12-Thread Control
来源:互联网 发布:腾牛网怎么下载软件 编辑:程序博客网 时间:2024/06/13 04:10
Please indicate the source: http://blog.csdn.net/gaoxiangnumber1
Welcome to my github: https://github.com/gaoxiangnumber1
12.1 Introduction
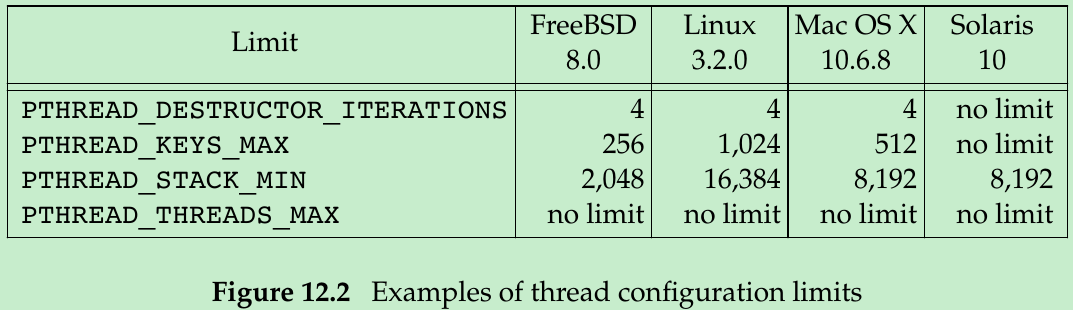
12.2 Thread Limits

12.3 Thread Attributes
- The functions for managing attributes of threads and synchronization objects follow the same pattern:
- Each object is associated with its own type of attribute object(threads with thread attributes, mutexes with mutex attributes, and so on). An attribute object can represent multiple attributes. The attribute object is opaque to applications. This means that applications aren’t supposed to know anything about its internal structure, which promotes application portability. Instead, functions are provided to manage the attributes objects.
- An initialization function exists to set the attributes to their default values.
- Another function exists to destroy the attributes object. If the initialization function allocated any resources associated with the attributes object, the destroy function frees those resources.
- Each attribute has a function to get the value of the attribute from the attribute object. Because the function returns 0 on success or an error number on failure, the value is returned to the caller by storing it in the memory location specified by one of the arguments.
- Each attribute has a function to set the value of the attribute. In this case, the value is passed as an argument by value.
- We use pthread_attr_t structure to modify the default attributes, and associate these attributes with threads that we create.
#include <pthread.h>int pthread_attr_init (pthread_attr_t *attr);int pthread_attr_destroy(pthread_attr_t *attr);Both return: 0 if OK, error number on failure- We use pthread_attr_init to initialize the pthread_attr_t structure. After calling pthread_attr_init, the pthread_attr_t structure contains the default values for all the thread attributes supported by the implementation.
- We call pthread_attr_destroy to deinitialize a pthread_attr_t structure. If pthread_attr_init allocated any dynamic memory for the attribute object, pthread_attr_destroy will free that memory. In addition, pthread_attr_destroy will initialize the attribute object with invalid values, so if it is used by mistake, pthread_create will return an error code.

- The thread attributes defined by POSIX.1 are summarized in Figure 12.3.
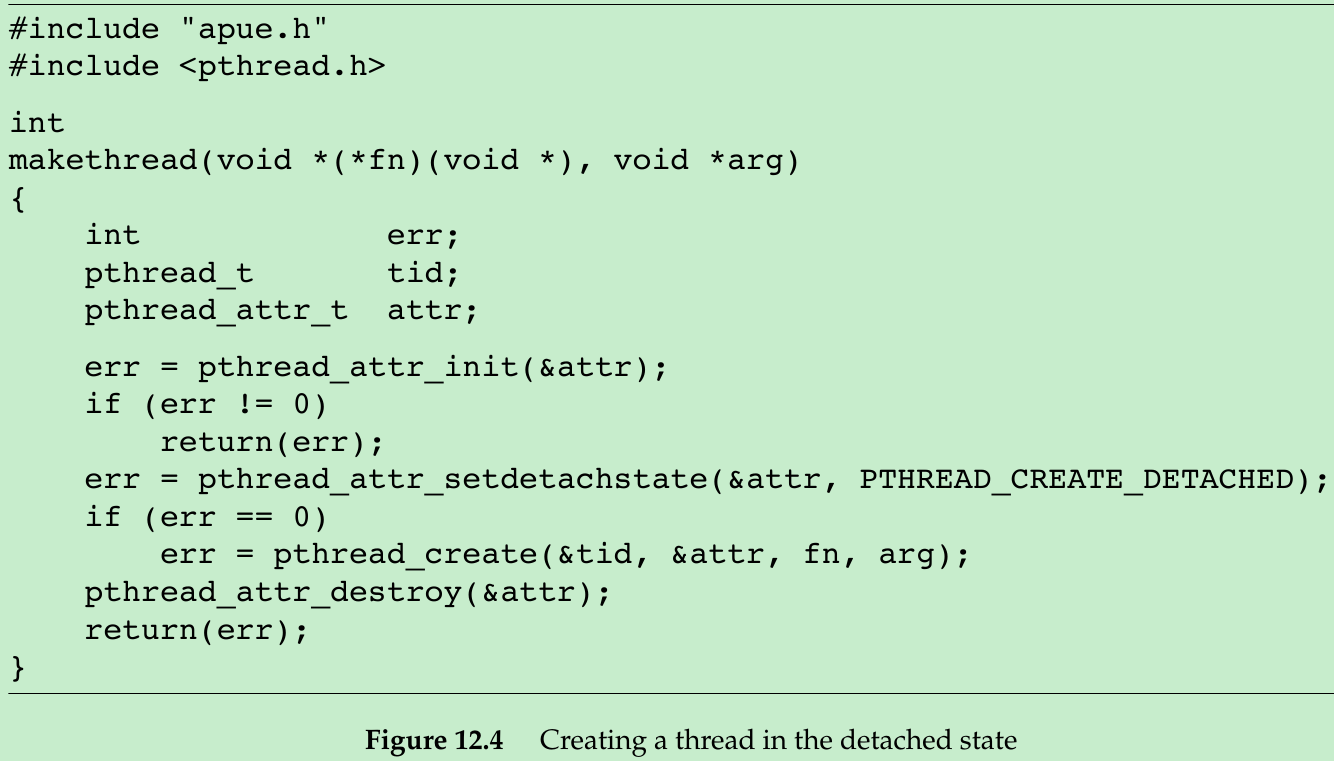
- If we aren’t interested in an existing thread’s termination status, we can use pthread_detach to allow the operating system to reclaim the thread’s resources when the thread exits. If we know that we don’t need the thread’s termination status at the time we create the thread, we can make the thread to start out in the detached state by modifying the detachstate thread attribute in the pthread_attr_t structure.
#include <pthread.h>int pthread_attr_getdetachstate(const pthread_attr_t *restrict attr, int *detachstate);int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);Both return: 0 if OK, error number on failure- We can use pthread_attr_setdetachstate to set the detachstate thread attribute to one of two legal values:
- PTHREAD_CREATE_DETACHED to start the thread in the detached state;
- PTHREAD_CREATE_JOINABLE to start the thread normally, so its termination status can be retrieved by the application.
