线性判别函数
来源:互联网 发布:图像处理分水岭算法 编辑:程序博客网 时间:2024/04/29 17:14
线性判别函数
线性判别函数用来对线性可分的数据进行分类
判决方程:
其中,
判别规则:
对于二类分类,判决规则为:
当
当
等于0的情况为不可分。
齐次化
为了便于分析,通常将数据进行齐次化,也就是使得判决方程
具体操作:
也就是说原来我们需要求解
规范化
由上面判决规则可知:
如果对于线性可分的数据,如果我们将
感知准则函数
将样本齐次化和规范化后我们可将损失函数定义为:
这完全符合我们的认知,当错误样本越多
要使得
故更新
具体算法往往有如下几种:
1.可变增量批处理感知准则函数:
可变指
其实对上述算法有个最直接的改进便是在判断错分样本时的标准严格一点,
即:原来是认为
这么做的理由可见如下分析:
当我们在求解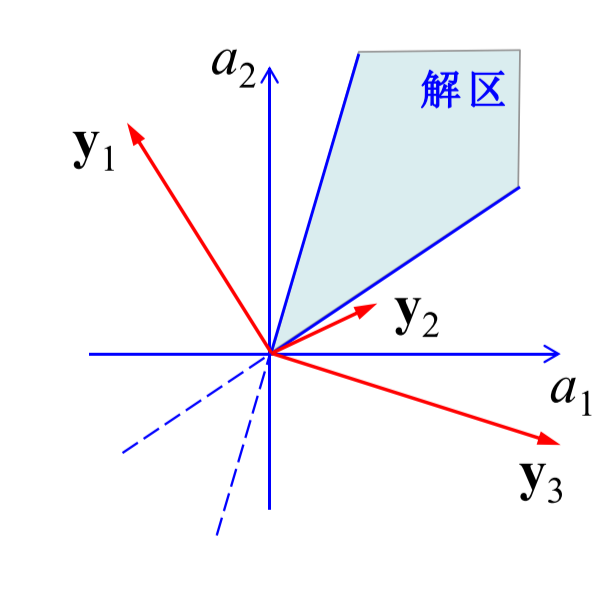
a为解区内的任何一个向量,显然这样a的取值会比较宽泛,如果能够取在靠近解区中心的区域则会更加理想,所以有了采用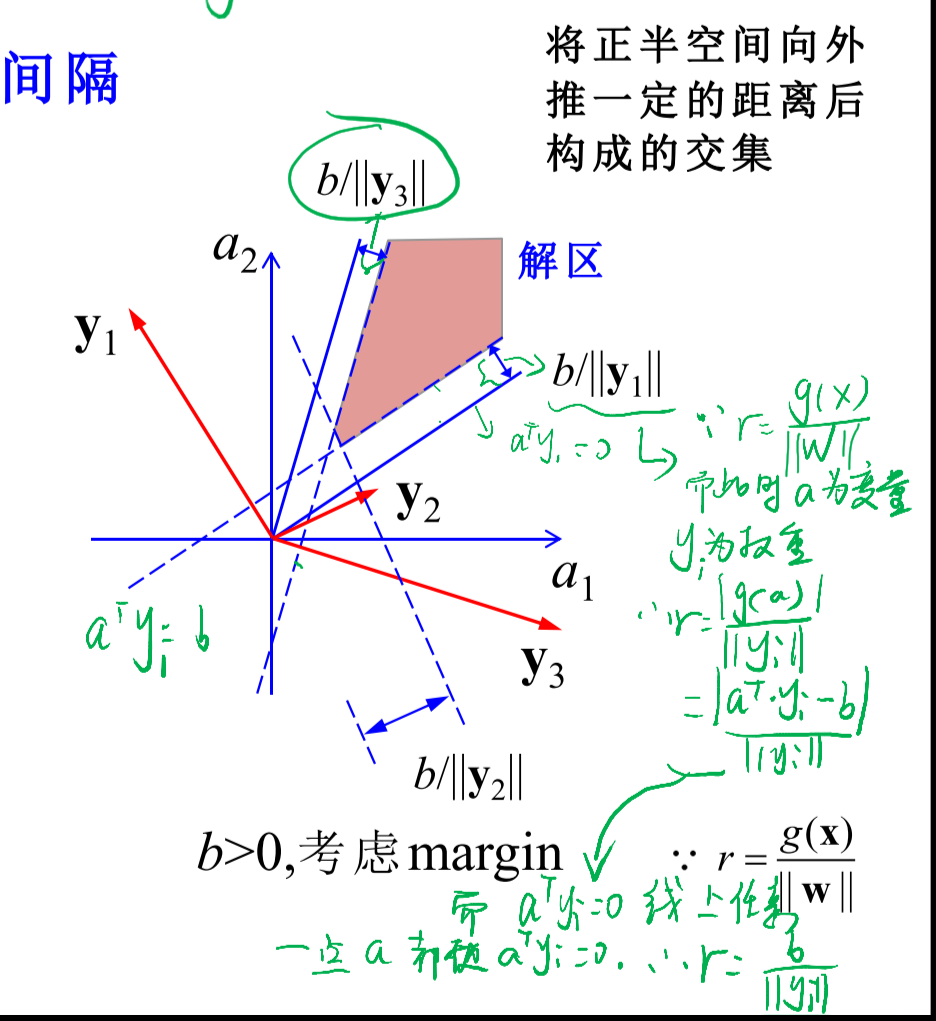
具体算法只需将
(其实我想不出这线性判别函数和SVM有什么区别,感觉都是一样的思想啊,而为了取得更好的效果都增加了一个裕量b,没准等系统学习了SVM就了解了)
