【中文分词系列】 4. 基于双向LSTM的seq2seq字标注
来源:互联网 发布:roseonly和野兽派 知乎 编辑:程序博客网 时间:2024/04/28 08:26
转载:https://spaces.ac.cn/archives/3924/
关于字标注法
上一篇文章谈到了分词的字标注法。要注意字标注法是很有潜力的,要不然它也不会在公开测试中取得最优的成绩了。在我看来,字标注法有效有两个主要的原因,第一个原因是它将分词问题变成了一个序列标注问题,而且这个标注是对齐的,也就是输入的字跟输出的标签是一一对应的,这在序列标注中是一个比较成熟的问题;第二个原因是这个标注法实际上已经是一个总结语义规律的过程,以4tag标注为为例,我们知道,“李”字是常用的姓氏,一半作为多字词(人名)的首字,即标记为b;而“想”由于“理想”之类的词语,也有比较高的比例标记为e,这样一来,要是“李想”两字放在一起时,即便原来词表没有“李想”一词,我们也能正确输出be,也就是识别出“李想”为一个词,也正是因为这个原因,即便是常被视为最不精确的HMM模型也能起到不错的效果。
关于标注,还有一个值得讨论的内容,就是标注的数目。常用的是4tag,事实上还有6tag和2tag,而标记分词结果最简单的方法应该是2tag,即标记“切分/不切分”就够了,但效果不好。为什么反而更多数目的tag效果更好呢?因为更多的tag实际上更全面概括了语义规律。比如,用4tag标注,我们能总结出哪些字单字成词、哪些字经常用作开头、哪些字用作末尾,但仅仅用2tag,就只能总结出哪些字经常用作开头,从归纳的角度来看,是不够全面的。但6tag跟4tag比较呢?我觉得不一定更好,6tag的意思是还要总结出哪些字作第二字、第三字,但这个总结角度是不是对的?我觉得,似乎并没有哪些字固定用于第二字或者第三字的,这个规律的总结性比首字和末字的规律弱多了(不过从新词发现的角度来看,6tag更容易发现长词。)。
双向LSTM
关于双向LSTM,理解的思路是:双向LSTM是LSTM的改进版,LSTM是RNN的改进版。因此,首先需要理解RNN。
笔者曾在拙作《从Boosting学习到神经网络:看山是山?》说到过,模型的输出结果,事实上也是一种特征,也可以作为模型的输入来用,RNN正是这样的网络结构。普通的多层神经网络,是一个输入到输出的单向传播过程。如果涉及到高维输入,也可以这样做,但节点太多,不容易训练,也容易过拟合。比如图像输入是1000x1000的,难以直接处理,这就有了CNN;又或者1000词的句子,每个词用100维的词向量,那么输入维度也不小,这时候,解决这个问题的一个方案是RNN(CNN也可以用,但RNN更适合用于序列问题。)。
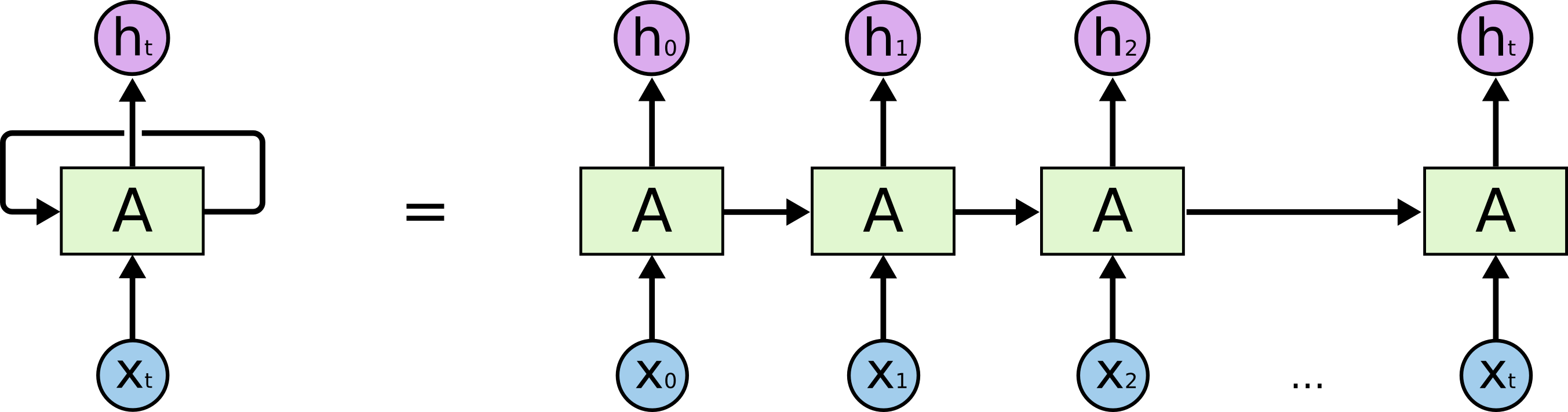
RNN的意思是,为了预测最后的结果,我先用第一个词预测,当然,只用第一个预测的预测结果肯定不精确,我把这个结果作为特征,跟第二词一起,来预测结果;接着,我用这个新的预测结果结合第三词,来作新的预测;然后重复这个过程;直到最后一个词。这样,如果输入有n个词,那么我们事实上对结果作了n次预测,给出了n个预测序列。整个过程中,模型共享一组参数。因此,RNN降低了模型的参数数目,防止了过拟合,同时,它生来就是为处理序列问题而设计的,因此,特别适合处理序列问题。
LSTM对RNN做了改进,使得能够捕捉更长距离的信息。但是不管是LSTM还是RNN,都有一个问题,它是从左往右推进的,因此后面的词会比前面的词更重要,但是对于分词这个任务来说是不妥的,因为句子各个字应该是平权的。因此出现了双向LSTM,它从左到右做一次LSTM,然后从右到左做一次LSTM,然后把两次结果组合起来。
在分词任务中的应用
关于深度学习与分词,很早就有人尝试过了,比如下列文章:
http://blog.csdn.net/itplus/article/details/13616045
https://github.com/xccds/chinese_wordseg_keras
http://www.leiphone.com/news/201608/IWvc75oJglAIsDvJ.html
这些文章中,不管是用简单的神经网络还是LSTM,它们的做法都跟传统模型是一样的,都是通过上下文来预测当前字的标签,这里的上下文是固定窗口的,比如用前后5个字加上当前字来预测当前字的标签。这种做法没有什么不妥之处,但仅仅是把以往估计概率的方法,如HMM、ME、CRF等,换为了神经网络而已,整个框架是没变的,本质上还是n-gram模型。而有了LSTM,LSTM本身可以做序列到序列(seq2seq)的输出,因此,为什么不直接输出原始句子的序列呢?这样不就真正利用了全文信息了吗?这就是本文的尝试。
LSTM可以根据输入序列输出一个序列,这个序列考虑了上下文的联系,因此,可以给每个输出序列接一个softmax分类器,来预测每个标签的概率。基于这个序列到序列的思路,我们就可以直接预测句子的标签。
Keras实现
