libsvm 参数以及计算测试点相似度
来源:互联网 发布:淘宝保证金解冻步骤 编辑:程序博客网 时间:2024/06/10 06:08
最近一个图像识别项目里需要对分类的结果进行打分,因为使用的是libsvm3.12,一开始决定直接将svm_predict_values函数的dec_values作为评分返回,后来研究了之后才觉得里面有的东西还挺有趣。
首先介绍一下SVM中的多分类方法。目前SVM多分类流行的策略有one-against-all以及one-against-one两种,libsvm中的多分类是采用的one-against-one策略,其他有一些开源库如SVM-Light采用one-against-all。对于N类的数据,one-against-all建立N个分类器,但有一些缺点,如:数据集偏斜、分类重叠、不可分现象等(参见:http://www.blogjava.net/zhenandaci/archive/2009/03/26/262113.html);one-against-one建立N*(N-1)/2个分类器,每个分类器对样本进行投票,票数最多对应的类别作为识别结果。在分类器里用来决定投票给谁的依据,就是decision value,也就是libsvm中的dec_values。
以下考虑线性核的情况。
直观上以为decision value就是样本点到最优超平面的距离,其实并不是,分析如下:
假设计算出的分类决策面能将两类(P, N)完全分开,则有:

分类间隔为




另外decision value也跟概率无关(用在回归时确实表示概率,但在分类时则不是)。根据我看到的说法,由decision value的计算式,它的取值范围应该是在实数域上的(这是在一篇外国的硕士论文上看到的说法,见Andreas Vlachos的《Active Learning with Support Vector Machines》,2004)。不过我觉得这样说好像也不对,假设我们对样本特征数据做了scale,那么所有的样本点就被限定在一个有限空间里,既然最优超平面也是在这个空间里确定的,那么只要所有的测试样本点做了scale处理,到最优超平面的距离肯定是有上界的。具体这个上界怎么去推导,暂时还不懂。
多分类时one-against-one的策略里有一点小问题就是,各个二分类器的计算得出的decision value其实是没有可比性的,而one-against-all没有这个问题。为什么这么说呢?这是因为:1)one-against-all各个分类器训练参数跟数据集是一样的,只不过是label做了改变。所以比较不同分类器的decision value是合法的;2)one-against-one各个分类器的训练时,用的是不同数据集,因此分类器之间的decision value不能直接比较。按照我的理解,前者是在同一个空间里比较,后者就不是了。
按照在国内外论坛上别人的说法,甚至不能给decision value附件任何含义,除了线性核的SVM里可以用decision value进一步计算距离(参见http://stackoverflow.com/questions/11030253/decision-values-in-libsvm ,不过我觉得老外也未必都是对的)。稳妥的说法就是decision value可以用来作为分类结果置信度的评价。
回到对分类结果进行打分的问题上来,在网上查找资料时,看到有人也做了类似的工作,见:http://blog.csdn.net/zhzhl202/article/details/7438313 。他的方法是: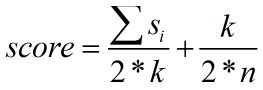 ,其中k为所有支持判别类得个数,n为所有类别个数,si 为所有支持判别类的分数。我觉得这种方法兼顾了投票数与decision value两方面的信息,比直接累加dec_values然后取平均肯定要好,但是公式的由来,似乎又没有坚实的理论依据。不过没有其他好方法之前,我项目里暂时就这么用了。
,其中k为所有支持判别类得个数,n为所有类别个数,si 为所有支持判别类的分数。我觉得这种方法兼顾了投票数与decision value两方面的信息,比直接累加dec_values然后取平均肯定要好,但是公式的由来,似乎又没有坚实的理论依据。不过没有其他好方法之前,我项目里暂时就这么用了。
补充:
这个函数是libsvm库中比较新的函数,用于对现有nr_class个类做出概率估计(我理解就是属于这个类别的概率是多少,从数学角度是样本与分类面的距离?)
1)进入到svm_predict_probability函数里面,注意到里面有一个选择语句,svm的类型要选择C_SVC或NU_SVC,并且probA和probB的指针不能为空。svm类型很好搞定,但是对于probA和probB我之前并没有见到过,他们是model中的参数,当我们不涉及到概率是model中没有这两个值。后来经考察资料,当options中的-b参数设置为1时,才会涉及到probA和probB。所以要想求概率估计,第一点要注意的是-b参数要设为1.
2)svm_predict_probability函数与svm_predict函数在接口上只有第三个参数prob_estimates不同,其余两个都相同,所以这里只说明第三个参数的作用。prob_estimates里实际上存放的就是估计出的概率,比如说m分类问题,那prob_estimates就是一个1*m列的矩阵,没列代表属于相对类别的概率。这个相对类别是与svm输出结构体中的Lable相对应的!
3)说完参数就剩下返回值啦,比较简单,返回的就是最大概率对应的类别标签。如果二分类问题那就是1或-1.
最后总结一下,如果熟悉svm_predict的话,那么只有二点不同,一是-b参数要设成1,二是函数接口多了个概率矩阵,其他的只要把参数传进去就可以了。以上只是在应用这个函数过程中的体会,如有不对请指正。
- libsvm 参数以及计算测试点相似度
- 影片内容相似度计算关键点
- 计算图像相似度
- 计算字符串相似度
- 句子相似度计算
- 图像相似度计算
- 相似度计算
- 字符串相似度计算
- 图像相似度计算
- 图像相似度计算
- 文本相似度计算
- 相似度计算概述
- 图像相似度计算
- 相似度计算
- 计算相似度方法
- 舆情相似度计算
- 图像相似度计算
- 字符串相似度计算
- 用基类指针实现多态
- 刘维尔传记资料
- Android的Crash日志记录
- struts 获取参数(Action 属性接受参数)
- 等概率随机函数的实现
- libsvm 参数以及计算测试点相似度
- C#点滴积累之过程篇
- 18. 4Sum
- 清橙1485 Catch The Penguins 抓企鹅
- HDU1051 Wooden Sticks(贪心)
- c语言学习日志 day4
- 脚本—shell
- 基于Matlab的神经网络结合遗传算法在非线性函数极值寻优中的应用
- 7.5.6