2.固定增量批处理感知准则函数
没什么新的,就是将
3.固定单样本感知准则函数
之前都是先统计出所有错误的样本,而现在是发现一个错误样本便修改一次。
更新
具体算法为: 
要注意的是k是在一直累加的,是会超过样本个数n的,如果
MSE算法
之前的感知准则函数都是采用的错误样本来构建的损失函数,而MSE的是采用所有的样本进行构建损失函数。
MSE的思想为:
认为对于所有的样本
设
图中所画绿色圈为一个样本
则对于所有样本会有如下方程: 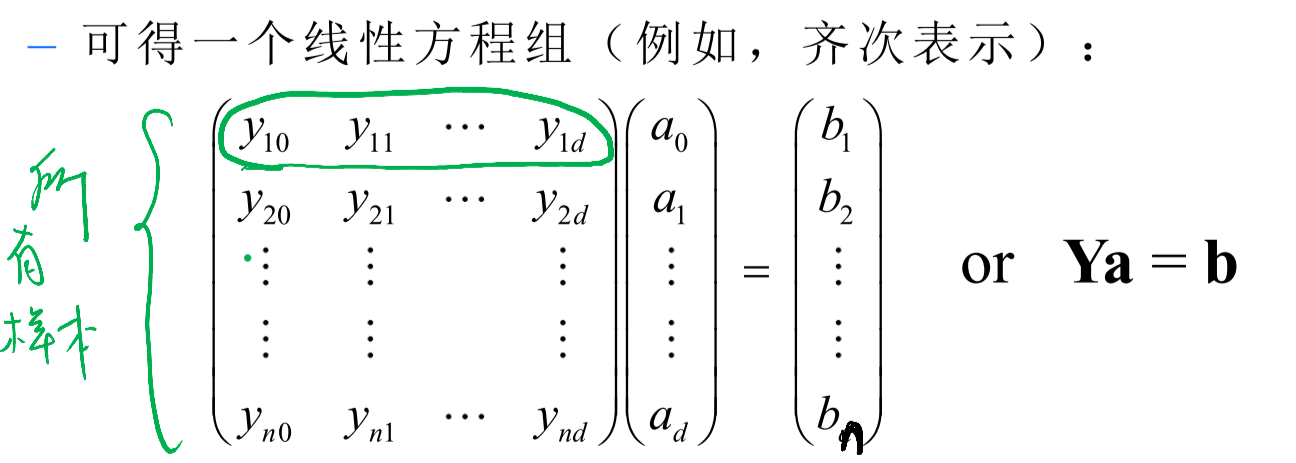
则我们可以直接解出
但是往往
,我们优化的目标便是使得误差最小即可。
故可定义损失函数:
同样求偏导数:
损失函数是一个凸函数(其二阶导大于0),故使的偏导数等于0便可求解
但是当
具体算法为: 
这里要注意的是,
Ho-Kashyap算法
在MSE算法时,我们认为b是已知的,是自己设置的一个正数,而Ho-Kashyap算法认为b是未知的,需要自己求出来。
于是损失函数: 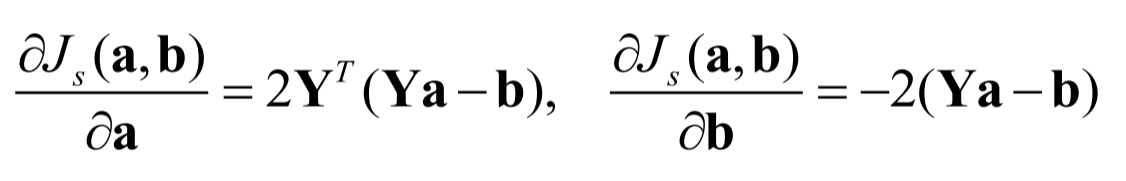
但是因为b需要一直大于0,于是可以进行如下构造: 
故而始终保证了b大于0.