事不宜迟,动手最重要。词向量维度用了128,句子长度截断为32(抛弃了多于32字的样本,这部分样本很少,事实上,用逗号、句号等天然分隔符分开后,句子很少有多于32字的。)。这次我用了5tag,在原来的4tag的基础上,加上了一个x标签,用来表示不够32字的部分,比如句子是20字的,那么第21~32个标签均为x。
在数据方面,我用了Bakeoff 2005的语料中微软亚洲研究院(Microsoft Research)提供的部分。代码如下,如果有什么不清晰的地方,欢迎留言。
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126
# -*- coding:utf-8 -*-import reimport numpy as npimport pandas as pd s = open('msr_train.txt').read().decode('gbk')s = s.split('\r\n') def clean(s): #整理一下数据,有些不规范的地方 if u'“/s' not in s: return s.replace(u' ”/s', '') elif u'”/s' not in s: return s.replace(u'“/s ', '') elif u'‘/s' not in s: return s.replace(u' ’/s', '') elif u'’/s' not in s: return s.replace(u'‘/s ', '') else: return s s = u''.join(map(clean, s))s = re.split(u'[,。!?、]/[bems]', s) data = [] #生成训练样本label = []def get_xy(s): s = re.findall('(.)/(.)', s) if s: s = np.array(s) return list(s[:,0]), list(s[:,1]) for i in s: x = get_xy(i) if x: data.append(x[0]) label.append(x[1]) d = pd.DataFrame(index=range(len(data)))d['data'] = datad['label'] = labeld = d[d['data'].apply(len) <= maxlen]d.index = range(len(d))tag = pd.Series({'s':0, 'b':1, 'm':2, 'e':3, 'x':4}) chars = [] #统计所有字,跟每个字编号for i in data: chars.extend(i) chars = pd.Series(chars).value_counts()chars[:] = range(1, len(chars)+1) #生成适合模型输入的格式from keras.utils import np_utilsd['x'] = d['data'].apply(lambda x: np.array(list(chars[x])+[0]*(maxlen-len(x))))d['y'] = d['label'].apply(lambda x: np.array(map(lambda y:np_utils.to_categorical(y,5), tag[x].reshape((-1,1)))+[np.array([[0,0,0,0,1]])]*(maxlen-len(x)))) #设计模型word_size = 128maxlen = 32from keras.layers import Dense, Embedding, LSTM, TimeDistributed, Input, Bidirectionalfrom keras.models import Model sequence = Input(shape=(maxlen,), dtype='int32')embedded = Embedding(len(chars)+1, word_size, input_length=maxlen, mask_zero=True)(sequence)blstm = Bidirectional(LSTM(64, return_sequences=True), merge_mode='sum')(embedded)output = TimeDistributed(Dense(5, activation='softmax'))(blstm)model = Model(input=sequence, output=output)model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) batch_size = 1024history = model.fit(np.array(list(d['x'])), np.array(list(d['y'])).reshape((-1,maxlen,5)), batch_size=batch_size, nb_epoch=50) #转移概率,单纯用了等概率zy = {'be':0.5, 'bm':0.5, 'eb':0.5, 'es':0.5, 'me':0.5, 'mm':0.5, 'sb':0.5, 'ss':0.5 } zy = {i:np.log(zy[i]) for i in zy.keys()} def viterbi(nodes): paths = {'b':nodes[0]['b'], 's':nodes[0]['s']} for l in range(1,len(nodes)): paths_ = paths.copy() paths = {} for i in nodes[l].keys(): nows = {} for j in paths_.keys(): if j[-1]+i in zy.keys(): nows[j+i]= paths_[j]+nodes[l][i]+zy[j[-1]+i] k = np.argmax(nows.values()) paths[nows.keys()[k]] = nows.values()[k] return paths.keys()[np.argmax(paths.values())] def simple_cut(s): if s: r = model.predict(np.array([list(chars[list(s)])+[0]*(maxlen-len(s))]), verbose=False)[0][:len(s)] r = np.log(r) nodes = [dict(zip(['s','b','m','e'], i[:4])) for i in r] t = viterbi(nodes) words = [] for i in range(len(s)): if t[i] in ['s', 'b']: words.append(s[i]) else: words[-1] += s[i] return words else: return [] not_cuts = re.compile(u'([\da-zA-Z ]+)|[。,、?!\.\?,!]')def cut_word(s): result = [] j = 0 for i in not_cuts.finditer(s): result.extend(simple_cut(s[j:i.start()])) result.append(s[i.start():i.end()]) j = i.end() result.extend(simple_cut(s[j:])) return result
我们可以用model.summary()看一下模型的结构。
最终的模型结果如何?我不打算去对比那些评测结果了,现在的模型在测试上达到90%以上的准确率不是什么难事。我关心的是对新词的识别和对歧义的处理。下面是一些测试结果(随便选的):
可以发现,测试结果是很乐观的。不论是人名(中国人名或外国人名)还是地名,识别效果都很好。关于这个模型,目前就说到这里,以后会继续深入的。
最后
事实上本文是提供了一个框架,能够直接通过双向LSTM对序列进行标注,给出完整的标注序列。这种标注的思路,可以用于很多任务,如词性标注、实体识别,因此,基于双向LSTM的seq2seq标注思路,有很广的应用,值得研究。甚至最近热门的深度学习的机器翻译,都是用这种序列到序列的模型实现的。
msr_train.txt.zip
- 【中文分词系列】 4. 基于双向LSTM的seq2seq字标注
- 基于双向LSTM的seq2seq字标注
- 基于字标注的中文分词方法
- 笔记-2007-基于有效子串标注的中文分词
- 基于N-gram的双向最大匹配中文分词
- 基于N-gram的双向最大匹配中文分词
- 双向LSTM NLP序列标注
- 基于Seq2seq的中文聊天机器人
- 《中文分词之字标注法----概述》
- 97.5%准确率的深度学习中文分词(字嵌入+Bi-LSTM+CRF)
- 97.5%准确率的深度学习中文分词(字嵌入+Bi-LSTM+CRF)
- 【中文分词系列】 5. 基于语言模型的无监督分词
- 基于LSTM的中文语法错误诊断
- 基于CRF的中文分词
- 基于CRF的中文分词
- 基于CRF的中文分词
- 基于CRF的中文分词
- 基于CRF的中文分词
- POJ2411,dp+dfs+状压
- 软链接作用及使用实战
- 蓝鸥React Native零基础入门到项目实战 Hello React
- 稀疏自编码
- linux命令怎么显示文件某一行或几行内容
- 【中文分词系列】 4. 基于双向LSTM的seq2seq字标注
- 解决button多次重复点击
- 生产环境-linux-tomcat宕掉解决办法
- lintcode,二叉树的序列化和反序列化
- 不会画类图,用Eclipse插件呀
- java编写文件路径用的File.separator和直接打“\\”有什么区别啊?
- 自制悬浮框,愉快地查看栈顶 Activity
- 4-oracle用户
- 深入理解abstract class和interface


