级联分类器概述
来源:互联网 发布:神枪手交易软件 编辑:程序博客网 时间:2024/05/29 01:53
积分图
1.首先介绍下 haar-like feature
使用提取特征而不是直接使用像素值有两方面原因:
The most common reason is that features can act to encode ad-hoc domain knowledge that is difficult to learning using a finite quantity of training data.
For this system there is also a second critical motivation for features: the feature based system operates much faster than a pixel-based system.
Haar-like feature是由等面积的正负矩形区域生成的算子,该论文给出了3种Haar-like feature 算子,如下图所示:

其中A,B分别表示的是水平方向和竖直方向上的梯度,C包含了3个矩形区域,D计算的是对角方向上的梯度。对于不同尺度的算子可以得到不同尺度下的特征。该论文中在(24,24)的图像区域内提取了超过18万个特征,虽然没说算子怎么构造的。
后来的学者设计了更多更复杂的Haar-like featurs:

haar-like 特征的haar来源于haar基函数,如下图:

haar特征就类似二维情形下的haar基函数。
积分图
积分图可以借助于二维积分很容易理解,我们的被积函数是图像的灰度值,定义域是图像区域,那么可以以积分的方式计算从原点到任意点形成的矩形区域内的像素和。
例如区间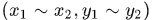 的概率值可以直接使用分布函数得到:
的概率值可以直接使用分布函数得到: , Haar-like特征算子的区域也是矩形区域,所以在计算haar-like特征时可以使用积分图快速的计算。
, Haar-like特征算子的区域也是矩形区域,所以在计算haar-like特征时可以使用积分图快速的计算。
对于论文中提到的三种特征算子,我们假设从左上角坐标开始坐标索引值依次增大,那么对于A类特征值可如下计算: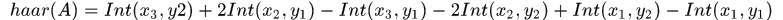
其中 是积分表
是积分表
two-rectangle 特征需要6次查表,如上式, three-rectangle 特征需要8次查表, four-rectangle特征需要9次查表。
基于AdaBoost的特征选择
实际应用中,对分类产生较大影响的往往只有少数的特征,比如传统的主成分分析方法(PCA)就是用来寻找这些对分类影响较大的特征,而论文中提取了180000多的特征,远远过完备(180000>>24*24),所以选择主要的特征是必要的。文中使用adaboost中的弱分类器实现特征的选择,在设计弱分类器时,仅考虑一维特征,选择误差最小的那个分类器作为该轮迭代产生的弱分类器,而对应的维度就是该轮迭代选择出的特征。其过程如下表:

级联分类器
文中给出了一种比传统的AdaBoost分类器更快的分类方法,即级联分类器。该分类器由若干个简单的AdaBoost分类器串接得来。假设AdaBoost分类器要实现99%的正确率,1%的误检率需要200维特征,而实现具有99.9%正确率和50%的误检率的AdaBoost分类器仅需要10维特征,那么通过级联,假设10级级联,最终得到的正确率和误检率分别为:
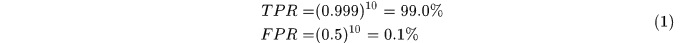
可以看到通过级联adaboost分类器们能够使用较少的特征和较简单的分类器更快更好的实现分类。
另外在检测的过程中,因为TPR较高,所以一旦检测到某区域不是目标就可以直接停止后续检测。由于在人脸检测应用中非人脸区域占大部分,这样大部分检测窗口都能够很快停止,是分类速度得到很大的提高。
级联分类器的训练过程
1. 预先选定每一层的最大可接受误检率fpr(maximum acceptable rate of fpr) 和每一层最小可接受的检测率(minimum acceptable detection rate)
2. 设定系统整体的可接受误检率
3. 初始化. FPR=1, TPR = 1(检测率)
4.循环. 如果当前,添加一层adaboost分类器,如果该分类器训练过程中没有达到该层最大误检率就继续添加新特征,添加新特征时降低阈值,使分类器的检测率大于给定值,然后更新
5.每一级分类器使用的训练集是上一级分类器判定正确的样本,而其中的错分的被当作负样本。这使得下一级的分类器更关注那些更难区分的样本。
cascade detector 示意图

级联discrete adaboost几点说明
1.样本归一化:
(1)尺寸归一化:图片的宽高按相等或近似相等的比例进行缩放,避免图像发生形变。
(2)像素归一化:有文献简单用255来归一化,还有文献使用样本图像的方差均值来归一化。推荐使用后者,避免光照影响,但别忘了考虑方差非常小接近零的情况。
2.最佳弱分类器选取:
3. 级联中每一级的强分类器相关参数设定
3.强分类器阈值如何计算
- 级联分类器概述
- 训练级联分类器
- 级联分类器训练
- 级联分类器
- 级联分类器训练
- openCV 级联分类器
- 级联分类器
- 级联分类器训练
- 级联分类器
- 级联分类器训练
- 级联分类器
- 级联分类器训练过程
- opencv级联分类器训练
- OpenCV级联分类器训练
- Object Detection_1_级联分类器
- opencv训练级联分类器
- 级联分类器训练3
- 关于级联分类器学习
- HTML5+Canvas贪吃蛇
- python3 python3:(unicode error) 'utf-8' codec can't decode
- Leetcode 409. Longest Palindrome 构造最长回文串 解题报告
- 决策树ID3代码(Python)
- 数据结构:(三)栈
- 级联分类器概述
- linux C++ 获取当前日期时间
- Filter——使用篇
- jsp js正则表达式用法
- springmvc常用注解标签详解
- LeetCode 332. Reconstruct Itinerary【medium】
- Python——calendar模块
- 数据段、代码段、堆栈段、BSS段的区别
- 接入支付宝SDK