具体算法为: 
简单的实例:
有数据如下: 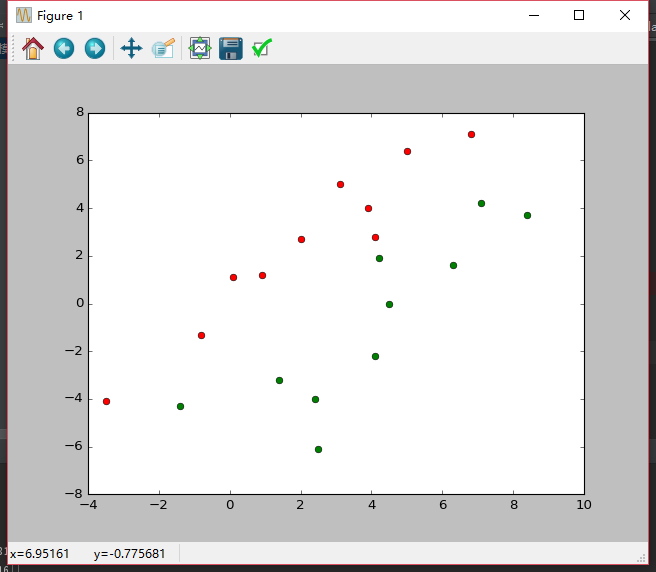
采用可变增量批处理感知器进行分类:
得: 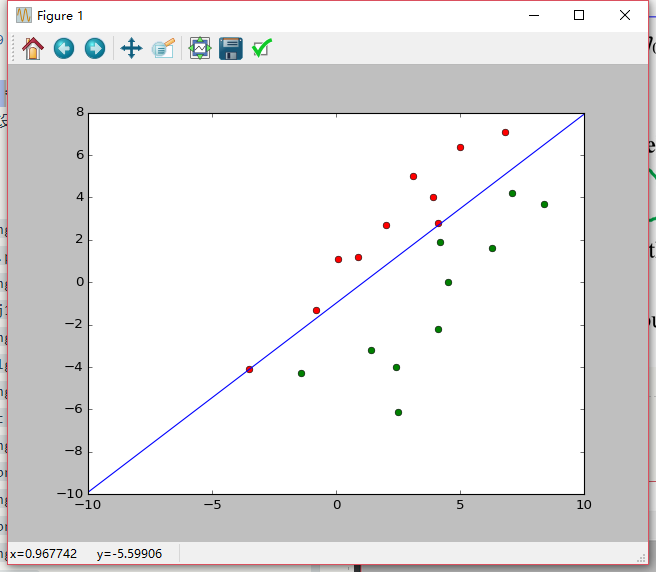
还是采用可变增量批处理感知器进行分类:,只是在判断错误样本时认为
迭代次数为:343次
结果会比单纯的可变增量批处理感知器好: 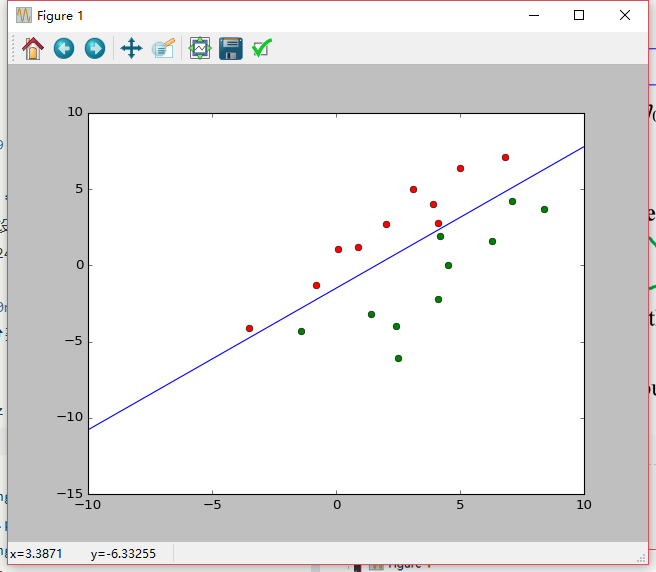
采用H-K算法:
迭代次数为:352次 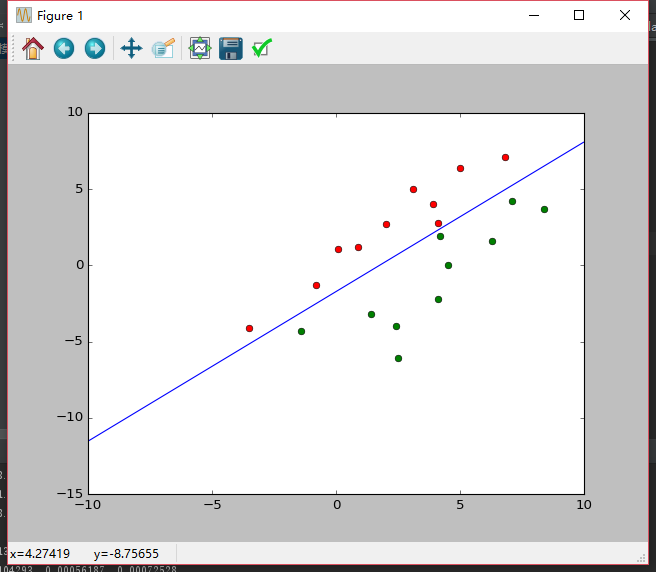
损失函数收敛图为: 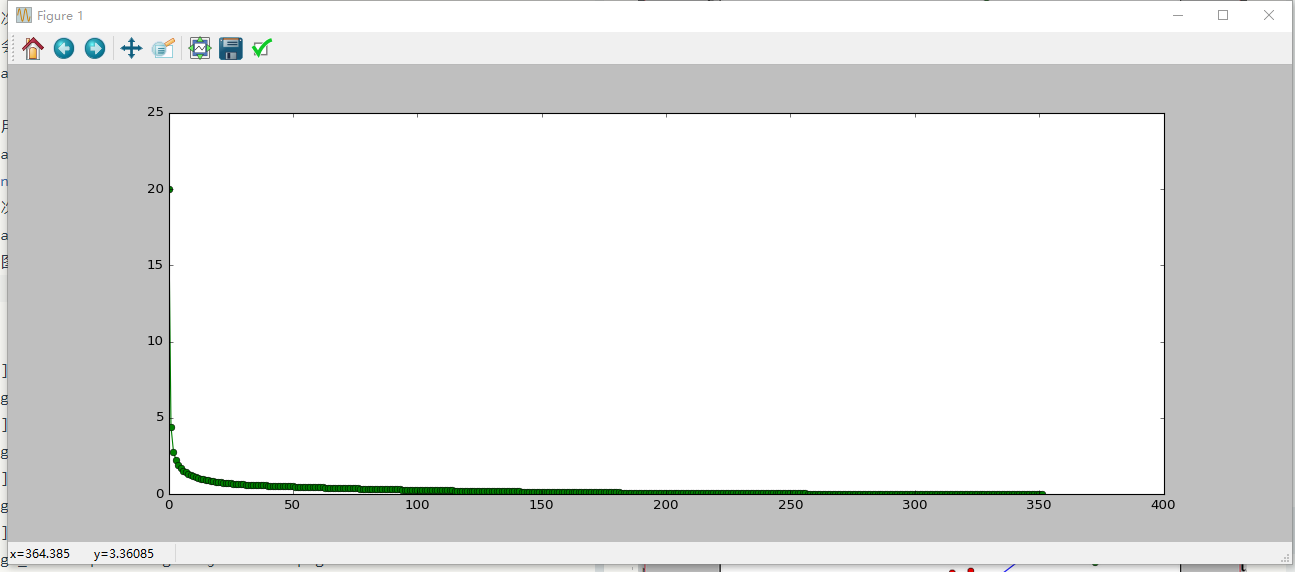
坐标轴取短一点则得如下图: 
- 线性判别函数
- 线性判别函数
- 线性判别函数
- 线性判别函数
- 线性判别函数
- 什么是线性判别函数?
- 【PR学习笔记 一】线性判别函数和广义线性判别函数
- 模式识别(三):线性判别函数
- Fisher线性判别函数+c代码
- 线性分类器之Fisher线性判别函数
- 线性判别函数、判定面以及感知器
- 01-线性可分条件下判别函数权矢量算法
- 线性判别函数:感知器、松弛算法、Ho-Kashyap算法
- 模式识别(Pattern Recognition)学习笔记(七)——线性分类器及线性判别函数
- 模式识别(Pattern Recognition)学习笔记(七)——线性分类器及线性判别函数
- 模式识别(Pattern Recognition)学习笔记(十四)--多类线性判别函数
- 模式识别(Pattern Recognition)学习笔记(二十二)--广义线性判别函数
- 模式识别(Pattern Recognition)学习笔记(十四)--多类线性判别函数
- jquery ajax怎么使用jsonp跨域访问
- bzoj 1226 [SDOI2009]学校食堂Dining 状压dp
- 深入理解Java:注解(Annotation)基本概念
- ContentEditable任意位置输入
- 也讲在 Windows 下安装 lighttpd
- 线性判别函数
- ProtoBuf c++ 使用
- 时间戳转换日期 日期转换时间戳 时间戳转换星期
- HDU2046_骨牌铺方格
- ipad air2设置可以接收iphone的电话
- 基础知识
- C语言再学习 -- Linux 中常用基本命令
- 从request中获取项目的一些路径
- 深入理解Java:注解(Annotation)自定义注解入门


