caffe学习(2)前后传播,loss,solver
来源:互联网 发布:开淘宝网店发货图片 编辑:程序博客网 时间:2024/05/16 22:38
向前和向后传播
Forward and Backward
前后传播是Net的重要组成,如下图所示: 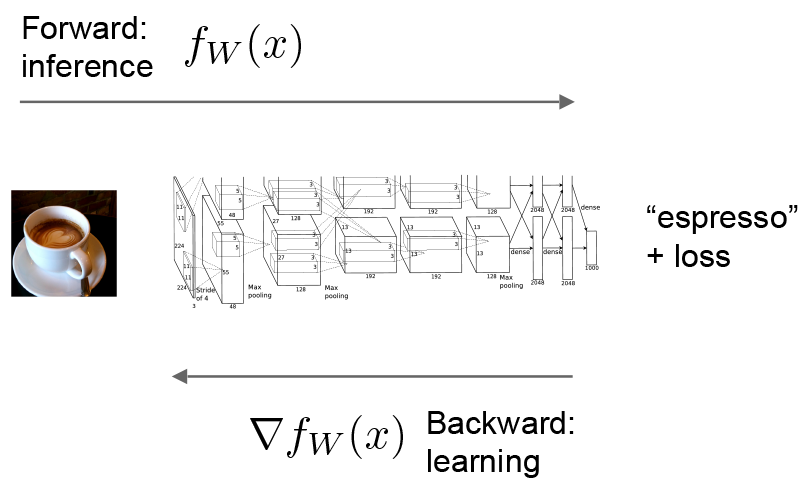
向前Forward
通过给定的参数计算每层的值,就像函数一样top=f(bottom)。 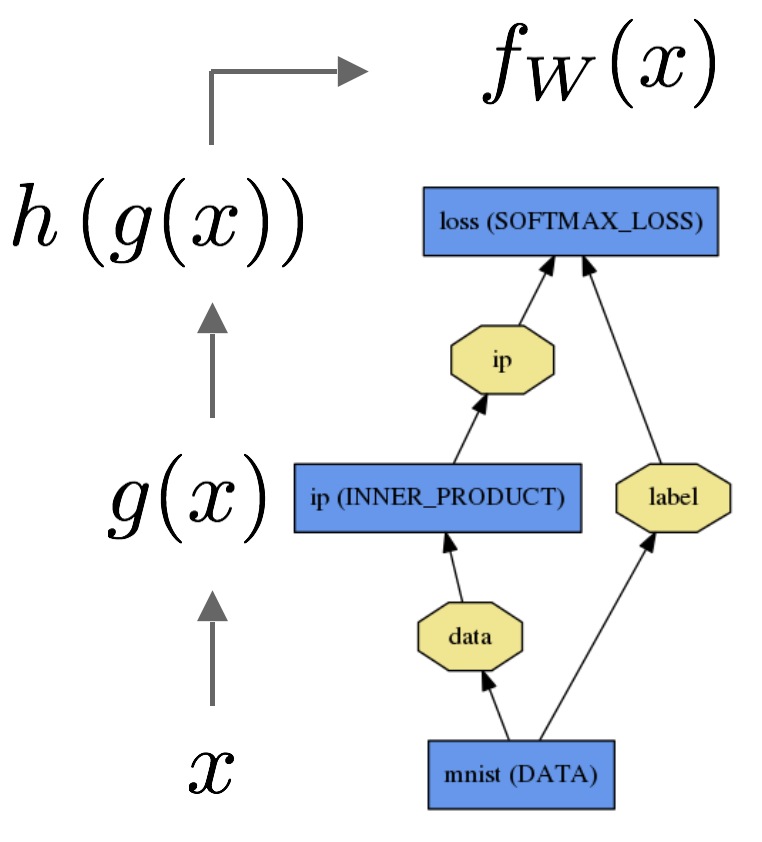
上图表示数据通过内积层输出,再由softmax给出损失。
向后Backward
向后是计算loss的梯度,每层梯度通过自动微分来计算整个模型梯度,即反向传播。 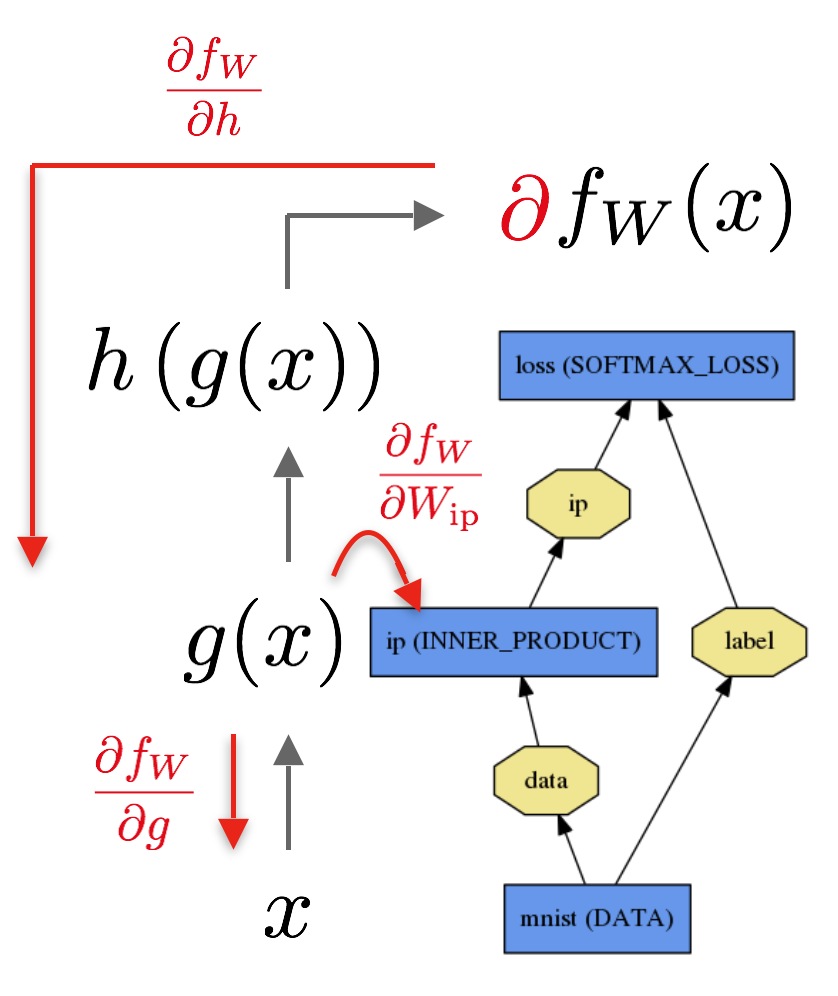
从这个图上可以看出,由loss开始,通过链式法则,不断求出结果对各层的导数。 Net::Forward()和Net::Backward()是针对网络,Layer::Forward()和Layer::Backward()是针对每一层。同时也可以设置CPU、GPU模式。
过程大概是:solver调用forward计算输出和loss,再生成梯度,并尝试更新权重减小loss。
损失Loss
Loss
Loss
使loss变小,是学习中的一个目标。如上所说,loss是由forward计算而出。
layer { name: "loss" type: "SoftmaxWithLoss" bottom: "pred" bottom: "label" top: "loss"}这一段就是上面流程图最后一层loss的表达。
Loss weights
一般的loss只是最后一层才有,其他层只是中间计算,不过每层都可以通过增加loss_weight: <float>到该层生成的每个顶(top)层中。对于后缀有loss的层都隐含着loss_weight: 1(对第一个top,其他的loss_weight: 0)。因此上面代码也等价于在最后加上loss_weight: 1。
然而任何能反向传播的层都可以赋予非零loss_weight,最终的loss由网络上各层loss权重求得
loss := 0for layer in layers: for top, loss_weight in layer.tops, layer.loss_weights: loss += loss_weight * sum(top)Solver
Solver
分类
