scrapy介绍
来源:互联网 发布:金盾网络验证 编辑:程序博客网 时间:2024/06/07 08:46
scrapy安装
pip install scrapy
windows:
windows下scrapy目前仅支持python2.7, 首先安装vc compiler for py2.7,然后再安装lxml:
pip install lxml#如果无法安装,需要在这里下载对应的.whl文件(http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml),找到对于的版本下载。等待页面加载完,按Ctrl+F查找 Lxml,找到Lxml后在这一行下面找合适的版本文件。#如果没有wheel,先安装pip install wheel#进入下载文件目录,执行安装命令,我的文件名是lxml-3.6.4-cp27-cp27m-win_amd64pip install lxml-3.6.4-cp27-cp27m-win_amd64.whlubantu:
yum install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
scrapy dataflow
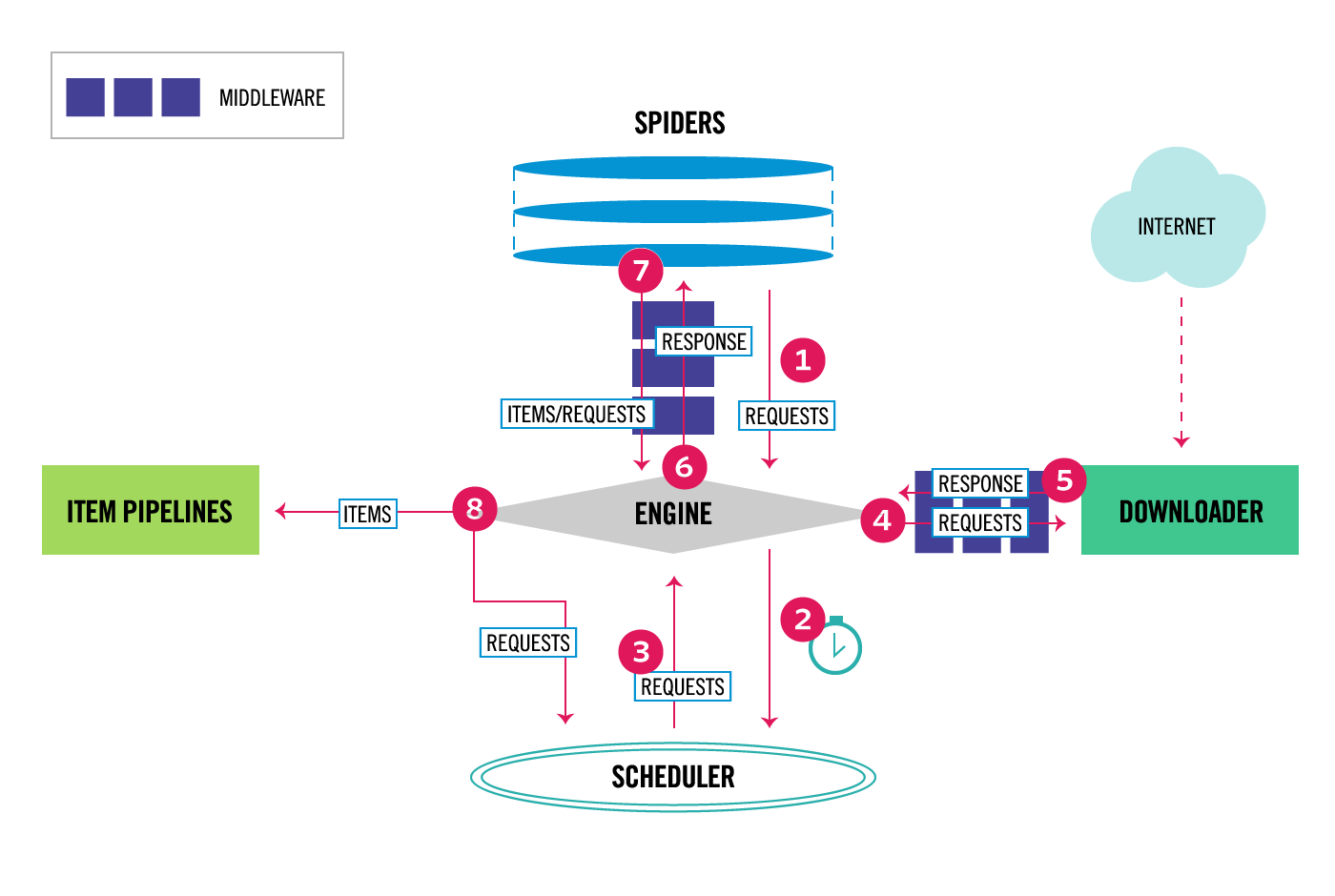
scrapy使用downloader抓取数据,我们只需指定被抓取的url, 抓取的内容进入item pipeline, 由用户进行自定义处理过程。 scrapy框架封装了下载、调度等过程,极大方便了爬虫的编写。
pycharm中scrapy调试
命令行下通过scrapy命令直接运行爬虫应用,但在ide中调试scrapy应用则需要scrapy的python启动脚本,便于设置调试入口,scrapy命令行启动脚本为$PYTHON_HOME\Lib\site-packages\scrapy\cmdline.py,参数栏填写与命令行相同的参数。 
scrapy用法
创建project
scrapy startproject ppspider
项目目录结构
ppspider/
scrapy.cfg # deploy configuration file
tutorial/ # project's Python module, you'll import your code from here __init__.py items.py # project items definition file pipelines.py # project pipelines file settings.py # project settings file spiders/ # a directory where you'll later put your spiders __init__.pypython中配置也是代码,setting.py中是全局配置,对项目下所有spider起作用,可以在settings.py中定义项目用到的一些属性配置,比如数据库连接相关配置。
定义spider
定义一个spider包含两个过程,首先在项目spiders目录下定义实现用户自定义spider,指定抓取数据源以及当前spider的custom_settings;其次,在items.py中定义解析出来的结构化item, 用于在pipeline中流通;最后在pipelines中定义数据处理逻辑的pipeline
LianjiaSpider
为了分析上海各地区房价情况,我们从链家官网上抓取房源信息(房屋结构,面积,地址,房价等)存入MySQL,然后使用sql统计筛选具体房价信息。
1、分析抓取页面url及内容,定义spider入口
继承自scrapy.Spider,custom_setting定制化spider属性, start_requests是下载的入口,在其中定义request以及获取response后的回调函数,进行结构化信息提取。从html中提取信息时可以使用css选择器或xpath就行结点定位和数据提取。
import scrapyfrom ppspider.items import Houseclass LianJiaSpider(scrapy.Spider): name = 'lianjia' url = 'http://sh.lianjia.com/ershoufang/d{}' custom_settings = { 'ITEM_PIPELINES': { 'ppspider.pipelines.persistent_pipeline.PersistentPipeline': 800, } } def start_requests(self): for i in xrange(3501, 4000): //可能会被屏蔽 yield scrapy.Request(self.url.format(i), callback=self.get_house_info) def get_house_info(self, response): house_lst = response.css('#house-lst') house_lst_li = house_lst.xpath('li') house = House() for house_info in house_lst_li: info = house_info.css('.info-panel') house['id'] = info.xpath('h2/a/@key').extract()[0] house['title'] = info.xpath('h2/a/text()').extract()[0] col1 = info.css('.col-1') where = col1.css('.where') house['cell'] = where.xpath('a/span/text()').extract()[0] house['area'] = u','.join(where.xpath('span/text()').extract()) other = col1.css('.other').css('.con') house['location'] = u','.join(other.xpath('a/text()').extract()) chanquan = col1.css('.chanquan').css('.agency').css('.view-label') house['chanquan'] = u','.join(chanquan.xpath('span/span/text()').extract()) col3 = info.css('.col-3') house['total'] = col3.css('.num').xpath('text()').extract()[0] house['price'] = col3.css('.price-pre').xpath('text()').extract()[0] yield house2、item.py中定义房源属性,在response回调中使用
class House(scrapy.Item): id = Field() title = Field() cell = Field() area = Field() location = Field() chanquan = Field() total_price = Field() price = Field()3、 item pipeline将数据抓取和处理异步化,进行信息进一步加工,过滤、持久化等
这里定义一个通用persistent_pipline, 根据item的属性拼接成插入数据的sql,将提取的信息存入db
from scrapy.utils.project import get_project_settingsfrom twisted.enterprise import adbapiimport loggingclass PersistentPipeline(object): insert_sql = """replace into %s (%s) values (%s)""" def __init__(self): settings = get_project_settings() db_args = settings.get('DB_CONNECT') db_server = settings.get('DB_SERVER') self.db_pool = adbapi.ConnectionPool(db_server, **db_args) def __del__(self): pass # self.dbpool.close() def process_item(self, item, spider): keys = item.fields.keys() fields = u','.join(keys) qm = u','.join([u'%s'] * len(keys)) sql = self.insert_sql % (spider.name, fields, qm) data = [] for k in keys: if isinstance(item[k], list) or isinstance(item[k], dict): data.append('%s' % item[k]) else: data.append(item[k]) logging.debug(sql) logging.debug(data) self.db_pool.runOperation(sql, data)运行spider
scrapy crawl lianjia
这样一个简单的spider就已完成,当然用户自定义更多地业务处理pipeline。房源信息存入mysql后,可以借助sql groupBy/orderBy/where过滤统计各种房价信息,此外还可以借助zeepline进行数据可视化显示。
总结
scrapy简单易用,借助scrapy框架以及css/xpath选择器,只用关注业务数据处理,不用关心网络、调度等底层细节,可以很方便的完成一个爬虫。
- scrapy介绍
- Scrapy介绍
- 《Learning Scrapy》1 Scrapy介绍
- Scrapy安装介绍
- Scrapy安装介绍
- Scrapy安装介绍
- Scrapy安装介绍
- Scrapy安装介绍
- Scrapy安装介绍
- Scrapy spiders介绍
- Scrapy selector介绍
- Scrapy安装介绍
- scrapy介绍和安装
- 3、scrapy基本概念介绍
- scrapy一些介绍
- scrapy-redis 介绍
- Scrapy爬虫框架介绍
- Scrapy的安装介绍
- 真机的沙盒拷贝到电脑
- 加法变乘法(蓝桥杯)
- POJ 1017 Packets 笔记
- TV应用内搜索
- Android自定义控件实现时钟
- scrapy介绍
- 架构设计
- 仪表盘
- 手游斗地主打牌界面的UI实现
- Caffe学习笔记4图像特征进行可视化
- 子线程更新UI的方法
- UILable文字竖排的方法汇总
- 注释转换
- VPN协议PPTP/L2TP/OpenVPN及SSH的区别与详解


