循环神经网络教程 Part 1笔记
来源:互联网 发布:java 引用动态链接库 编辑:程序博客网 时间:2024/06/06 23:50
Note: Recurrent Neural Networks Tutorial, Part 1 - Introduction To RNNs
本教程包括以下几个部分
1.Introduction To RNNs
2.Implementing a RNN using Python and Theano
3.Understanding the Backpropagation Through Time (BPTT) algorithm and the vanishing gradient problem
4.Implementing a GRU/LSTM RNN
作为tutorial的一部分,我们实现了一个循环神经网络语言模型(RNNLM)。语言模型的应用包括两部分:第一,它允许我们对任意出现的句子根据他们在现实中出现的情况打分。这给了我们一个衡量语法和语义正确性的方法。这样的模型主要用于机器翻译(MT)系统。第二,语言模型允许我们生成文本。在莎士比亚文集上训练一个模型使我们可以生成莎士比亚风格的文本。post Andrej Karpathy 的工作展示了字符级别的语言模型的表达能力。
假设你熟悉基本的Neural Networks。如果不熟悉,可先看IMPLEMENTING A NEURAL NETWORK FROM SCRATCH 。
什么是RNNs
RNNs的思想是充分利用序列信息。传统的神经网络模型中,我们假设所有的输入是互相独立的。但是这对于很多工作是不可行的。顾名思义,RNNs被起名为循环是其对序列的每个元素执行同样的操作,其输出依赖于前次计算的结果。另一种关于RNNs的说法是其拥有捕获已计算节点信息的记忆能力。理论上,RNNs能够利用任长序列的信息,但实际中只向前多看了几步。典型的RNN如下图:

上图显示了一个循环神经网络展开形式。展开意味着将整个句子写成网络。RNN计算公式如下:
xt 表示t=1,2,3... 步的输入。比如,x1 是一个代表句中第二个单词的独热向量。st 是隐层第t 步的状态,st 通过前一个隐层状态及当前输入计算得到:st=f(Uxt+Wst−1) 。函数f 通常是非线性的,如tanh或ReLU。s−1 ,用于计算第一个隐层的状态,通常被初始化为全零。ot 食第t 步的输出。如我们想预测下一个单词,其向量表示为ot=softmax(Vst) 。
需要注意的是:
- 你可以认为隐藏层状态
st 是网络的记忆单元.st 包含了前面所有步的隐藏层状态。而输出层的输出ot 只与当前步的st 有关,在实践中,为了降低网络的复杂度,往往st只包含前面若干步而不是所有步的隐藏层状态; - 不同于传统的DNN,RNN在各步使用同样的参数
