常见的连续概率分布
来源:互联网 发布:java 当前时间减1小时 编辑:程序博客网 时间:2024/05/16 19:38
高斯分布
高斯分布是统计学与机器学习中使用最广泛的分布,他的概率密度函数(
高斯分布的精度:
累计分布函数:
退化分布
当
其中
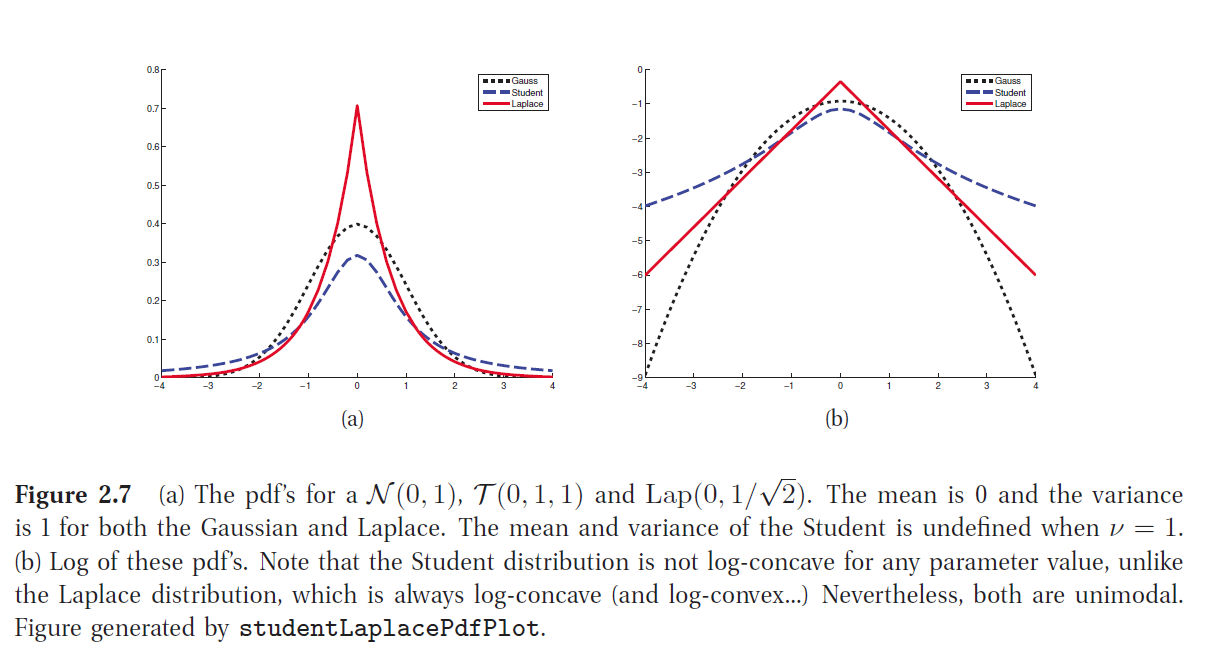
Student t 分布
拉普拉斯分布
其中
伽马分布
伽马分布是一个对正实数随机变量很灵活的分布,
其中,
并且
伽马的逆:
如果
而且该分布:
集中特殊情况下的伽马分布
- 指数分布:
Exp(x|λ)=Ga(x|1,λ) - Erlang分布:
Erlang(x|λ)=Ga(x|2,λ) - Chi-squared分布:
χ2(x|ν)=Ga(x|ν2,12) 。如果Zi∼N(0,1),S=∑νi=1Z2i ,那么S∼χ2ν
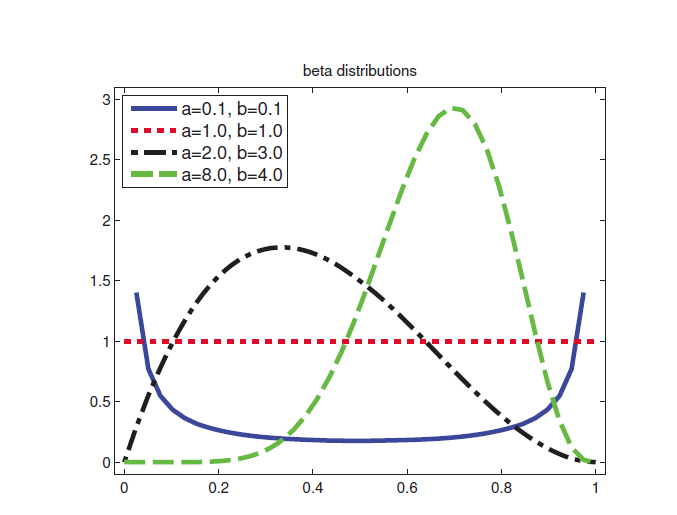
贝塔分布
贝塔分布在[0,1]内,
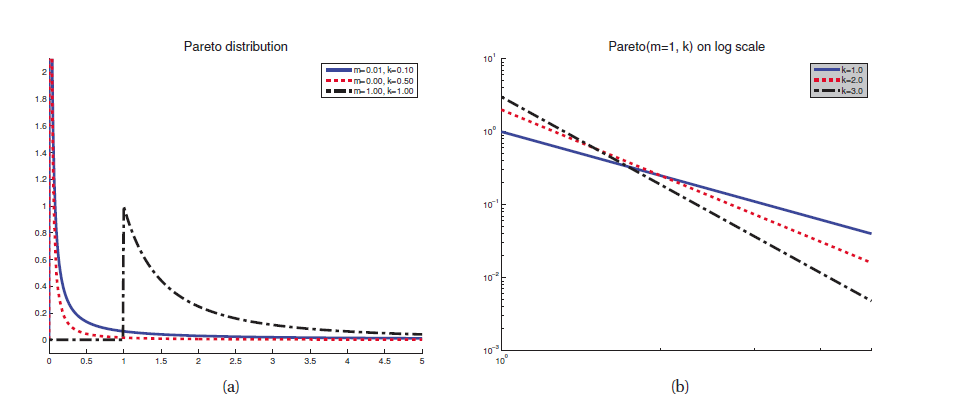
帕累托分布
80/20法则:
参考
Machine Learning A Probabilistic Perspective
帕累托分布
0 0
- 常见的连续概率分布
- 常见的概率分布模型
- 常见离散的概率分布
- 常见的概率分布(matlab作图)
- 常见的几种概率分布
- 概率论:常见概率分布
- 常见概率分布
- 常见概率分布
- 常见的连续概率密度函数
- 统计学:离散型和连续型随机变量的概率分布
- 统计学(三):几种常见的概率分布
- 数据科学家应知必会的6种常见概率分布
- 第六章 连续型变量概率分布
- 概率分布的近似
- 概率分布的转换
- 概率分布的 perplexity
- Excel在统计分析中的应用—第五章—概率分布及概率分布图-Part6-连续型概率分布(正态分布函数的应用)
- Excel在统计分析中的应用—第五章—概率分布及概率分布图-Part7-连续型概率分布(标准正态分布函数的应用)
- [LeetCode-Java]24. Swap Nodes in Pairs
- 第八章:Graphical Models exercise 13-27
- sql注入
- iOS学习---SQLite篇之常用函数中参数的详细介绍
- jquery select2插件初始化时赋多个值
- 常见的连续概率分布
- CNN中全连接层是什么样的?
- 设计模式之二:简单工厂模式—集中式工厂的实现
- 关于链表头插尾插的个人图解
- USART接收中断
- Java初级认证 学习体会 20160922
- 5.5
- 使用SwipeRefreshLayout和自定义的PullToReFreshListView实现下拉刷新和上拉加载更多
- 清除行列