- We call pthread_attr_getdetachstate to obtain the current detachstate attribute. “detachstate” is set to either PTHREAD_CREATE_DETACHED or PTHREAD_CREATE_JOINABLE, depending on the value of the attribute in the given pthread_attr_t structure.
- We ignore the return value from the call to pthread_attr_destroy. If it does fail, cleaning up would be difficult: we would have to destroy the thread we just created, which might already be running, asynchronous to the execution of this function. When we choose to ignore the error return from pthread_attr_destroy, the worst is that we leak a small amount of memory if pthread_attr_init had allocated any. But if pthread_attr_init succeeded in initializing the thread attributes and then pthread_attr_destroy failed to clean up, we have no recovery strategy anyway, because the attributes structure is opaque to the application.
- At compile time, you can check whether your system supports each thread stack attribute by using the _POSIX_THREAD_ATTR_STACKADDR and _POSIX_THREAD_ATTR_STACKSIZE symbols. If one of these symbols is defined, then the system supports the corresponding thread stack attribute. Alternatively, you can check for support at runtime, by using the _SC_THREAD_ATTR_STACKADDR and _SC_THREAD_ATTR_STACKSIZE parameters to the sysconf function.
- With a process, the amount of virtual address space is fixed. With threads, the same amount of virtual address space must be shared by all the thread stacks.
- Reduce default thread stack size if your application uses so many threads that the cumulative size of their stacks exceeds the available virtual address space.
- Increase * if your threads call functions that allocate large automatic variables or call functions many stack frames deep.
- If you run out of virtual address space for thread stacks, you can use malloc or mmap (Section 14.8) to allocate space for an alternative stack and use pthread_attr_setstack to change the stack location of threads you create.
#include <pthread.h>int pthread_attr_getstack(const pthread_attr_t *restrict attr, void **restrict stackaddr, size_t *restrict stacksize);int pthread_attr_setstack(pthread_attr_t *attr, void *stackaddr, size_t stacksize);Both return: 0 if OK, error number on failure- The address specified by
stackaddris the lowest addressable address in the range of memory to be used as the thread’s stack, aligned at the proper boundary for the processor architecture. This assumes that the virtual address range used by malloc or mmap is different from the range currently in use for a thread’s stack. - The stackaddr thread attribute is defined as the lowest memory address for the stack. This is not necessarily the start of the stack. If stacks grow from higher addresses to lower addresses for a given processor architecture, the stackaddr thread attribute will be the end of the stack instead of the beginning.
#include <pthread.h>int pthread_attr_getstacksize(const pthread_attr_t *restrict attr, size_t *restrict stacksize);int pthread_attr_setstacksize(pthread_attr_t *attr, size_t stacksize);Both return: 0 if OK, error number on failure- pthread_attr_setstacksize is useful when you want to change the default stack size but don’t want to deal with allocating the thread stacks on your own. When setting the stacksize attribute, the size we choose can’t be smaller than PTHREAD_STACK_MIN.
- The guardsize thread attribute controls the size of the memory extent after the end of the thread’s stack to protect against stack overflow. Its default value is implementation defined, but a commonly used value is the system page size.
- We can set the guardsize thread attribute to 0 to disable this feature: no guard buffer will be provided in this case. If we change the stackaddr thread attribute, the system assumes that we will be managing our own stacks and disables stack guard buffers, just as if we had set the guardsize thread attribute to 0.
#include <pthread.h>int pthread_attr_getguardsize(const pthread_attr_t *restrict attr, size_t *restrict guardsize);int pthread_attr_setguardsize(pthread_attr_t *attr, size_t guardsize);Both return: 0 if OK, error number on failure- If the guardsize thread attribute is modified, the operating system might round it up to an integral multiple of the page size. If the thread’s stack pointer overflows into the guard area, the application will receive an error, possibly with a signal.
- Threads have other attributes not represented by the pthread_attr_t structure: the cancelability state and the cancelability type(Section 12.7).
12.4 Synchronization Attributes
12.4.1 Mutex Attributes
- Mutex attributes are represented by a pthread_mutexattr_t structure. When we initialized a mutex, we accepted the default attributes by using the PTHREAD_MUTEX_INITIALIZER constant or by calling pthread_mutex_init with a null pointer for the argument that points to the mutex attribute structure.
#include <pthread.h>int pthread_mutexattr_init(pthread_mutexattr_t *attr);int pthread_mutexattr_destroy(pthread_mutexattr_t *attr);Both return: 0 if OK, error number on failure- pthread_mutexattr_init will initialize the pthread_mutexattr_t structure with the default mutex attributes.
- There are three attributes of interest: the process-shared attribute, the robust attribute, and the type attribute.
- Within POSIX.1, the process-shared attribute is optional; you can test whether a platform supports it by checking whether the _POSIX_THREAD_PROCESS_SHARED symbol is defined. You can also check at runtime by passing the _SC_THREAD_PROCESS_SHARED parameter to the sysconf function.
- Within a process, multiple threads can access the same synchronization object. This is the default behavior. In this case, the process-shared mutex attribute is set to PTHREAD_PROCESS_PRIVATE.
- Chapters 14 and 15: mechanisms exist that allow independent processes to map the same extent of memory into their independent address spaces. If the process-shared mutex attribute is set to PTHREAD_PROCESS_SHARED, a mutex allocated from a memory extent shared between multiple processes may be used for synchronization by those processes.
#include <pthread.h>int pthread_mutexattr_getpshared(const pthread_mutexattr_t *restrict attr, int *restrict pshared);int pthread_mutexattr_setpshared(pthread_mutexattr_t *attr, int pshared);Both return: 0 if OK, error number on failure- We can use pthread_mutexattr_getpshared to query a pthread_mutexattr_t structure for its process-shared attribute. We can change the process-shared attribute with pthread_mutexattr_setpshared.
- The process-shared mutex attribute allows the pthread library to provide more efficient mutex implementations when the attribute is set to PTHREAD_PROCESS_PRIVATE, which is the default case with multithreaded applications. The pthread library can then restrict the more expensive implementation to the case in which mutexes are shared among processes.
- The robust mutex attribute is related to mutexes that are shared among multiple processes. It is meant to address the problem of mutex state recovery when a process terminates while holding a mutex. When this happens, the mutex is left in a locked state and recovery is difficult. Threads blocked on the lock in other processes will block indefinitely.
#include <pthread.h>int pthread_mutexattr_getrobust(const pthread_mutexattr_t *restrict attr, int *restrict robust);int pthread_mutexattr_setrobust(pthread_mutexattr_t *attr, int robust);Both return: 0 if OK, error number on failure- We can use pthread_mutexattr_getrobust to get the value of the robust mutex attribute. To set the value of the robust mutex attribute, we can call pthread_mutexattr_setrobust.
- There are two possible values for the robust attribute.
- The default is PTHREAD_MUTEX_STALLED, which means that no special action is taken when a process terminates while holding a mutex. In this case, use of the mutex can result in undefined behavior, and applications waiting for it to be unlocked are effectively stalled.
