network in network
来源:互联网 发布:昆明行知中学校花 编辑:程序博客网 时间:2024/06/01 07:46
Traditional non-convolutional neural net is a stack of fully connected layers. The layers extracts different levels of concepts from the input. When the input has spatial information, for instance, the input is an image, then the spatial information is lost in this process.
While in convolutional neural network, the feature maps generated from the convolutional layers has the same layer out as the input image. Thus the spatial information is still there. Convolution scans the whole image with a square filter, that extracts local information from the underlying patches. It works just like a detector.
The CNN is a extension of non-convolutional deep networks, by replacing each fully connected layers with a convolutional layer. However, there is another extension possible, why not scan the input with a whole deep network? Say, we build a traditional non-convolutional deep net for classification of spatially aligned human face, then we can apply this deep net on all patches of the input image.
In conventional CNN, usually the first layer of convolution is a detection layer of edges, corners and other low level features. Then the second layer detects higher features like parts etc. For face classification, the second layer may learn features such as eyes, noses etc. Then the third layer may combine the eyes noses into a intact face. If we convolve the image with a aligned face classifier, there is no such cascade.
In fact, partitioning an object into parts is more advantageous.
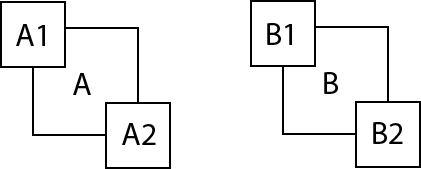
For instance, in this figure, object A consists of two parts A1 and A2. object B consists of B1 and B2. Our task is to separate A from B. Say for A1, A2, B1, B2 each of them has 5 variations. Then in the sample space there are 5x5+5x5=50 variations. To classify all the 50 variations into two classes, we need 50 templates to match each of them. But if each of the parts is classified individually, then we need 5+5+5+5+2=22 templates.
- c = category number.
- p = number of parts in each category.
- v = variation number of each part.
If each category is modelled from the root level, then the template it needs is:
Else, if each parts are modelled and then combined on the root level, then it needs much smaller number of templates:
The above indicates that parts should be classified first then root, else the model will suffer from combinatorial explosion, imagine that A and B are both parts of a bigger object, the combination number increases exponentially as it layers up.
This is also the reason why we should not generate a overcomplete number of feature maps. One thing should be kept in mind that the whole network is doing abstraction. If in one layer overcomplete features are learned, there should be another layer pay the price to shrink the representation. It is true that an overcomplete set of filters (thus an overcomplete set of feature maps) can better model the underlying image patch. The number should be reduced (abstracted) before fed into the next layer whose filter covers a larger spatial region. Else combinatorial explosion can happen.
Thus I think conventional CNN contains two functionalities:
- Partitioning
- Abstraction
Partitioning is already talked about in the previous paragraph, filters are firstly very small then increases in size. Rather than saying that layers in CNN are extracting more and more abstract features, I would say they are just extracting features that are spatially larger and larger.
My understanding of abstraction is the process of classifying all the variations of A1 to the category A1 but not B1 or A2. Thus A1 is an abstract concept. In conventional CNN, the abstraction of each local patch is done through a linear classifier and a non-linear activation function. Which is definitely not a strong abstraction. Weak abstraction resolves the combinatorial explosion to some extent, but not as potent as strong abstraction.
That is why network in network in proposed.
<iframe src="https://drive.google.com/file/d/0B5bEhIhshfIeWmk0YmExazIwdlk/preview" width="640" height="480"></iframe>
- Network In Network(精读)
- Network In Network(精读)
- Network In Network
- DeepLearningNotes: Network In Network
- network in network
- NIN(Network in Network)
- Network In Network
- network in network
- Network in Network
- 神经网络:Network In Network
- Network In Network
- Network in Network 网络分析
- 2014-Network In Network
- Network in Network
- Network in Network 笔记
- network in network论文
- Network In Network
- Network In Network理解
- Redis学习总结和相关资料
- 【java】多线程控制(一)---Semaphore、Exchanger、CyclicBarrier、CountDownLatch
- 浅谈Java中的hashcode方法
- [51单片机] 一个故事看懂单片机中的堆栈
- GObject 学习笔记汇总---1
- network in network
- CRTMPServer 在CentOS 64-bit下的编译
- 常用正则表达式(二)
- javascript关键字和保留字
- js实现页面跳转重定向的几种方式
- Javascript鼠标拖动面板的制作【思路及注意点】
- Spark doBulkLoad数据进入hbase
- Android 浅尝Tinker微信热修复
- centos7 为服务器设置静态内网IP


