隐马尔科夫模型(Hidden Markov Model,HMM)
来源:互联网 发布:淘宝站外推广软件 编辑:程序博客网 时间:2024/06/05 03:07
隐含状态(骰子)之间存在转换概率(transition probability)
隐含状态和可见状态之间有一个概率叫做输出概率(emission probability)
(1)问题1 知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道每次掷出来的都是哪种骰子(隐含状态链)。Viterbi algorithm
求空白处?
算法:1对应的最大概率骰子序列就是D4,因为D4产生1的概率是1/4,高于1/6和1/8。即P1(D4)最大,填上D4;
计算第二个骰子是D4或D8时的概率,发现第二个骰子取到D6的概率最大。即P(D6| D4)最大
仅仅和前一个有关
(2)问题2 知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道掷出这个结果的概率,即当前样本的概率多少
意义在于可以反推模型,如果当前样本的概率是小概率事件,则表明模型错误了。
(3)问题3 知道骰子有几种(隐含状态数量),不知道每种骰子是什么(转换概率),观测到很多次掷骰子的结果(可见状态链),反推出每种骰子是什么(转换概率)。
近似于学习问题。
事先并不知道模型的参数,可以随机的选择一套参数或者事先粗略地给定某个初始参数λ0 ,确定出对应于这组参数的最可能的状态,计算每个训练样本的可能结果的概率,在当前的状态下再由样本对参数修正,重新估计参数λ ,并在新的参数下重新确定模型的状态,这样,通过多次的迭代,循环直至某个收敛条件满足为止,就可以使得模型的参数逐渐逼近真实参数。
EM算法的主要目的是提供一个简单的迭代算法计算后验密度函数,它的最大优点是简单和稳定,但容易陷入局部最优。
对于给定的观察序列O,没有任何一种方法可以精确地找到一组最优的隐马尔科夫模型参数(A、B、pi)使P(O|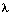 )最大
)最大
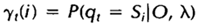 给定观察序列O及隐马尔科夫模型,t时刻位于隐藏状态Si的概率变量
给定观察序列O及隐马尔科夫模型,t时刻位于隐藏状态Si的概率变量
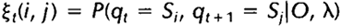 给定观察序列O及隐马尔科夫模型,t时刻位于隐藏状态Si及t+1时刻位于隐藏状态Sj的概率变量
给定观察序列O及隐马尔科夫模型,t时刻位于隐藏状态Si及t+1时刻位于隐藏状态Sj的概率变量
可以写成前向后向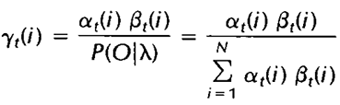
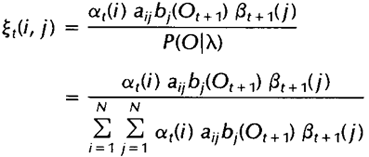
其中
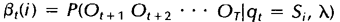 后向变量表示的是已知隐马尔科夫模型及t时刻位于隐藏状态Si这一事实,从t+1时刻到终止时刻的局部观察序列的概率
后向变量表示的是已知隐马尔科夫模型及t时刻位于隐藏状态Si这一事实,从t+1时刻到终止时刻的局部观察序列的概率
并且有关系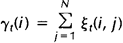

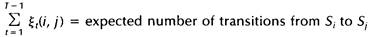 。
。
参数优化
 求得新的
求得新的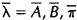 。 理论已经知道
。 理论已经知道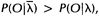 ,因此只有循环优化就能得到最大,不过是一个局部最优解
,因此只有循环优化就能得到最大,不过是一个局部最优解
- 隐马尔科夫模型(Hidden Markov Model,HMM)
- 隐马尔科夫模型(Hidden Markov Model,HMM)
- 隐马尔科夫模型(Hidden Markov Model,HMM)
- 隐马尔科夫模型(Hidden Markov Model,HMM)
- 隐马尔可夫模型(Hidden Markov Model,HMM)
- 隐马尔可夫模型(Hidden Markov Model,HMM)
- 隐马尔科夫(Hidden Markov Model,HMM)详解
- 隐马尔可夫模型(Hidden Markov Model,HMM)是什么?
- 隐马尔可夫模型(Hidden Markov Model - HMM)
- 隐马尔可夫模型 (Hidden Markov Model,HMM)
- 隐马尔可夫模型 (Hidden Markov Model,HMM)理解
- 隐马尔可夫模型 (Hidden Markov Model,HMM)
- 隐马尔可夫模型(hidden Markov model, HMM)
- HMM--hidden markov model
- HMM Hidden Markov Model
- Hidden Markov Model (HMM)
- 隐马尔科夫模型(HIDDEN MARKOV MODEL)
- HMM 隐马尔科夫模型(Hidden Markov Models)
- 防止重复提交要设置全局变量进行校验true false
- apache与 tomcat 搭建https及其关系
- HashMap源码详细介绍和示例
- 浏览器网页的onblur
- LeetCode(133) Clone Graph
- 隐马尔科夫模型(Hidden Markov Model,HMM)
- AD10 画封装经验(突出长度的问题 PCB中任意形状封装修改网络名)
- 3.x版本内核中platform_device的生成
- Bootstrap
- 【C/C++开发】【VS开发】win32位与x64位下各类型长度对比
- 自定义渐进和渐变颜色的进度条
- python实现HTTP请求的接口测试
- 一个无聊的python + opencv 示例
- exec族函数