- The other is PTHREAD_MUTEX_ROBUST. This value will cause a thread blocked in a call to pthread_mutex_lock to acquire the lock when another process holding the lock terminates without first unlocking it, but the return value from pthread_mutex_lock is EOWNERDEAD instead of 0. Applications can use this return value as an indication that they need to recover whatever state the mutex was protecting.
- Using robust mutexes, we have to check for three return values instead of two: success with no recovery needed, success but recovery needed, and failure.
#include <pthread.h>int pthread_mutex_consistent(pthread_mutex_t * mutex);Returns: 0 if OK, error number on failure- If the application state can’t be recovered, the mutex will be in a permanently unusable state after the thread unlocks the mutex. To prevent this problem, the thread can call pthread_mutex_consistent to indicate that the state associated with the mutex is consistent before unlocking the mutex.
- If a thread unlocks a mutex without first calling pthread_mutex_consistent, then other threads that are blocked while trying to acquire the mutex will see error returns of ENOTRECOVERABLE. If this happens, the mutex is no longer usable. By calling pthread_mutex_consistent beforehand, a thread allows the mutex to behave normally, so it can continue to be used.
- The type mutex attribute controls the locking characteristics of the mutex. POSIX.1 defines four types:
- PTHREAD_MUTEX_NORMAL
A standard mutex type that doesn’t do any special error checking or deadlock detection. - PTHREAD_MUTEX_ERRORCHECK
A mutex type that provides error checking. - PTHREAD_MUTEX_RECURSIVE
A mutex type that allows the same thread to lock it multiple times without first unlocking it. A recursive mutex maintains a lock count and isn’t released until it is unlocked the same number of times it is locked. - PTHREAD_MUTEX_DEFAULT
A mutex type providing default characteristics and behavior. Implementations are free to map it to one of the other mutex types. Linux maps this type to the normal mutex type.
- PTHREAD_MUTEX_NORMAL

- The behavior of the four types is summarized in Figure 12.5.
“Unlock when not owned” column refers to one thread unlocking a mutex that was locked by a different thread.
“Unlock when unlocked” column refers to what happens when a thread unlocks a mutex that is already unlocked.
#include <pthread.h>int pthread_mutexattr_gettype(const pthread_mutexattr_t *restrict attr, int *restrict type);int pthread_mutexattr_settype(pthread_mutexattr_t *attr, int type);Both return: 0 if OK, error number on failure- We can use pthread_mutexattr_gettype to get the mutex type attribute. To change the attribute, we can use pthread_mutexattr_settype.
- Section 11.6.6: a mutex is used to protect the condition that is associated with a condition variable. Before blocking the thread, the pthread_cond_wait and the pthread_cond_timedwait functions release the mutex associated with the condition. This allows other threads to acquire the mutex, change the condition, release the mutex, and signal the condition variable. Since the mutex must be held to change the condition, it is not good to use a recursive mutex. If a recursive mutex is locked multiple times and used in a call to pthread_cond_wait, the condition can never be satisfied, because the unlock done by pthread_cond_wait doesn’t release the mutex.
- Recursive mutexes are useful when you need to adapt existing single-threaded interfaces to a multithreaded environment, but can’t change the interfaces to your functions because of compatibility constraints. Recursive locks should be used only when no other solution is possible.
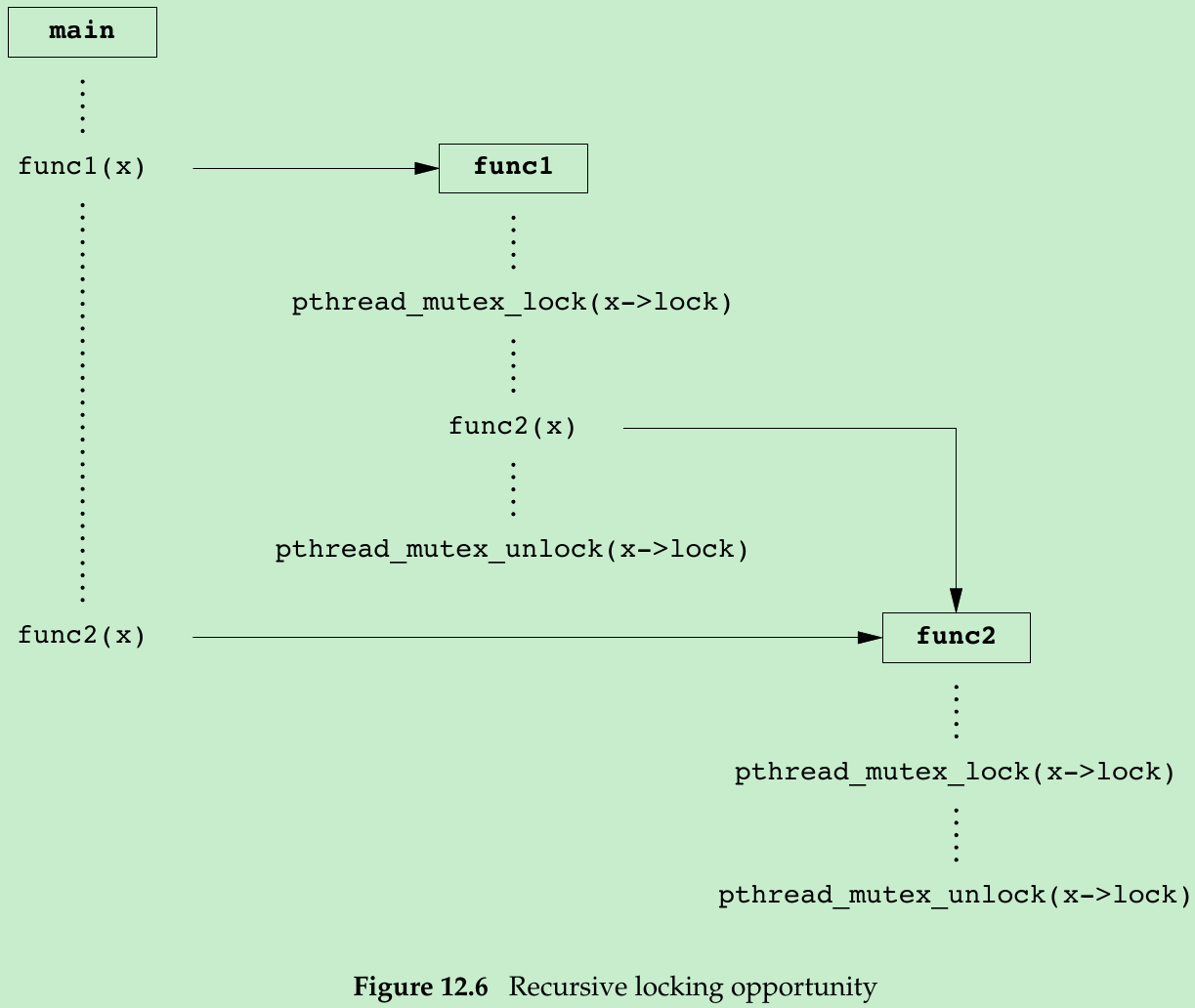
- Assume that func1 and func2 are existing functions in a library whose interfaces can’t be changed. Figure 12.6 illustrates a situation in which a recursive mutex solves a concurrency problem.
