云存储中的HTTP鉴权算法分析
来源:互联网 发布:买美元保值 知乎 编辑:程序博客网 时间:2024/05/17 02:11
基于 Base64 编码的 HTTP Basic Authentication 由于安全问题,已经不再广泛使用了。在云存储中,数据的安全性一直被广泛关注。亚马逊的 AWS S3 和 OpenStack Swift 分别采取了不同的算法来对每一个 HTTP 请求进行鉴权。这里想对二者的鉴权过程作简单分析和总结。
AWS S3 的 HTTP 请求鉴权流程
AWS 采取的鉴权算法类似于 HTTP 基本认证。我们知道 Base64 只是对字符串进行了一个转换存储,是可以反向解析出源字符串的,因此基本认证中使用 Base64 编码处理过的用户名和密码可以被截获,一旦用户名和密码泄漏,黑客可以构造任何需要的请求进行数据窃取和改写。AWS 采用的是签名认证的思想来解决这一问题,详细的过程参见 Authenticating Requests (AWS Signature Version 4)
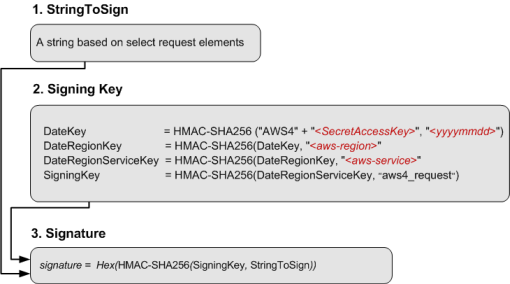
基本原理
- 客户端将请求中的通用信息(如 Bucket Name、Object Name、请求时间和请求方法名等)和 SecretAccessKey(下文简称 SK)进 行 SHA256 哈希计算得到一个字符串;
- 最终在 HTTP 请求中传输的是该 HASH 值。其中 AccessKey(下文简称 AK)在请求中明文传输;
- 服务端拿到该请求后,首先提取出 AK, 然后根据 AK 到服务端的数据库中查询出开户时分配给该用户的 SK;
- 服务端从请求中提取通用信息,配合查询得到的 SK, 使用同样签名计算过程计算一个签名,然后与请求中携带的签名进行比对,二者一致则认为该请求是合法请求,鉴权通过。否则返回 403 鉴权失败。
安全性
如果整个 HTTP 请求被截获,黑客虽然能得到该鉴权值,但是无法反解析出用户的 SK, 因为 SHA 是不可逆的哈希算法。因此最坏的情况:可以重复发送该请求(不修改请求中任一参数)到服务端,攻击范围有限。假设,黑客想使用该鉴权值伪造新的请求,那么修改请求中的通用信息,而签名值没有改变,最终鉴权也无法通过。
那么是不是黑客可以一直使用该鉴权发送该请求呢?也不是的,AWS S3 拿到请求后会比对服务端的时间与请求中的时间的差值,如果该请求的发出时间比服务端的时间早 15 分钟,则认为该请求为非法请求。
从上面的过程来看,AWS 的鉴权算法非常好的解决了密钥泄漏和每一个请求都能得到鉴权的问题。
基于 Keystone 的 OpenStack Swift 的 HTTP 请求鉴权流程
Keystone 的原理比较简单,整个系统提供全局唯一的 Keystone 服务,客户端在发送 HTTP 请求之前,首先需要向 Keystone 申请一个 Token(定长的字符串), 该 Token 的有效期由 Keystone 服务端来指定。申请 Token 时,需要向 Keystone 提供用户名和密码,这里可以理解成 AWS 中的 AK 和 SK, Keystone 认证通过该用户之后,发放 Token 给客户端。之后客户端每次发送 HTTP 请求时都必须携带该 Token, Swift 拿到该 Token 和用户名信息后,也会像 Keystone 查询该 Token 是否有效。Token 有效,则继续处理该业务,Token 无效,则返回鉴权失败。
优缺点
- 相比于 AWS 的鉴权,这里如果 Token 泄漏,会造成比较严重的后果,虽然 Token 有有效期,但是每次都需用用户名和密码去申请,频繁申请也有可能会造成密钥的泄漏;
- 每一次请求都需要 Swift 与 Keystone 之间作一次交互,性能可能存在问题。
事实上,OpenStack 就发生过多次 Token 永久有效的 bug, 导致数据被破坏。当然这样的架构也有其优点,Keystone 可以在多个服务间共享,将鉴权逻辑集中管理,做到了服务级的重用,而 AWS 必须在每一个服务中解析和生成签名,只能做到模块或者代码级别的重用。
- 云存储中的HTTP鉴权算法分析
- 云存储中的 HTTP 鉴权算法分析
- AngularJS中的$http深入分析
- 算法分析中的函数
- ceph存储 ceph集群Paxos算法分析
- 算法分析中的主定理
- 词法分析中的 贪心算法
- HTTP中的Get和Post分析
- Android中的文件存储位置分析
- 云计算中的存储
- Java中的排序算法源码分析
- DirectX SDK中的拾取算法分析
- 算法分析中的小o符号
- java 数组中的去重算法分析
- 算法设计分析中的: 骑士问题
- STL源码分析--list中的sort算法
- AutoCAD中的Spline曲线算法分析(一)
- AutoCAD中的Spline曲线算法分析(二)
- 微信应用号开发教程
- with do的意义
- Java堆、栈溢出程序示例
- tesseract_ocr 字符识别基础及训练字库、合并字库
- iOS xib跳转到storyboard的ViewController页面
- 云存储中的HTTP鉴权算法分析
- 三个动物分水果的故事
- Parajumpers Jakke Salg to adjust any work
- Hibernate二级缓存(一)
- OpenStack Storage for Dummies book
- 流媒体学习之一些应该又了解的名词
- libusb
- mysql优化连接数防止访问量过高的方法
- ArcGIS 测试


