,计算时间间隔并写入队列,删除队首的元素。μ表示队列中的时间间隔的平均值,σ表示标准差。其中μ和σ会随着心跳间隔队列的变化而动态变化。通过对这段固定窗口的历史心跳数据进行分析,实现累积型失败探测,该方法摆脱了△tr、△i、△to对算法的影响。具体公式如下公式(2)、(3)所示:
Plater(t) 表示在大于时间t内收到心跳信号的概率,通过对心跳信号进行采集与分析,心跳信号是满足正态分布分布的。在一个较网络环境中收到心跳信号的概率满足正态分布的三个特征:
1、集中性:正态曲线的高峰位于正中央,即均数所在的位置,在一个较稳定的网络环境下△i是有聚集性的
2、对称性:正态曲线以均数为中心,左右对称,曲线两端永远不与横轴相交,△i满足该性质
3、均匀变动性:正态曲线由均数所在处开始,分别向左右两侧逐渐均匀下降,△i满足该性质
Tlast:表示最后一次收到心跳的时间;
tnow:表示当前时间;
?(tnow)公式二:表示当前时间某个节点失败怀疑级别,怀疑级别越高,表示当前节点越可能crash,所以当怀疑级别设置的太小的话会导致出错率提高。该函数目的就是通过把概率小数转化成整数级别,方便处理,把小数区间转化到整数区间。
Plater(t)公式三:直接积分会较麻烦,但通过数学公式可知,其可以转化为1-F(t)其中F(t)是(μ,σ)的正态函数
cassandra 中的故障探测
cassandara使用的此论文中的方法来进行故障探测。在cassandra中该实现主要在org.apache.cassandra.gms的FailureDetector类中,windows size设置为1000, threshold设为8,当φ值大于8时,则认为此节点crash。不过,计算算法有所简化:
该方法忽略了方差的变化,简化计算,减少计算量,否则需要每次计算方差。FailureDetector中存储了每个节点的心跳数据:private Map<EndPoint, ArrivalWindow> arrivalSamples_ = new Hashtable<EndPoint, ArrivalWindow>(),通过hashtable保存每个节点的时间窗口,同时保证线程安全。
ArrivalWindow内部通过一个BoundedStatsDeque实现了容量大小为1000的队列,该类实现ArrayDeque<Double> deque。

//cassandra 自己的解释器,如果超过设置的 phiSuspectThreshold_则判断为节点down,在yaml.xml中可以设置怀疑级别阈值phi_convict_threashold(部分国内文章解释成时间设置,错误的)

//计算Plater(t)

//计算?(tnow):

//后续会继续研究cassandra的内部相关实现机制,敬请期待。
- Cassandra 故障探测原理--Accrual Failure Detector
- Accrual Failure Detector
- Accrual Swap
- Cassandra失效检测原理
- Cassandra原理介绍
- cassandra 存储原理
- 【Cassandra】数据存储原理
- Cassandra二级索引原理
- Visual Leak Detector工作原理
- Visual Leak Detector工作原理
- nmap端口探测原理初探
- 文件句柄分配的原理探测(一)---初步探测
- Harris Corner Detector 原理及编程实现
- Harris Corner Detector 原理及编程实现
- Harris Corner Detector 原理及编程实现
- Harris Corner Detector 原理及编程实现
- Cassandra 卓越点 写操作 单点故障 读操作缓慢
- Accrual Swap/Rate/Bond
- (11)Struts2_result概述
- 基于SignalR的小型IM系统
- 实现多行多列的RadioButton同时自由调整每行显示数量和上下间距
- ORA-56705: I/O calibration already in progress的解决方法
- HTML 5 属性
- Cassandra 故障探测原理--Accrual Failure Detector
- 堆排序
- 虚拟机 Kali的网络连不上?
- 封装HTTPRequestSerializer 的知识(一)
- 关于HBase协处理器导致问题的研究
- 使用 AngularJS 的路由和模板实现单页应用 (Single Page)
- 多媒体应用练习---照相机开发
- 通过文件分类实现程序内敛
- 关于一些css属性在微信上不兼容的解决方法