- To keep the interfaces the same, we embed a mutex in the data structure whose address(x) is passed in as an argument. This is possible only if we have provided an allocator function for the structure, so the application doesn’t know about its size (assuming we must increase its size when we add a mutex to it).
- If both func1 and func2 must manipulate the structure and it is possible to access it from more than one thread at a time, then func1 and func2 must lock the mutex before manipulating the structure. If func1 must call func2, we will deadlock if the mutex type is not recursive. We could avoid using a recursive mutex if we could release the mutex before calling func2 and reacquire it after func2 returns, but this approach opens a window where another thread can possibly grab control of the mutex and change the data structure in the middle of func1.
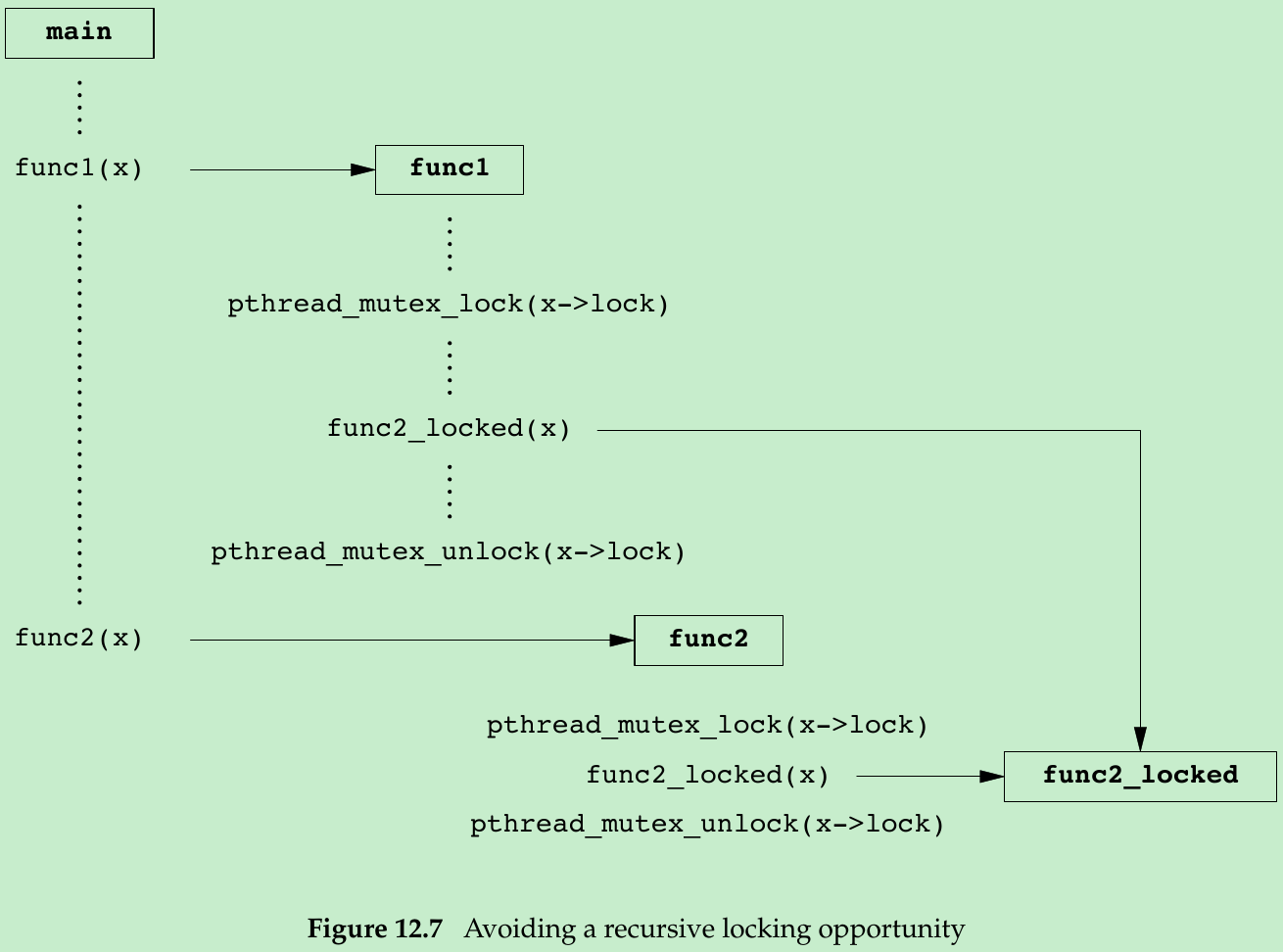
- Figure 12.7 shows an alternative to using a recursive mutex in this case. We can leave the interfaces to func1 and func2 unchanged and avoid a recursive mutex by providing a private version of func2, called func2_locked. To call func2_locked, we must hold the mutex embedded in the data structure whose address we pass as the argument. The body of func2_locked contains a copy of func2, and func2 now simply acquires the mutex, calls func2_locked, and then releases the mutex.
- If we didn’t have to leave the interfaces to the library functions unchanged, we could add a second parameter to each function to indicate whether the structure is locked by the caller.
- The strategy of providing locked and unlocked versions of functions is applicable in simple situations. In more complex situations, such as when the library needs to call a function outside the library, which then might call back into the library, we need to rely on recursive locks.




- The program in Figure 12.8 illustrates another situation in which a recursive mutex is necessary. We have a “timeout” function that allows us to schedule another function to be run at some time in the future. Assuming that threads are an inexpensive resource, we can create a thread for each pending timeout. The thread waits until the time has been reached, and then it calls the function we’ve requested.
- The problem arises when we can’t create a thread or when the scheduled time to run the function has already passed. In these cases, we call the requested function now, from the current context. Since the function acquires the same lock that we currently hold, a deadlock will occur unless the lock is recursive.
- We use the makethread function from Figure 12.4 to create a thread in the detached state. Because the func function argument passed to the timeout function will run in the future, we don’t want to wait around for the thread to complete.
- We could call sleep to wait for the timeout to expire, but that gives us only second granularity. If we want to wait for time other than an integral number of seconds, we need to use nanosleep or clock_nanosleep, both of which allow us to sleep at higher resolution.
- The caller of timeout needs to hold a mutex to check the condition and to schedule the retry function as an atomic operation. The retry function will try to lock the same mutex. Unless the mutex is recursive, a deadlock will occur if the timeout function calls retry directly.
12.4.2 Reader-Writer Lock Attributes
#include <pthread.h>int pthread_rwlockattr_init(pthread_rwlockattr_t *attr);int pthread_rwlockattr_destroy(pthread_rwlockattr_t *attr);Both return: 0 if OK, error number on failure- We use pthread_rwlockattr_init to initialize a pthread_rwlockattr_t structure and pthread_rwlockattr_destroy to deinitialize the structure.
- The only attribute supported for reader-writer locks is the process-shared attribute.
#include <pthread.h>int pthread_rwlockattr_getpshared(const pthread_rwlockattr_t * restrict attr, int *restrict pshared);int pthread_rwlockattr_setpshared(pthread_rwlockattr_t *attr, int pshared);Both return: 0 if OK, error number on failure12.4.3 Condition Variable Attributes
- The Single UNIX Specification defines two attributes for condition variables: the process-shared attribute and the clock attribute.
