Codeforces 357D Xenia and Hamming【数学+思维】
来源:互联网 发布:医学科普文章 知乎 编辑:程序博客网 时间:2024/05/01 21:36
Xenia is an amateur programmer. Today on the IT lesson she learned about the Hamming distance.
The Hamming distance between two strings s = s1s2...sn and t = t1t2...tn of equal length n is value 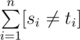 . Record[si ≠ ti] is the Iverson notation and represents the following: ifsi ≠ ti, it is one, otherwise — zero.
. Record[si ≠ ti] is the Iverson notation and represents the following: ifsi ≠ ti, it is one, otherwise — zero.
Now Xenia wants to calculate the Hamming distance between two long strings a and b. The first string a is the concatenation of n copies of stringx, that is, 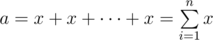 . The second stringb is the concatenation of m copies of string y.
. The second stringb is the concatenation of m copies of string y.
Help Xenia, calculate the required Hamming distance, given n, x, m, y.
The first line contains two integers n andm (1 ≤ n, m ≤ 1012). The second line contains a non-empty stringx. The third line contains a non-empty stringy. Both strings consist of at most 106 lowercase English letters.
It is guaranteed that strings a and b that you obtain from the input have the same length.
Print a single integer — the required Hamming distance.
Please, do not use the %lld specifier to read or write 64-bit integers in С++. It is preferred to use thecin, cout streams or the%I64d specifier.
100 10aaaaaaaaaaa
0
1 1abacabaabzczzz
4
2 3rzraz
5
In the first test case string a is the same as stringb and equals 100 letters a. As both strings are equal, the Hamming distance between them is zero.
In the second test case strings a and b differ in their 3-rd, 5-th, 6-th and 7-th characters. Thus, the Hamming distance equals 4.
In the third test case string a is rzrrzr and string b is azazaz. The strings differ in all characters apart for the second one, the Hamming distance between them equals 5.
题目大意:
给你两个字符串,长度不超过1e6,再给你两个数,表示第一个串重复的次数以及第二个串重复的次数。
定义一种距离其计算方式为:
两个字符串相同位子上的不同字符的个数。
思路:
1、首先我们计算出总长度,然后再算出两个字符串长度的lcm,那么对应总长度/lcm的值就是对应循环的次数,记做cont;
2、然后我们设定g=gcd(字符串A的长度,字符串B的长度);
接着我们通过观察和思考发现,对应我们将字符串A和字符串B都分若干个子段,每个子段长度为g,接下来我们统计两个字符串在一个lcm长度之内相同的元素的个数,记做output,
那么不同的元素的个数为lcm-output;
已知其一共重复的次数为cont,那么结果就是cont*(lcm-output)
Ac代码:
#include<stdio.h>#include<string.h>#include<iostream>using namespace std;#define ll __int64char a[5000000];char b[5000000];ll vis[1005000][26];ll gcd(ll x,ll y){ return y==0?x:gcd(y,x%y);}int main(){ ll n,m; while(~scanf("%I64d%I64d",&n,&m)) { scanf("%s%s",a,b); ll lena=strlen(a); ll lenb=strlen(b); ll zonglen=n*lena; ll g=gcd(lena,lenb); ll lcm=lena*lenb/g; ll cont=zonglen/lcm; ll output=0; for(int i=0;i<lena;i++) { vis[i%g][a[i]-'a']++; } for(int i=0;i<lenb;i++) { output+=vis[i%g][b[i]-'a']; } output=lcm-output; output*=cont; printf("%I64d\n",output); }}- Codeforces 357D Xenia and Hamming【数学+思维】
- Codeforces Round #207 (Div. 2) D. Xenia and Hamming
- CodeForces 339D Xenia and Bit Operations
- CodeForces 339D Xenia and Bit Operations
- cf 356 - Xenia and Hamming
- Codeforces 599D Spongebob and Squares【思维枚举+数学方程】
- Codeforces Xenia and Ringroad
- codeforces 339 D.Xenia and Bit Operations(线段树)
- Codeforces Round #197 (Div. 2) D. Xenia and Bit Operations
- Codeforces Round #197 (Div. 2) D. Xenia and Bit Operations
- codeforces 339D Xenia and Bit Operations 线段树
- CodeForces 339D Xenia and Bit Operations 线段树
- CodeForces 342D Xenia and Dominoes 【DP+容斥】
- Codeforces 339D Xenia and Bit Operations 线段树
- CodeForces 339D Xenia and Bit Operations(线段树)
- CodeForces 339D Xenia and Bit Operations (线段树水题)
- [题解]codeforces 339d Xenia and Bit Operations
- Codeforces Round #207 (Div. 2) Xenia and Hamming(字符串匹配)
- 使用python的request.post时遇到的问题
- c#中 foreach 用法
- ELLA:An Efficient LIfelong Learning Algorithm 随笔
- 【t041】距离之和
- OpenCV之hog源码分析
- Codeforces 357D Xenia and Hamming【数学+思维】
- 高通8916 PMIC休眠关闭LDO调试记录
- Efficient Estimation of Word Representations in Vector Space
- linux账户相关,rpm,网络
- android语音识别Demo
- MySQL Binlog 研究
- java中重写的一些感悟
- MyBatis基本组件与其生命周期
- zookeeper实现分布式锁


