Spark Mllib 回归学习笔记三(java):决策树
来源:互联网 发布:小猪cms9.0源码 编辑:程序博客网 时间:2024/04/27 09:59
决策树
决策树模型,适用于分类、回归。
简单地理解决策树呢,就是通过不断地设置新的条件标准对当前的数据进行划分,最后以实现把原始的杂乱的所有数据分类。
就像下面这个图,如果输入是一大堆追求一个妹子的汉子,妹子内心里有个筛子,最后菇凉也就决定了和谁约(举栗而已哦,不代表什么~大家理解原理重要~~)
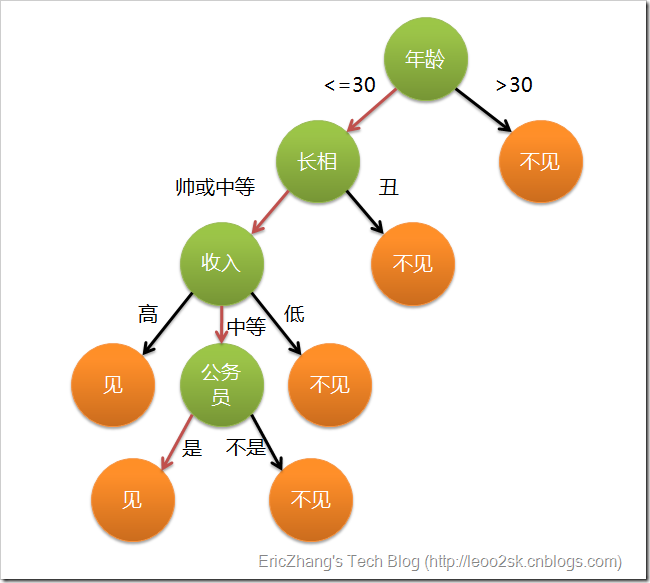
不难看出,构造决策树的关键就在于划分条件和终止条件的决定
一个属性能不能作为划分条件要看用他来分类好不好,我们说原始信息是无序的,那么他能不能很好地降低信息的无序性。
我们常用Gini不纯度、错误率(Error)、熵(Entropy)来衡量信息的混乱程度,公式定义分别如下:



P(i)表示事件i发生的概率,这三个数越大说明数据越不纯。
比较属性的划分效果的算法有C4.5、ID3。详细的可以参考这篇博文在spark中终止条件可以由决策树的构造方法
DecisionTree.trainRegressor(trainingData, categoricalFeaturesInfo, impurity, maxDepth, maxBins)
的参数:最大深度maxDepth、最大划分数(在构建节点时把数据分到多少个盒子中去)maxBins来决定
参数categoricalFeaturesInfo是一个映射表,用来指明哪些特征是分类的,以及他们有多少个类。比如,特征1是一个标签为1,0的二元特征,特征2是0,1,2的三元特征,则传递{1: 2, 2: 3}。如果没有特征是分类的,数据是连续变量,那么我们可以传递空表。
impurity表示结点的不纯净度测量,分类问题采用 gini或者entropy,而回归必须用 variance。
决策树的缺点是容易过拟合,导致训练出来的模型对训练集的拟合效果很好,对其他数据的效果却有所下降。对深度和最大划分数的设定就是为了避免这种情况,当然,在下面我们还将接触到决策树的优化版:随机森林,随机森林就可以很好地处理这个问题。
实例
操作数据
package linear;import java.util.HashMap;import java.util.Map;import scala.Tuple2;import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import org.apache.spark.api.java.function.Function;import org.apache.spark.api.java.function.Function2;import org.apache.spark.api.java.function.PairFunction;import org.apache.spark.mllib.regression.LabeledPoint;import org.apache.spark.mllib.tree.DecisionTree;import org.apache.spark.mllib.tree.model.DecisionTreeModel;import org.apache.spark.mllib.util.MLUtils;public class DecisionTreeRegression { /** * @param args */ public static void main(String[] args) { // TODO Auto-generated method stub SparkConf sparkConf = new SparkConf().setAppName("DecisionTreeRegression").setMaster("local[*]"); JavaSparkContext jsc = new JavaSparkContext(sparkConf); //一、加载文件。libsvm文件格式形如 Label 1:value 2:value.... String datapath = "/home/monkeys/sample_libsvm_data.txt"; JavaRDD<LabeledPoint> data = MLUtils.loadLibSVMFile(jsc.sc(), datapath).toJavaRDD(); //把70%的数据用做训练集,剩下的为测试集 JavaRDD<LabeledPoint> [] splits = data.randomSplit(new double[]{0.7, 0.3}); JavaRDD<LabeledPoint> trainingData = splits[0]; JavaRDD<LabeledPoint> testData = splits[1]; //二、设置参数:这里用hashmap表征连续变量 Map<Integer, Integer> categoricalFeaturesInfo = new HashMap<Integer, Integer>(); String impurity = "variance"; Integer maxDepth = 5;//最大深度 Integer maxBins = 32;//最大划分数 //三、训练模型: final DecisionTreeModel model = DecisionTree.trainRegressor(trainingData, categoricalFeaturesInfo, impurity, maxDepth, maxBins); JavaPairRDD<Double, Double> predictionAndLabel = testData.mapToPair(new PairFunction<LabeledPoint, Double, Double>(){ public Tuple2<Double, Double> call(LabeledPoint p){ return new Tuple2<Double, Double>(model.predict(p.features()), p.label()); } } ); //四、计算误差:平方和的均值 Double testMSE = predictionAndLabel.map(new Function<Tuple2<Double, Double>, Double>(){ //@Override public Double call(Tuple2<Double, Double> p1){ Double diff = p1._1() - p1._2(); return diff * diff; } } ).reduce(new Function2<Double, Double, Double>(){ public Double call(Double a, Double b){ return a + b; } }) / data.count(); System.out.println("Test Mean squared error: " + testMSE); System.out.println("Learned regression tree model: \n" + model.toDebugString()); //model.save(jsc.sc(), "myDecisionTreeRegressionModel"); //DecisionTreeModel sameModel = DecisionTreeModel.load(jsc.sc(), "myDecisionTreeRegressionModel"); } }- Spark Mllib 回归学习笔记三(java):决策树
- Spark Mllib 回归学习笔记一(java):线性回归(线性,lasso,岭),广义回归
- Spark Mllib 回归学习笔记二(java):保序回归
- MLlib回归算法(线性回归、决策树)实战演练--Spark学习(机器学习)
- Apache Spark MLlib学习笔记(五)MLlib决策树类算法源码解析 1
- Apache Spark MLlib学习笔记(六)MLlib决策树类算法源码解析 2
- Apache Spark MLlib学习笔记(七)MLlib决策树类算法源码解析 3
- Spark中组件Mllib的学习36之决策树(使用variance)进行回归
- 决策树回归算法原理及Spark MLlib调用实例(Scala/Java/python)
- Apache Spark MLlib学习笔记(三)MLlib统计指标之关联/抽样/汇总
- Spark MLlib之机器学习(三)
- Spark MLlib学习(二)——分类和回归
- spark之MLlib机器学习-线性回归
- Spark MLlib之决策树(DecisioinTree)
- spark mllib 决策树算法
- Spark MLlib 入门学习笔记
- Spark MLlib 入门学习笔记
- Spark MLlib 入门学习笔记
- STM32通用定时器配置
- 用JAVA求两个数的最大公约数
- 面向对象_方法重写的注意事项
- 深入浅出MySQL(5)-基本数据类型
- POJ 3026 Borg Maze(bfs+最小生成树)
- Spark Mllib 回归学习笔记三(java):决策树
- js二分法排序代码分享
- 框架入门 中级篇 (上)配置类和日志类
- DMA
- python入门笔记
- JavaScrit实现经典排序算法
- /usr/bin/ld: error: cannot find -lGL
- 51nod 1085 背包问题(01背包)
- Intent常用操作代码