““c
include
- The process-shared attribute controls whether condition variables can be used by threads within a single process only or from within multiple processes.```c<div class="se-preview-section-delimiter"></div>#include <pthread.h>int pthread_condattr_getpshared(const pthread_condattr_t * restrict attr, int *restrict pshared);int pthread_condattr_setpshared(pthread_condattr_t *attr, int pshared);Both return: 0 if OK, error number on failure<div class="se-preview-section-delimiter"></div>- pthread_condattr_getpshared find the current value of the process-shared attribute; pthread_condattr_setpshared set its value.
- The clock attribute controls which clock is used when evaluating the timeout argument(tsptr) of pthread_cond_timedwait function. The legal values are the clock IDs listed in Figure 6.8.

<div class="se-preview-section-delimiter"></div>#include <pthread.h>int pthread_condattr_getclock(const pthread_condattr_t *restrict attr, clockid_t *restrict clock_id);int pthread_condattr_setclock(pthread_condattr_t *attr, clockid_t clock_id);Both return: 0 if OK, error number on failure<div class="se-preview-section-delimiter"></div>- We can use pthread_condattr_getclock to retrieve the clock ID that will be used by pthread_cond_timedwait for the condition variable that was initialized with the pthread_condattr_t object. We can change the clock ID with pthread_condattr_setclock.
12.4.4 Barrier Attributes
<div class="se-preview-section-delimiter"></div>#include <pthread.h>int pthread_barrierattr_init (pthread_barrierattr_t *attr);int pthread_barrierattr_destroy(pthread_barrierattr_t *attr);Both return: 0 if OK, error number on failure<div class="se-preview-section-delimiter"></div>- We can use pthread_barrierattr_init to initialize a barrier attributes object and pthread_barrierattr_destroy to deinitialize a barrier attributes object.
- The only barrier attribute is the process-shared attribute, which controls whether a barrier can be used by threads from multiple processes or only from within the process that initialized the barrier.
<div class="se-preview-section-delimiter"></div>#include <pthread.h>int pthread_barrierattr_getpshared(const pthread_barrierattr_t *restrict attr, int *restrict pshared);int pthread_barrierattr_setpshared(pthread_barrierattr_t *attr, int pshared);Both return: 0 if OK, error number on failure<div class="se-preview-section-delimiter"></div>- The value of the process-shared attribute can be:
- PTHREAD_PROCESS_SHARED(accessible to threads from multiple processes)
- PTHREAD_PROCESS_PRIVATE(accessible to only threads in the process that initialized the barrier).
12.5 Reentrancy
- Threads are similar to signal handlers when it comes to reentrancy(Section 10.6). In both cases, multiple threads of control can potentially call the same function at the same time.
- If a function can be safely called by multiple threads at the same time, we say that the function is thread-safe. All functions defined in the Single UNIX Specification are guaranteed to be thread-safe, except those listed in Figure 12.9.
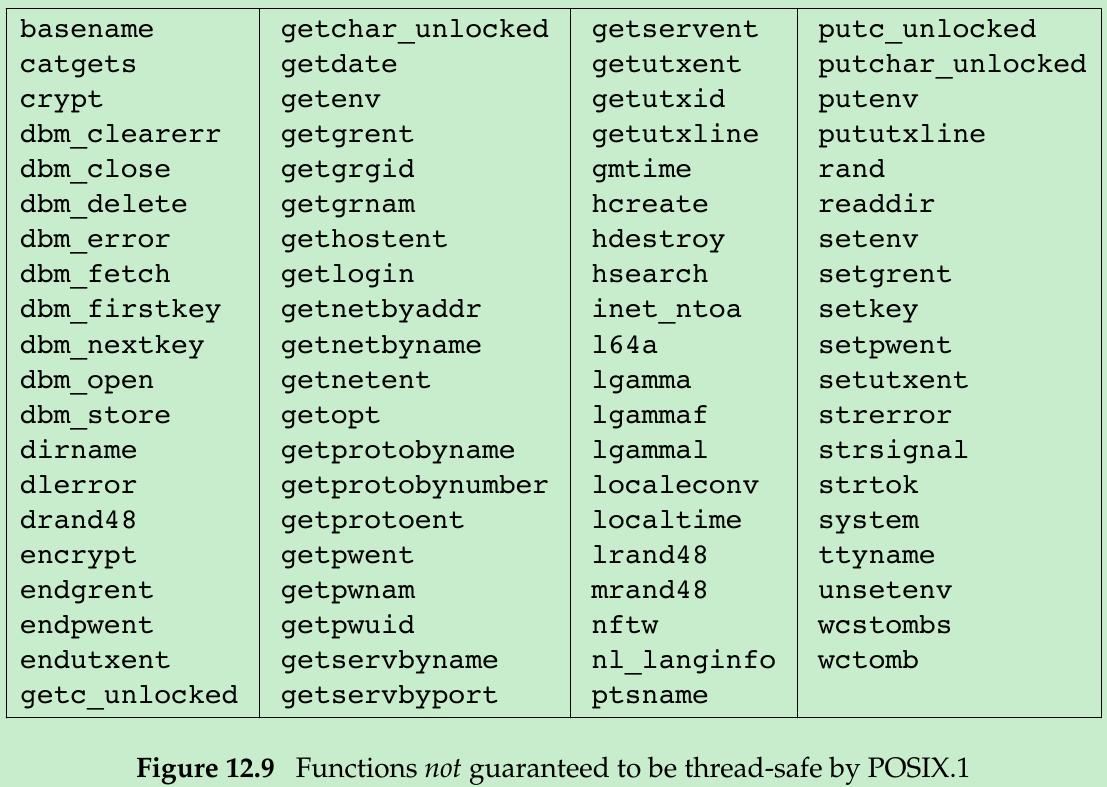
- The ctermid and tmpnam functions are not guaranteed to be thread-safe if they are passed a null pointer. There is no guarantee that wcrtomb and wcsrtombs are thread-safe when they are passed a null pointer for their mbstate_t argument.
- Implementations that support thread-safe functions will define _POSIX_THREAD_SAFE_FUNCTIONS symbol in
12.7 Cancel Options
- Two thread attributes that are not included in the pthread_attr_t structure are the cancelability state and the cancelability type. These attributes affect the behavior of a thread in response to a call to pthread_cancel(Section 11.5).
- The cancelability state attribute can be PTHREAD_CANCEL_ENABLE or PTHREAD_CANCEL_DISABLE.
#include <pthread.h>int pthread_setcancelstate(int state, int *oldstate);Returns: 0 if OK, error number on failure- A thread can change its cancelability state by calling pthread_setcancelstate. In one atomic operation, pthread_setcancelstate sets the current cancelability state to state and stores the previous cancelability state in the memory location pointed to by oldstate.
- Section 11.5: a call to pthread_cancel doesn’t wait for a thread to terminate. In the default case, a thread will continue to execute after a cancellation request is made until the thread reaches a cancellation point. A cancellation point is a place where the thread checks whether it has been canceled, and if so, acts on the request. POSIX.1 guarantees that cancellation points will occur when a thread calls any of the functions listed in Figure 12.14.