U,V,W 。这反映了我们在每一步进行相同的操作,只是输入不同。这大大减少了我们要学习的参数的总数。 - 上图中每一步都会有输出,但是每一步都要有输出并不是必须的。比如,我们需要预测一条语句所表达的情绪,我们仅仅需要关心最后一个单词输入后的输出,而不需要知道每个单词输入后的输出。同理,每步都需要输入也不是必须的。RNNs的关键之处在于隐藏层,隐藏层能够捕捉序列的信息。
RNNs能做什么
RNNs已经被在实践中证明对NLP是非常成功的。如词向量表达、语句合法性检查、词性标注等。在RNNs中,目前使用最广泛最成功的模型便是LSTMs(Long Short-Term Memory,长短时记忆模型)模型,该模型通常比vanilla RNNs能够更好地对长短时依赖进行表达,该模型相对于一般的RNNs,只是隐层的计算不同。对于LSTMs,后面会进行详细地介绍。下面对RNNs在NLP中的应用进行简单的介绍。
语言模型与文本生成(Language Modeling and Generating Text)
给定一个序列,我们希望能够根据前面的词预测每一个词的概率。语言模型能够一个语句正确的可能性,这是机器翻译的一部分,往往可能性越大,语句越正确。得到一个生成模型的另一个作用是能够预测下一个词,这允许我们通过从输出概率中抽样来生成新文本。语言模型中我们的输入是一个词序列,输入是一个预测词的词序列。当训练时,我们令
下面是RNNs中的语言模型和文本生成研究的三篇文章:
- Recurrent neural network based language model
- Extensions of Recurrent neural network based language model
- Generating Text with Recurrent Neural Networks
机器翻译
机器翻译与语言建模的输入都是源语言中的词序列。我们希望以目标语言输出一句话。与语言模型关键的区别在于,需要将源语言语句序列输入后,才进行输出,即输出第一个单词时,便需要从完整的输入序列中进行获取。机器翻译如下图所示: 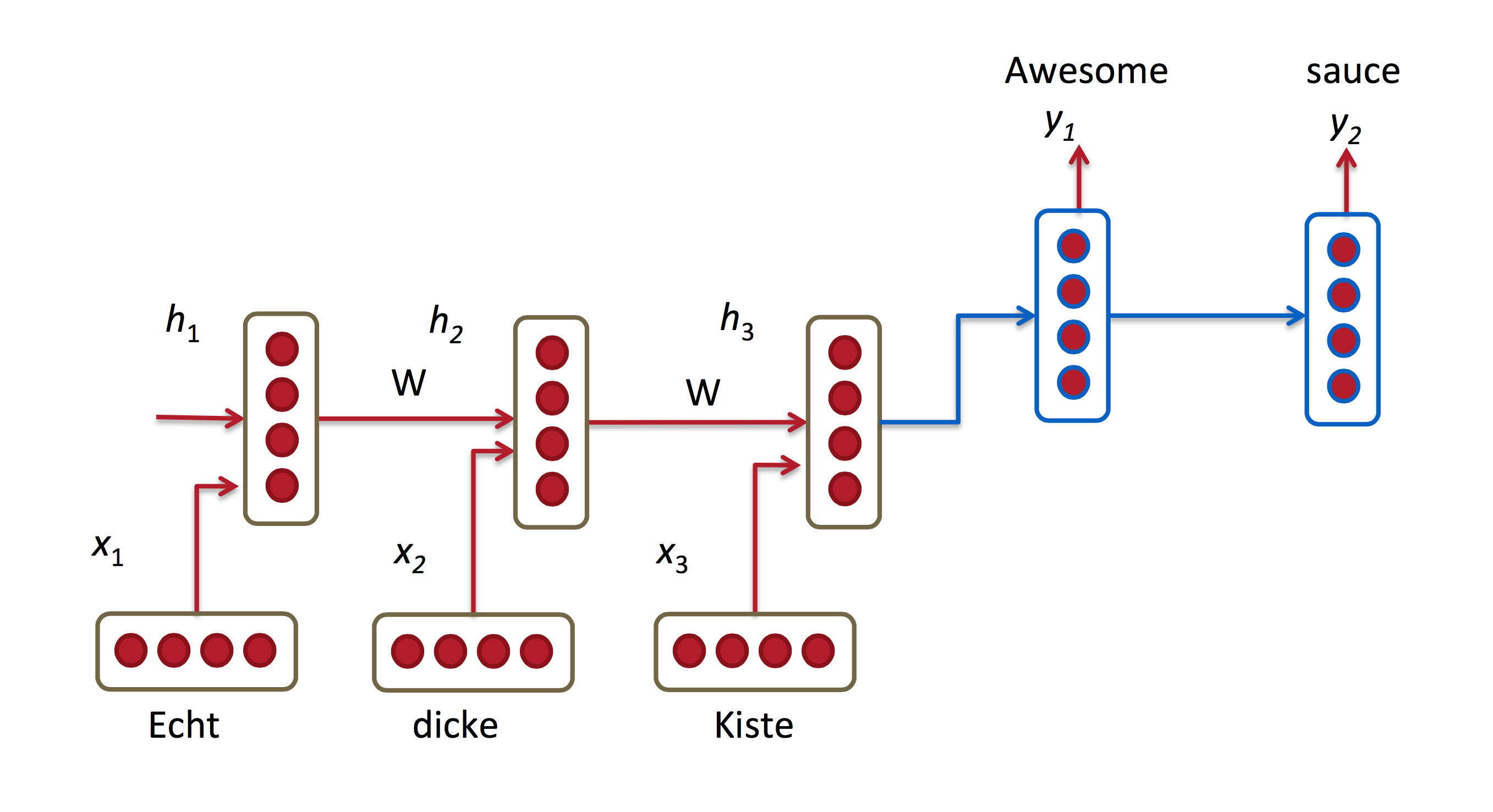
下面是关于RNNs中机器翻译研究的三篇文章:
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
语音识别
语音识别是指给一段声波的声音信号,预测该声波对应的某种指定源语言的语句以及该语句的概率值。
RNNs中的语音识别研究论文:
- Towards End-to-End Speech Recognition with Recurrent Neural Networks.
