机器学习——连续型特征离散化
来源:互联网 发布:卡密生成软件 编辑:程序博客网 时间:2024/05/16 14:34
在特征工程中,特别是logistic regression上,需要把一些连续特征进行离散化处理。离散化除了一些计算方面等等好处,还可以引入非线性特性,也可以很方便的做cross-feature。离散特征的增加和减少都很容易,易于模型的快速迭代。此外,噪声很大的环境中,离散化可以降低特征中包含的噪声,提升特征的表达能力。
连续特征离散化最常用的方法:
(1)划分区间
如1-100岁可以划分为:(0-18)未成年、(18-50)中青年、(50-100)中老年.
这其中包括等距划分、按阶段划分、特殊点划分等。
(2)卡方检验(CHI)
分裂方法,就是找到一个分裂点看,左右2个区间,在目标值上分布是否有显著差异,有显著差异就分裂,否则就忽略。这个点可以每次找差异最大的点。合并类似,先划分如果很小单元区间,按顺序合并在目标值上分布不显著的相邻区间,直到收敛。卡方值通常由χ2分布近似求得。
χ2表示观察值与理论值之问的偏离程度。计算这种偏离程度的基本思路如下:
(1)设A代表某个类别的观察频数,E代表基于H0计算出的期望频数,A与E之差称为残差。
(2)显然,残差可以表示某一个类别观察值和理论值的偏离程度,但如果将残差简单相加以表示各类别观察频数与期望频数的差别,则有一定的不足之处。因为残差有正有负,相加后会彼此抵消,总和仍然为0,为此可以将残差平方后求和。
(3)另一方面,残差大小是一个相对的概念,相对于期望频数为10时,期望频数为20的残差非常大,但相对于期望频数为1 000时20的残差就很小了。考虑到这一点,人们又将残差平方除以期望频数再求和,以估计观察频数与期望频数的差别。
进行上述操作之后,就得到了常用的χ2统计量,由于它最初是由英国统计学家Karl Pearson在1900年首次提出的,因此也称之为Pearson χ2,其计算公式为
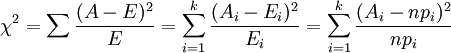 (i=1,2,3,…,k)
(i=1,2,3,…,k)
当n比较大时,χ2统计量近似服从k-1(计算Ei时用到的参数个数)个自由度的卡方分布。
(3)信息增益法(IG)
这个和决策树的学习很类似。分裂方法,就是找到一个分裂点看,左右2个区间,看分裂前后信息增益变化阈值,如果差值超过阈值(正值,分列前-分裂后信息熵),则分裂。每次找差值最大的点做分裂点,直到收敛。合并类似,先划分如果很小单元区间,按顺序合并信息增益小于阈值的相邻区间,直到收敛。
,信息增益为总的熵减去某个分类标准对应的熵。
熵:
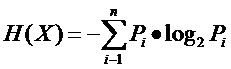
条件熵:
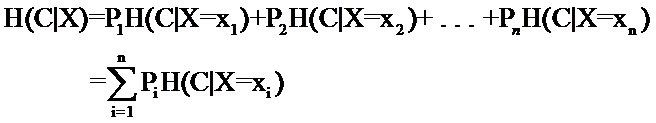
-------------------另一种记法----------------------

信息增益比率实际在信息增益的基础上,又将其除以一个值,这个值一般被称为为分裂信息量:


- 机器学习——连续型特征离散化
- 【机器学习】对于特征离散化,特征交叉,连续特征离散化非常经典的解释
- 机器学习 特征工程 特征离散化
- 连续特征离散化
- 连续特征离散化
- 连续特征的离散化
- LR连续特征离散化
- 特征离散化,特征交叉,连续特征离散化
- 机器学习之离散型特征处理--独热码(one_hot_encoding)
- 连续特征离散化和归一化
- 连续特征离散化的好处
- 为什么要将连续特征离散化
- 连续特征离散化的方法
- 连续特征的离散化的意义
- 连续特征离散化的方法
- 连续特征离散化和归一化
- 连续特征离散化的方法
- mllib下决策树——连续特征与离散特征的split与bin的确定
- Js中概念理解(一)
- Activiti BPMN 2.0 designer插件安装
- SQL Server遍历表的几种方法
- .py文件的执行
- 使用Spring AOP实现MySQL数据库读写分离案例分析
- 机器学习——连续型特征离散化
- poj 1474 Video Surveillance (半平面交)
- CSS3--文字阴影
- iOS 仿百度外卖-首页重力感应
- 机器学习笔记1
- Spring4Mvc纯注解启动,无web.xml
- Spring中配置和读取多个Properties文件
- ionic使用
- Windows python必备网站