- A thread starts with a default cancelability state of PTHREAD_CANCEL_ENABLE. When the state is set to PTHREAD_CANCEL_DISABLE, a call to pthread_cancel will not kill the thread, the cancellation request remains pending for the thread. When the state is enabled again, the thread will act on any pending cancellation requests at the next cancellation point.
- In addition to the functions in Figure 12.14, POSIX.1 specifies the functions listed in Figure 12.15 as optional cancellation points.

#include <pthread.h>void pthread_testcancel(void);- If application doesn’t call one of the functions in Figure 12.14 or Figure 12.15 for a long time, then you can call pthread_testcancel to add your own cancellation points to the program. When you call pthread_testcancel, if a cancellation request is pending and if cancellation has not been disabled, the thread will be canceled. When cancellation is disabled, calls to pthread_testcancel have no effect.
- The default cancellation type is deferred cancellation. After a call to pthread_cancel, the actual cancellation doesn’t occur until the thread hits a cancellation point. We can change the cancellation type by calling pthread_setcanceltype.
#include <pthread.h>int pthread_setcanceltype(int type, int *oldtype);Returns: 0 if OK, error number on failure- pthread_setcanceltype sets the cancellation type to PTHREAD_CANCEL_DEFERRED/PTHREAD_CANCEL_ASYNCHRONOUS and returns the previous type in the integer pointed to by oldtype.
- Asynchronous cancellation differs from deferred cancellation in that the thread can be canceled at any time. The thread doesn’t necessarily need to hit a cancellation point for it to be canceled.
12.8 Threads and Signals
- Each thread has its own signal mask, but the signal disposition is shared by all threads in the process. Individual threads can block signals, but when a thread modifies the action associated with a given signal, all threads share the action. Thus, if one thread chooses to ignore a given signal, another thread can undo that choice by restoring the default disposition or installing a signal handler for that signal.
- Signals are delivered to a single thread in the process.
- If the signal is related to a hardware fault, the signal is usually sent to the thread whose action caused the event.
- Other signals are delivered to an arbitrary thread.
- In Section 10.12, processes can use sigprocmask function to block signals from delivery. The behavior of sigprocmask is undefined in a multithreaded process. Threads have to use the pthread_sigmask function instead.
#include <signal.h>int pthread_sigmask(int how, const sigset_t *restrict set, sigset_t *restrict oset);Returns: 0 if OK, error number on failure- pthread_sigmask is identical to sigprocmask, except that pthread_sigmask works with threads and returns an error code on failure instead of setting errno and returning -1.
- set contains the set of signals that the thread will use to modify its signal mask.
- how can take on one of three values:
- SIG_BLOCK to add the set of signals to the thread’s signal mask;
- SIG_SETMASK to replace the thread’s signal mask with the set of signals;
- SIG_UNBLOCK to remove the set of signals from the thread’s signal mask.
- If oset is not null, the thread’s previous signal mask is stored in the sigset_t structure to which it points. A thread can get its current signal mask by setting set to NULL and setting oset to the address of a sigset_t structure. In this case, how is ignored.
#include <signal.h>int sigwait(const sigset_t *restrict set, int *restrict signop);Returns: 0 if OK, error number on failure- A thread can wait for one or more signals to occur by calling sigwait.
- set specifies the set of signals for which the thread is waiting. On return, *signop will contain the number of the signal that was delivered.
- If one of the signals specified in the set is pending at the time sigwait is called, then sigwait will return without blocking. Before returning, sigwait removes the signal from the set of signals pending for the process. If the implementation supports queued signals, and multiple instances of a signal are pending, sigwait will remove only one instance of the signal; the other instances will remain queued.
- A thread must block the signals it is waiting for before calling sigwait. sigwait will atomically unblock the signals and wait until one is delivered. Before returning, sigwait will restore the thread’s signal mask. If the signals are not blocked at the time that sigwait is called, then a timing window is opened up where one of the signals can be delivered to the thread before it completes its call to sigwait.
- Advantage to using sigwait is that it can simplify signal handling by allowing us to treat asynchronously generated signals in a synchronous manner. We can prevent the signals from interrupting the threads by adding them to each thread’s signal mask. Then we can dedicate specific threads to handling the signals. These dedicated threads can make function calls without having to worry about which functions are safe to call from a signal handler, because they are being called from normal thread context, not from a traditional signal handler interrupting a normal thread’s execution.
- If multiple threads are blocked in calls to sigwait for the same signal, only one of the threads will return from sigwait when the signal is delivered. If a signal is being caught(the process has established a signal handler by using sigaction, for example) and a thread is waiting for the same signal in a call to sigwait, it is left up to the implementation to decide which way to deliver the signal. The implementation could either allow sigwait to return or invoke the signal handler, but not both.
#include <signal.h>int pthread_kill(pthread_t thread, int signo);Returns: 0 if OK, error number on failure- We call pthread_kill to send a signal to a thread.
- We can pass a signo value of 0 to check for existence of the thread. If the default action for a signal is to terminate the process, then sending the signal to a thread will kill the entire process.
- Alarm timers are a process resource, and all threads share the same set of alarms. It is not possible for multiple threads in a process to use alarm timers without interfering(or cooperating) with one another(Exercise 12.6).
- In Figure 10.23, we waited for the signal handler to set a flag indicating that the main program should exit. The only thread of control that could run were the main thread and the signal handler, so blocking the signals was sufficient to avoid missing a change to the flag. With threads, we need to use a mutex to protect the flag, as we show in Figure 12.16.