图像描述生成
和卷积神经网络(convolutional Neural Networks, CNNs)一样,RNNs已经在对无标图像描述自动生成中得到应用。将CNNs与RNNs结合进行图像描述自动生成。这是一个非常神奇的研究与应用。该组合模型能够根据图像的特征生成描述
训练RNNs
训练RNN和训练ANN类似。我们同样使用反向传播,但有一点区别。每一步的输出不仅依赖当前步的网络,并且还以来前面若干步网络的状态。比如,在
RNN扩展
这些年,研究者们已经提出了多钟复杂的RNNs去改进vanilla RNN模型的缺点。下面是目前常见的一些RNNs模型,后面会对其中使用比较广泛的进行详细讲解,在这里进行简单的概述。
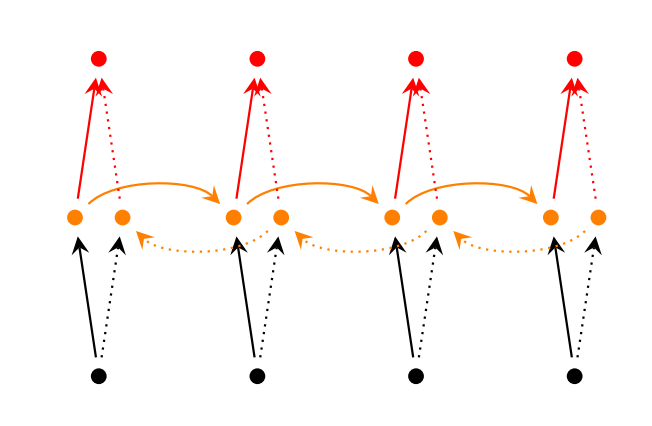
Bidirectional RNNs(双向网络)是,假设当前的输出(第t步的输出)不仅仅与前面的序列有关,并且还与后面的序列有关。例如:预测一个语句中缺失的词语那么就需要根据上下文来进行预测。Bidirectional RNNs是一个相对较简单的RNNs,是由两个RNNs上下叠加在一起组成的。输出由这两个RNNs的隐藏层的状态决定的。如下图所示
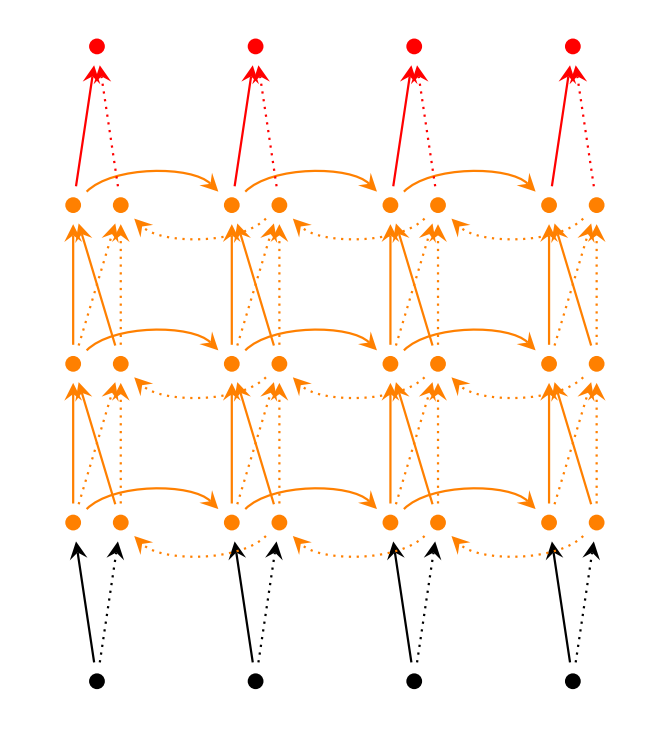
Deep(Bidirectional)RNNs与Bidirectional RNNs相似,只是对于每一步的输入有多层网络。这样,该网络便有更强大的表达与学习能力,但是复杂性也提高了,同时需要更多的训练数据。Deep(Bidirectional)RNNs的结构如下图所示:
GRUs也是一般的RNNs的改良版本,主要是从以下两个方面进行改进。一是,序列中不同的位置处的单词(已单词举例)对当前的隐藏层的状态的影响不同,越前面的影响越小,即每个前面状态对当前的影响进行了距离加权,距离越远,权值越小。二是,在产生误差error时,误差可能是由某一个或者几个单词而引发的,所以应当仅仅对对应的单词weight进行更新。GRUs的结构如下图所示。GRUs首先根据当前输入单词向量word vector已经前一个隐藏层的状态hidden state计算出update gate和reset gate。再根据reset gate、当前word vector以及前一个hidden state计算新的记忆单元内容(new memory content)。当reset gate为1的时候,new memory content忽略之前的所有memory content,最终的memory是之前的hidden state与new memory content的结合。 
LSTMs与GRUs类似,目前非常流行。它与一般的RNNs结构本质上并没有什么不同,只是使用了不同的函数去去计算隐藏层的状态。在LSTMs中,i结构被称为cells,可以把cells看作是黑盒用以保存当前输入xt之前的保存的状态ht−1,这些cells更加一定的条件决定哪些cell抑制哪些cell兴奋。它们结合前面的状态、当前的记忆与当前的输入。已经证明,该网络结构在对长序列依赖问题中非常有效。LSTMs的网络结构如下图所示。对于LSTMs的学习,参见 this post has an excellent explanation

