递归详解
来源:互联网 发布:阿里私有云 编辑:程序博客网 时间:2024/06/06 05:17
博主大二在学习二叉树的时候,经常遇到递归相关的算法,一知半解、强行记忆。网上关于递归的文章不少,但是一般都是关于斐波拉切数列、数乘、汉诺塔等问题上,过于具体,直接给代码,缺少了思想,换个问题我就没法活学活用了。
网上看到篇文章,js递归实现阶乘,直接调用
n*f(n-1);
而没有
return n*f(n-1);
作者经历种种蛋疼终于找出问题得到答案时,怪罪js编译器,而没有发现自己递归理解不到位,生搬硬套代码,怨不得IDE。
博主很菜,但是不能接受自己太水,所以专门花心思把递归理解一番,在这里做个总结,和大家分享。
本文要感谢算法中的递归分析和分治法的原理、递归算法详解、Recursion and the Return Keyword和《编程之美》,书中的例子,让我对算法在实际中的应用有了更直观的理解。
本文分这么几个部分:
- 什么是递归?
- 递归解决什么样的问题?
- 递归的调用流程是什么?
1.什么是递归
递归:在函数或子过程的内部,直接或间接地调用自己的算法。
递归算法解决问题的特点:
- 递归就是在过程或函数里调用自身。
- 在使用递归策略时,必须有一个明确的递归结束条件,称为递归出口。
- 递归算法解题通常显得很简洁,但递归算法解题的运行效率较低。所以一般不提倡用递归算法设计程序。
- 在递归调用的过程当中系统为每一层的返回点、局部量等开辟了栈来存储,递归次数过多容易造成栈溢出等。所以一般不提倡用递归算法设计程序。
虽说从栈溢出和运行效率考虑,不提倡递归设计程序,但是由于递归程序代码清晰、简洁,值得我们好好学习。
2.递归解决的问题
递归算法所体现的“调用自己”的情况一般有三个要求:
- 每次调用在规模上都有所缩小(通常是减半);
- 相邻两次重复之间有紧密的联系,前一次要为后一次做准备(通常前一次的输出就作为后一次的输入);
- 在问题的规模极小时必须用直接给出解答而不再进行递归调用,因而每次递归调用都是有条件的(以规模未达到直接解答的大小为条件),无条件递归调用将会成为死循环而不能正常结束。
在解决问题的规模上,每次要缩小,这和分治法的思想很像,分治法一般来说分为三个阶段:
- 划分:把问题规模为n的原问题划分为k个规模较小的子问题,并尽量使这k个字问题规模相等。
- 求解子问题,子问题经常与原问题解法相同
- 把各个子问题的解合并起来
可见在原问题和子问题求解时,可以使用递归函数完成套路。我们常见的二分排序等都可以用递归函数解决。有时候,编写递归程序时确实难以获得更简单的子问题。 不过,使用归纳定义的数据集可以清楚划分出数据集。比如:树、链表等。
说了这么多,大家应该对递归多少有点概念了。具体的例子,比如数乘我这儿就不举例了。我想大家对递归迷茫的不是简单的使用,而是递归具体的执行流程是怎样的,这样在遇到具体问题的时候才清楚到底该如何调适bug、解决问题。
3.递归的调用流程
简单来说,递归函数的调用流程可以用下面这幅图表示,从主函数入口开始执行,嵌套调用子函数直至退出条件满足,从最里面一层的子函数不断向外返回。 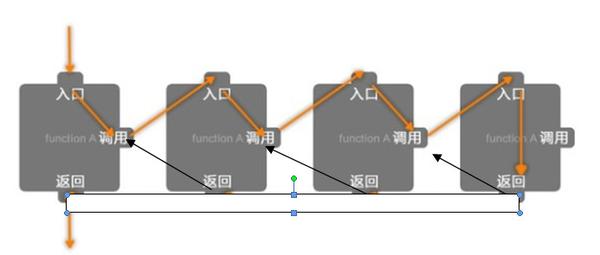
举个例子:
public class Recursion{public static void main(String[] args){ up_and_down(1);//调用递归函数 return 0;}void static up_and_down(int n){ if (n < 4) { up_and_down(n + 1); }}}对这样一个极其简单的程序,我们看下它的调用过程,up_and_down(1)->up_and_down(2)->up_and_down(3)->up_and_down(4),这时候n==4,不满足n<4的要求,压入栈的这四个函数从栈顶开始出栈返回。
但是我们平时使用递归显然不会这么简单,经常是执行回调函数的前后句都有代码,我们把这个例子再复杂一下。
public class Recursion{public static void main(String[] args){ up_and_down(1);//调用递归函数 return 0;}void static up_and_down(int n){ System.out.println("front: "+n); if (n < 4) { up_and_down(n + 1); } System.out.println("end: "+n);}}效果如图: 
结合上面的流程图,明白了没?up_and_down(1)内部调用up_and_down(2)之前执行了
System.out.println(“front: “+n);//此时n==2
然后同理调用up_and_down(3)和up_and_down(4)。up_and_down(4)执行到
if (n < 4){
up_and_down(n + 1);
}
不符合继续递归的条件,up_and_down(4)执行
System.out.println(“end: “+n);//n==4
会开始返回up_and_down(3),执行
System.out.println(“end: “+n);//n==3
依次类推,执行完
System.out.println(“end: “+n);//n==1
后,main函数退出,程序执行完毕。递归嵌套的过程如图所示: 
注意,该图仅仅表示递归时子函数和父函数的嵌套执行关系,实际存储是栈的形式保存了每一次递归的函数。