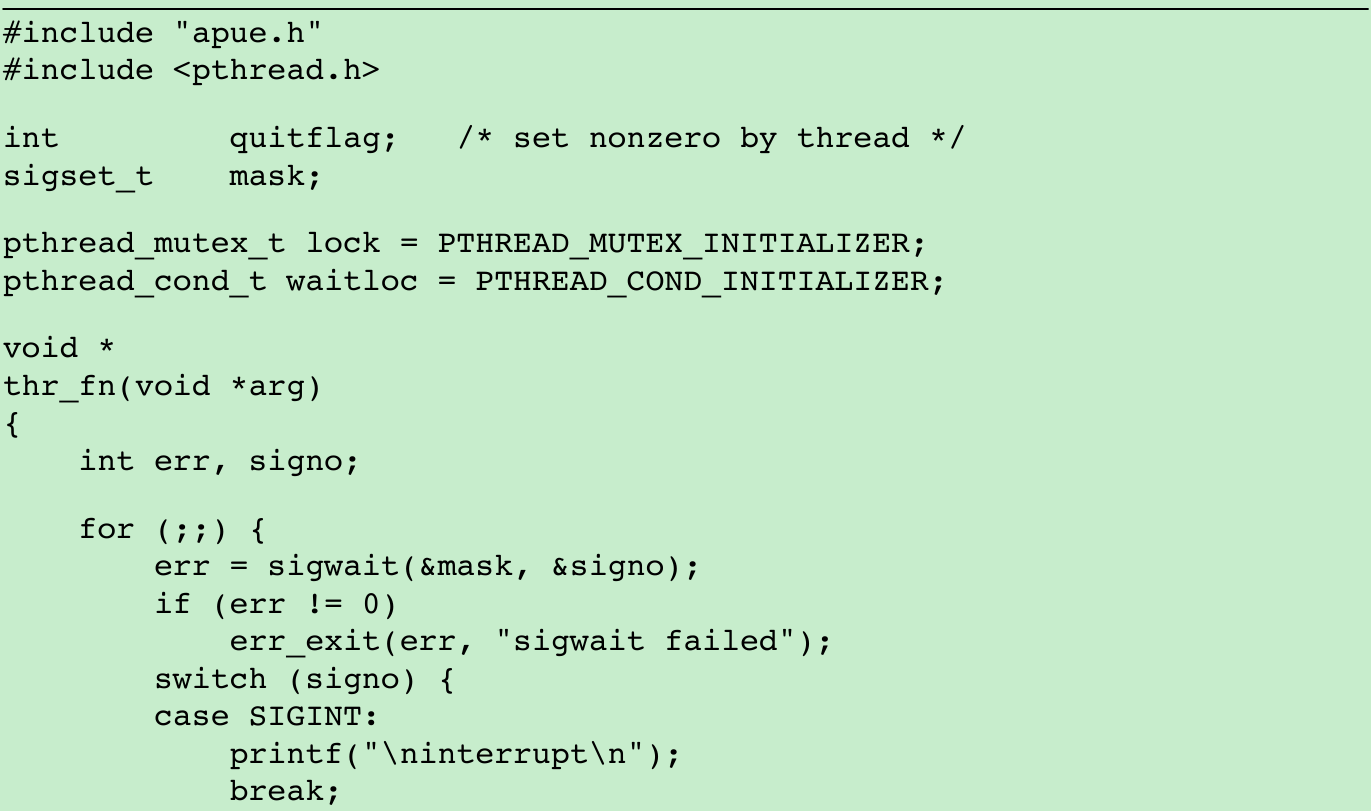

- Instead of relying on a signal handler that interrupts the main thread of control, we dedicate a separate thread of control to handle the signals. We change the value of quitflag under the protection of a mutex so that the main thread of control can’t miss the wake-up call made when we call pthread_cond_signal. We use the same mutex in the main thread of control to check the value of the flag and atomically release the mutex when we wait for the condition.
- We block SIGINT and SIGQUIT in the beginning of the main thread. When we create the thread to handle signals, the thread inherits the current signal mask. Since sigwait will unblock the signals, only one thread is available to receive signals. This enables us to code the main thread without having to worry about interrupts from these signals.
$ ./a.outˆ? #type the interrupt characterinterruptˆ? #type the interrupt character againinterruptˆ? #and againinterruptˆ\ $ #now terminate with quit character12.9 Threads and fork
- When a thread calls fork, a copy of the entire process address space is made for the child. The child is an entirely different process from the parent, and as long as neither one makes changes to its memory contents, copies of the memory pages can be shared between parent and child.
- By inheriting a copy of the address space, the child also inherits the state of every mutex, reader-writer lock, and condition variable from the parent process. If the parent consists of more than one thread, the child will need to clean up the lock state if it isn’t going to call exec immediately after fork returns.
- Inside the child process, only one thread exists. It is made from a copy of the thread that called fork in the parent. If the threads in the parent process hold any locks, the same locks will also be held in the child process. The problem is that the child process doesn’t contain copies of the threads holding the locks, so there is no way for the child to know which locks are held and need to be unlocked.
- This problem can be avoided if the child calls one of the exec functions directly after returning from fork. In this case, the old address space is discarded, so the lock state doesn’t matter. This is not always possible, so if the child needs to continue processing, we need to use a different strategy.
- To avoid problems with inconsistent state in a multithreaded process, POSIX.1 states that only async-signal safe functions should be called by a child process between the time that fork returns and the time that the child calls one of the exec functions. This limits what the child can do before calling exec, but doesn’t address the problem of lock state in the child process.
#include <pthread.h>int pthread_atfork(void(*prepare)(void), void(*parent)(void), void(*child)(void));Returns: 0 if OK, error number on failure- We can install up to three functions by calling pthread_atfork to clean up the lock state.
- The prepare fork handler is called in the parent before fork creates the child process. This fork handler’s job is to acquire all locks defined by the parent.
- The parent fork handler is called in the context of the parent after fork has created the child process, but before fork has returned. This fork handler’s job is to unlock all the locks acquired by the prepare fork handler.
- The child fork handler is called in the context of the child process before returning from fork. It must release all the locks acquired by the prepare fork handler.
- The locks are not locked once and unlocked twice. When the child address space is created, it gets a copy of all locks that the parent defined. Because the prepare fork handler acquired all the locks, the memory in the parent and the memory in the child start out with identical contents. When the parent and the child unlock their copy of the locks, new memory is allocated for the child, and the memory contents from the parent are copied to the child’s memory(copy-on-write), so we are left with a situation that looks as if the parent locked all its copies of the locks and the child locked all its copies of the locks. The parent and the child end up unlocking duplicate locks stored in different memory locations, as if the following sequence of events occurred:
- The parent acquired all its locks.
- The child acquired all its locks.
- The parent released its locks.
- The child released its locks.
- We can call pthread_atfork multiple times to install more than one set of fork handlers. If we don’t have a need to use one of the handlers, we can pass a null pointer for the particular handler argument, and it will have no effect.
- When multiple fork handlers are used, the order in which the handlers are called differs. The parent and child fork handlers are called in the order in which they were registered, whereas the prepare fork handlers are called in the opposite order from which they were registered. This ordering allows multiple modules to register their own fork handlers and still honor the locking hierarchy.
- For example, assume that module A calls functions from module B and that each module has its own set of locks. If the locking hierarchy is A before B, module B must install its fork handlers before module A. When the parent calls fork, the following steps are taken, assuming that the child process runs before the parent:
- The prepare fork handler from module A is called to acquire all of module A’s locks
- The prepare fork handler from module B is called to acquire all of module B’s locks.
- A child process is created.
- The child fork handler from module B is called to release all of module B’s locks in the child process.
- The child fork handler from module A is called to release all of module A’s locks in the child process.
- The fork function returns to the child.
- The parent fork handler from module B is called to release all of module B’s locks in the parent process.
- The parent fork handler from module A is called to release all of module A’s locks in the parent process.
- The fork function returns to the parent.
- If the fork handlers serve to clean up the lock state, what cleans up the state of condition variables?
On some implementations, condition variables might not need any cleaning up. But an implementation that uses a lock as part of the implementation of condition variables will require cleaning up. The problem is that no interface exists to allow us to do this. If the lock is embedded in the condition variable data structure, then we can’t use condition variables after calling fork, because there is no portable way to clean up its state. On the other hand, if an implementation uses a global lock to protect all condition variable data structures in a process, then the implementation itself can clean up the lock in the fork library routine. Application programs shouldn’t rely on implementation details like this, however.