结论
到目前为止,本文对RNNs进行了基本的介绍,并对常见的几种RNNs模型进行了初步讲解。下一步将基于Theano与Python实现一个RNNs语言模型并对上面的一些RNNs模型进行详解。这里有更多的RNNs模型。
参考博文
http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
http://blog.csdn.net/heyongluoyao8/article/details/48636251
- 循环神经网络教程 Part 1笔记
- 循环神经网络教程 Part 2笔记
- 循环神经网络教程 Part 3笔记
- 循环神经网络教程 Part 4笔记
- 循环神经网络教程Recurrent Neural Networks Tutorial, Part 1 – Introduction to RNNs
- [机器学习入门] 李宏毅机器学习笔记-32 (Recurrent Neural Network part 1;循环神经网络 part 1)
- [机器学习入门] 李宏毅机器学习笔记-33 (Recurrent Neural Network part 2;循环神经网络 part 2)
- [机器学习入门] 李宏毅机器学习笔记-34 (Recurrent Neural Network part 3;循环神经网络 part 3)
- 循环神经网络教程3-BP算法和梯度消失问题, Part 3 – Backpropagation Through Time and Vanishing Gradients
- 神经网络学习笔记-02-循环神经网络
- 神经网络学习笔记-02-循环神经网络
- RNN循环神经网络学习笔记
- 循环神经网络教程-第一部分 RNN介绍
- 循环神经网络教程第3部分 BPTT
- 循环神经网络教程第一部分-RNN简介
- TensorFlow循环神经网络系列实践教程
- 循环神经网络教程4-用Python和Theano实现GRU/LSTM RNN, Part 4 – Implementing a GRU/LSTM RNN with Python and Theano
- 卷积神经网络-初学者指南 (Part 1)
- centos7基于Dockerfile搭建jdk、tomcat、maven运行环境
- 响应式内容
- 关于状态栏
- Java基础-常用util1 Date
- CentOS7安装JDK
- 循环神经网络教程 Part 1笔记
- 第十二周 oj训练 十进制转二进制
- 智慧北京:ViewPagerIndicator使用的介绍
- C++中使用new遇到的一个小问题
- Http协议介绍
- 【Pandas】【matplotlib】【DataFrame】特征列可视化实例
- centos中如何安装sqlplus
- C/C++练习1
- android studio lint(查看未被应用的资源文件)的使用


