4.NLTK之编写结构化程序
来源:互联网 发布:mac装win10多少钱 编辑:程序博客网 时间:2024/06/06 15:04
回归基础
赋值
赋值似乎是最基本的编程概念,不值得单独讨论。不过,也有一些令人吃惊的微妙之处 。思考下面的代码片段:
>>> foo = 'Monty'>>> bar = foo >>> foo = 'Python' >>> bar'Monty'由于bar是foo的一个副本,所以改变foo时,bar不会受到影响。
然而,赋值语句并不总是以这种方式复制副本。特别是结构化对象的“值”,例如一个链表,实际上是一个对象的引用。例如:
>>> foo = ['Monty', 'Python']>>> bar = foo >>> foo[1] = 'Bodkin' >>> bar['Monty', 'Bodkin']在下图中,我们看到一个链表 foo 是存储在位置 3133 处的一个对象的引用。当我们赋值 bar = foo时,仅仅是 3133 位置处的引用被复制。 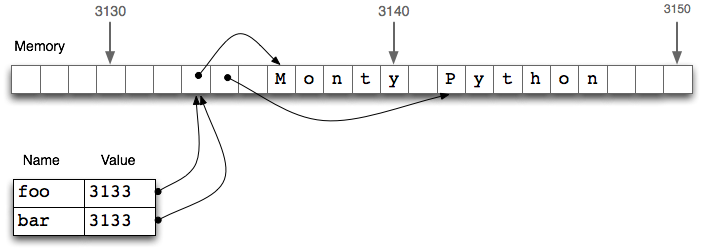
让我们做更多的实验,通过创建一个持有空链表的变量 empty,然后在下一行使用它三次。
>>> empty = []>>> nested = [empty, empty, empty]>>> nested[[], [], []]>>> nested[1].append('Python')>>> nested[['Python'], ['Python'], ['Python']]改变链表中嵌套链表内的一个项目,它们全改变了。这是因为三个元素中的每一个实际上都只是一个内存中的同一链表的引用。
当我们分配一个新值给链表中的一个元素时,它并不会传送给其他元素:
>>> nested = [[]] * 3>>> nested[1].append('Python')>>> nested[1] = ['Monty']>>> nested[['Python'], ['Monty'], ['Python']]我们一开始用含有 3 个引用的链表,每个引用指向一个空链表对象。然后,我们通过给它追加’Python’,修改这个对象,结果变成包含 3 个到一个链表对象[‘Python’]的引用的链表。下一步,我们使用到一个新对象[‘Monty’]的引用来覆盖三个元素中的一个。这最后一步修改嵌套链表内的 3 个对象引用中的 1 个。
等式
Python 提供了两种方法来检查一对项目是否相同。is 操作符测试对象的标识符。
>>> size = 5>>> python = ['Python']>>> snake_nest = [python] * size>>> snake_nest[0] == snake_nest[1] == snake_nest[2] == snake_nest[3] == snake_nest[4]True>>> snake_nest[0] is snake_nest[1] is snake_nest[2] is snake_nest[3] is snake_nest[4]True条件语句
在 if 语句的条件部分,一个非空字符串或链表被判定为真,而一个空字符串或链表的被判定为假。
序列
序列上的操作
我们可以在这些序列类型之间相互转换。例如:tuple(s)将任何种类的序列转换成一个元组,list(s)将任何种类的序列转换成一个链表。
zip()取两个或两个以上的序列中的项目,将它们“压缩”打包成单个的配对链表。给定一个序列 s ,enumerate(s)返回一个包含索引和索引处项目的配对。
>>> words = ['I', 'turned', 'off', 'the', 'spectroroute']>>> tags = ['noun', 'verb', 'prep', 'det', 'noun']>>> zip(words, tags)[('I', 'noun'), ('turned', 'verb'), ('off', 'prep'),('the', 'det'), ('spectroroute', 'noun')]>>> list(enumerate(words))[(0, 'I'), (1, 'turned'), (2, 'off'), (3, 'the'), (4, 'spectroroute')]合并不同类型的序列
在 Python 中,列表是可变的,而元组是不可变的。换句话说,列表可以被修改,而元组不能。
一个链表是一个典型的具有相同类型的对象的序列,它的 长度是任意的 。我们经常使用链表保存词序列。相反,一个元组通常是不同类型 的对象的集合, 长度固定 。我们经常使用一个元组来保存一个纪录:与一些实体相关的不同字段的集合。
产生器表达式
max([w.lower() for w in nltk.word_tokenize(text)]) max(w.lower() for w in nltk.word_tokenize(text))第二行使用了产生器表达式。这不仅仅是标记(形式上看起来)方便:在许多语言处理的案例中,产生器表达式会更高效。在第一行中,链表对象的存储空间必须在 max()的值被计算之前分配。如果文本非常大的,这将会很慢。在第二行中,数据流向调用它的函数。而无需存储迄今为止的最大值以外的任何值。
函数
- 函数定义为变量创建了一个新的局部的范围。
- 当你在一个函数体内部使用一个现有的名字时,Python 解释器先尝试按照函数本地的名字来解释。如果没有发现,解释器检查它是否是一个模块内的全局名称。如果没有成功 ,最后,解释器会检查是否是 Python 内置的名字。这就是所谓的名称解析的 LGB 规则:本地(local),全局(global),然后内置(built-in)。
- Python 允许我们传递一个函数作为另一个函数的参数。
- Python 提供了更多的方式来定义函数作为其他函数的参数,即所谓的lambda 表达式 。
- 必须确保未命名的参数在命名的参数前面。
Python库
Numpy
- 4.NLTK之编写结构化程序
- 8.NLTK之分析句子结构
- 第四章 编写结构化程序
- NLTK05《Python自然语言处理》code04 编写结构化程序
- Python自然语言处理 4 编写结构化程序
- NLTK之WordNet 接口
- jvm之java程序从编写到执行的结构链路
- 编写自定义PE结构的程序
- 编写自定义PE结构的程序
- openwrt的结构 与 编写 HelloWorld程序
- 3.7、编写顺序结构的程序
- 3.12、编写选择结构的程序
- openwrt的结构与编写 HelloWorld程序
- openwrt的结构 与 编写 HelloWorld程序
- openwrt的结构 与 编写 HelloWorld程序
- openwrt的结构 与 编写 HelloWorld程序
- C++编写选择结构的程序
- NLTK
- 10、二进制中1的个数
- SpringMVC文件上传
- 树莓派平台简介
- Git远程操作详解(转)
- 推荐系统:技术、评估及高效算法 第11章
- 4.NLTK之编写结构化程序
- linux中w命令使用
- 个人记录-LeetCode 77. Combinations
- Android利用Achartengine实现实时曲线图
- Android Bluetooth 蓝牙通信(二)
- Thread类和Runnable接口的区别
- Spring声明式事务原理分析
- 最全资料整理, 教你如何用HEXO搭建十分cool的属于自己的网站
- 调试botguard