递归函数自己一层层地往深处调用自己,然后一层层返回,每到一层,就执行接下来的语句(故调用开始的地址和返回的地址一样),每一级递归都是用自己的局部变量。这样子,函数逐步往深调用然后逐步返回直到main函数。
说完递归函数具体的嵌套逻辑,再说下开篇的时候提到的return的问题。自己写过递归的同学可能多少有这样的感觉:有的时候return recursion();有的时候直接recursion();这两种有什么区别呢?或者说什么时候return,什么时候不return呢?比如上文给的例子就没有return,但是在阶乘的时候,代码一般是这样的:
int f(int n){ if(n==1){ return 1; }else{ return n*f(n-1); }}return在递归函数中起什么样的作用呢?不管是否在递归函数中,return 的作用都是从当前函数中退出,并将响应的结果赋值给某变量(如果有的话)。我们先分析阶乘:n!=n*(n-1)!,n>1;1!==1,用函数f(n)表示n!的话,可以表达为:f(n)=n*f(n-1),n>1;f(1)=1。也就是说,要求(n),可以由f(n-1)得到,于是我去计算f(n-1),同理递推求到f(1),只要知道f(1),就可以一路计算到f(n)。而return的作用就很明显了,把f(n-1)的值返回给f(n)=f(n-1)*n使用。还记得我们说分治法的第三步吗?合并子问题的解,return就可以理解成合并子问题的解。如果还不明白,我们换个写法来看。
int f(int n){ if(n==1){ return 1; }else{ int result=f(n-1)*n; return result; }}还记得我们上文分析的递归嵌套结构图吗?
int result=f(n-1)*n;// *n操作也是在返回的时候开始执行,从1开始返回,然后 *2,结果存放到result
return result;//返回result给父函数,当前递归函数退出。
结合图大家能否构思出来从f(4)开始的执行流程呢?想必很简单,博主就不画了。
分析了递归的嵌套以及return的作用,可能觉得举的例子太简单了,不清楚自己到底理解了没,我们换个二叉树的例子,带大家理一遍。
二叉树的中序遍历,递归的实现只有四行核心代码,我们就分析这个。其他的例子代码偏长,相信有中序做例子,大家能自己看懂。
void inOrder(BiTree bt){ if(bt!=NULL){ inOrder(bt->lchild); cout<<bt->data<<endl; inOrder(bt->rchild); }}中序遍历就是先访问左子树,再访问跟根节点,最后访问右子树。左、右子树的访问顺序同上,明显的递归,可能从设计上我们能理解这个写法,但是我们知道为什么这么写就可以保证每颗子树先访问左,再访问根,最后访问右呢?
我们借助一个简单的二叉树分析: 
先访问1,不为空,递归1的左孩子2,不为空,递归2的左孩子4,不为空,递归4的左孩子,为空,回退,执行cout 4,4的右孩子为空,回退,4回退到2,执行cout 2,2的右孩子为5,5的左孩子为空,回退,执行cout 5,右孩子为空,回退,结点5回退,结点2回退到1,1的右孩子3,左孩子为空,回退,执行cout 3,3的右孩子空,回退,3回退到1,递归函数退出。 
这么一分析,大家能体会到上述三行代码的含义了吗?递归左子树,返回的时候输出根结点,再递归右子树,返回的条件是结点为空。每一次递归函数完成的都是对一个结点的左子树、自身、右子树的完整访问。对于二叉树这种由递归定义出来的数据结构,几乎都可以用递归实现处理。
分享下《编程之美》作者总结的递归问题三体会:
- 先弄清楚递归的顺序,递归的实现中往往要假设后续的调用已经完成。(比如说,中序的时候就是假设子树的中序遍历已经完成,后面就可以进行子树的根结点的遍历)
- 分析清楚递归体的逻辑,然后写出来。(比如说,中序的时候逻辑就是左子树访问完了之后,结点输出,再访问右子树)
- 考虑清楚递归退出的条件。(可借助return或者条件判断)
总结
说了这么多,大家对递归的流程应该有了进一步的了解,分享一个链接http://stackoverflow.com/questions/2247063/need-help-in-returning-from-a-recursive-method,借助这道题,再让自己练练手吧。
很惭愧,做了一点微小的贡献!
- 递归详解
- 递归详解
- 递归详解
- 递归详解
- 递归详解
- 递归详解
- 递归详解
- 递归详解
- 递归详解
- 递归与尾递归详解
- 递归和非递归详解
- 递归 与 尾递归 详解
- 汉诺塔的递归详解
- 递归算法详解-
- 递归算法详解
- java 递归详解
- 汉诺塔问题详解 (递归)
- 函数递归调用详解
- 【python】 计算向量欧氏距离的小代码 numpy
- char和varchar的区别
- ScrollView上添加多个ViewController
- C++11创建一个跨平台线程池
- 怎么找到苹果App Store的应用程序下载链接地址
- 递归详解
- 测试人员绩效评价方法
- Idea 或eclipse报错: appears to be part of Subversion 1.7 (SVNKit 1.4) or greater
- 如何随机破解一个家用路由器
- Navicat for Oracle 11g 解决ORA-28547问题
- 适配ListView的几种常见Adapter的用法总结
- iOS-UITableView的两种重用Cell方法的区别(dequeueReusableCellWithIdentifier)
- 九度题目1149:子串计算
- 存疑惑以及面经中的问题汇总