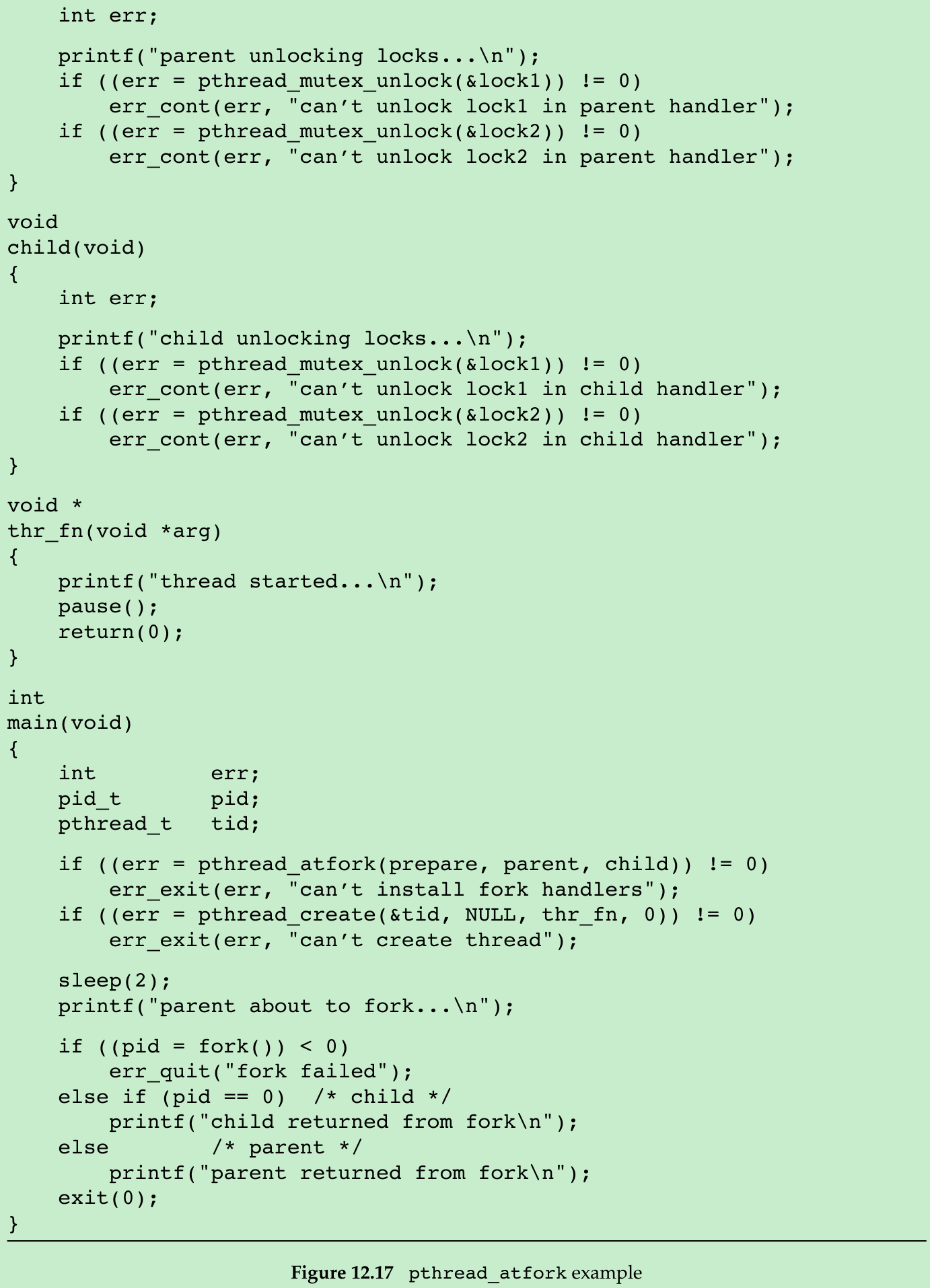
- The program in Figure 12.17 illustrates the use of pthread_atfork and fork handlers. We define two mutexes, lock1 and lock2. The prepare fork handler acquires them both, the child fork handler releases them in the context of the child process, and the parent fork handler releases them in the context of the parent process.
$ ./a.outthread started...parent about to fork...preparing locks...child unlocking locks...child returned from forkparent unlocking locks...parent returned from fork- The prepare fork handler runs after fork is called, the child fork handler runs before fork returns in the child, and the parent fork handler runs before fork returns in the parent.
- Although the pthread_atfork mechanism is intended to make locking state consistent after a fork, it has several drawbacks that make it usable in only limited circumstances:
- There is no good way to reinitialize the state for more complex synchronization objects such as condition variables and barriers.
- Some implementations of error-checking mutexes will generate errors when the child fork handler tries to unlock a mutex that was locked by the parent.
- Recursive mutexes can’t be cleaned up in the child fork handler, because there is no way to determine the number of times one has been locked.
- If child processes are allowed to call only async-signal safe functions, then the child fork handler shouldn’t even be able to clean up synchronization objects, because none of the functions that are used to manipulate them are async-signal safe. The practical problem is that a synchronization object might be in an intermediate state when one thread calls fork, but the synchronization object can’t be cleaned up unless it is in a consistent state.
- If an application calls fork in a signal handler(which is legal, because fork is async-signal safe), then the fork handlers registered by pthread_atfork can call only async-signal safe functions, or else the results are undefined.
12.10 Threads and I/O
- We introduced the pread and pwrite functions in Section 3.11. These functions are helpful in a multithreaded environment, because all threads in a process share the same file descriptors.
- Consider two threads reading from or writing to the same file descriptor at the same time.
Thread A lseek(fd, 300, SEEK_SET); read(fd, buf1, 100);Thread B lseek(fd, 700, SEEK_SET); read(fd, buf2, 100);- If thread A executes the call to lseek and then thread B calls lseek before thread A calls read, then both threads will end up reading the same record. Clearly, this isn’t what was intended.
- To solve this problem, we can use pread to make the setting of the offset and the reading of the data one atomic operation.
Thread A pread(fd, buf1, 100, 300);Thread B pread(fd, buf2, 100, 700);- Using pread, we can ensure that thread A reads the record at offset 300, whereas thread B reads the record at offset 700. We can use pwrite to solve the problem of concurrent threads writing to the same file.
12.11 Summary
Exercises(Redo)
Please indicate the source: http://blog.csdn.net/gaoxiangnumber1
Welcome to my github: https://github.com/gaoxiangnumber1
0 0
- 12-Thread Control
- 《APUE》chapter 12 Thread control 学习笔记(加上自己的代码)
- Simple Transaction Control Util for Simple Thread
- 《Unix高级环境编编程》 第十二章 Thread Control
- Control
- Control
- Control
- Control
- WinForm 之Control.Invoke 和Control.BeginInvoke 方法的使用 Control 不能在创建它的 Thread 之外被调用。但可以通过 invoke 来保证 C
- 在Main Thread之外的线程中更新Control的属性
- 在Main Thread之外的线程中更新Control的属性
- java-12-thread
- java-12-Thread续
- Thread
- thread
- Thread
- Thread
- thread
- Es Query Related
- android通过Handler在线程之间传递消息
- 欢迎使用CSDN-markdown编辑器
- 11-Threads
- Android——ScrollView嵌套ListView/GridView的问题
- 12-Thread Control
- [.Net码农]如何在ASP.NET的web.config配置文件中添加MIME类型
- Redis快速入门
- 解决Qt程序在Linux下无法输入中文的办法
- Java面向对象基础课之三/0909号
- 13-Daemon Processes
- libvirt/qemu特性之快照
- cordova iOS 下插件的使用遇到的问题和解决方法
- 热门威胁情报库深入分析(二)