Solver通过forward和backward形成参数更新,从而改善loss。包括:
- Stochastic Gradient Descent (type: “SGD”),
- AdaDelta (type: “AdaDelta”),
- Adaptive Gradient (type: “AdaGrad”),
- Adam (type: “Adam”),
- Nesterov’s Accelerated Gradient (type: “Nesterov”) and
- RMSprop (type: “RMSProp”)
方法
对于数据集
其中
模型向前计算
具体每种solver,网上讲的很多,这里就不讲了。
0 0
- caffe学习(2)前后传播,loss,solver
- caffe源码学习(2)-softmax loss层
- caffe的python接口学习(2):生成solver文件
- caffe的python接口学习(2):生成solver文件
- caffe的python接口学习(2):生成solver文件
- caffe的python接口学习(2):生成solver文件
- 学习Caffe(四)Loss Layer解析
- Caffe学习:Loss
- Caffe学习:Loss
- Caffe学习:Loss
- caffe学习(8)Solver 配置详解
- Caffe学习:Solver
- Caffe学习3-Solver
- Caffe学习:Solver
- Caffe solver.prototxt学习
- Caffe学习:Solver
- caffe中loss函数代码分析--caffe学习(16)
- caffe的solver文件参数详解--caffe学习(2)
- 重载(overload)和覆盖(重写override)有什么不同?
- string 转int
- PAT(basic level) 1003 我要通过
- JSP新闻系统之五 增加操作
- 安卓项目,信号检测总结
- caffe学习(2)前后传播,loss,solver
- 基于codebook背景建模的运动目标检测
- java 所谓的值传递和引用传递
- 线性表的应用——约瑟夫环
- windows下开启远程连接Mysql
- 滤波器设计(4):自适应滤波器之最小均方误差(LMS)滤波器的设计
- NavigationView的实例应用
- Java并发---- Executor并发框架--ThreadToolExecutor类详解(execute方法)
- 表单


