ES权威指南_01_get start_02 Life Inside a Cluster(ES集群内部原理)
来源:互联网 发布:淘宝搜不到网盘会员 编辑:程序博客网 时间:2024/06/05 19:38
https://www.elastic.co/guide/en/elasticsearch/guide/current/distributed-cluster.html
介绍 Elasticsearch 在分布式环境中的运行原理。
关键词:cluster、node、shard、ES如何scale out、如何处理硬件故障。
Although this chapter is not required reading—you can use Elasticsearch for a long time without worrying about shards, replication, and failover—it will help you to understand the processes at work inside Elasticsearch.
做为一般用户,是非必读章节。便于了解ES内部工作过程。先大概了解,不时再看。
Elasticsearch is built to be always available, and to scale with your needs. Scale can come from buying bigger servers (vertical scale, or scaling up) or from buying more servers (horizontal scale, or scaling out).
ES总是可用,按需扩容。
扩展方式:
- 纵向(垂直扩容,纵向扩容,更高配置机器),终归有瓶颈。
- 横向(水平扩容,横向扩容,更多机器),更常见、实用。
With most databases, scaling horizontally usually requires a major overhaul(大修、检查) of your application to take advantage of these extra boxes. In contrast, Elasticsearch is distributed by nature: it knows how to manage multiple nodes to provide scale and high availability. This also means that your application doesn’t need to care about it.
对于大多数的数据库而言,通常需要对应用程序进行非常大的改动,才能利用上横向扩容的新增资源。 与之相反的是,ElastiSearch天生就是 分布式的 ,它知道如何通过管理多节点来提高扩容性和可用性。
这也意味着你的应用无需关注这个问题。
1 An Empty Cluster
A node is a running instance of Elasticsearch, while a cluster consists of one or more nodes with the same cluster.name that are working together to share their data and workload.
As nodes are added to or removed from the cluster, the cluster reorganizes itself to spread the data evenly(数据在各节点均衡).
One node in the cluster is elected to be the master node, which is in charge of managing cluster-wide changes like creating or deleting an index, or adding or removing a node from the cluster.
The master node does not need to be involved in document-level changes or searches, which means that having just one master node will not become a bottleneck as traffic grows.
最佳实践:一个集群中,单独分出N个节点做master节点,避免弄成主数节点。
节点是集群感知的:As users, we can talk to any node in the cluster, including the master node. Every node knows where each document lives and can forward our request directly to the nodes that hold the data we are interested in.
网关节点(协调节点):Whichever node we talk to manages the process of gathering the response from the node or nodes holding the data and returning the final response to the client. It is all managed transparently by Elasticsearch.
最佳实践:一个集群中有单独的网关节点,即ES官方说的client node,非master、非data,但因集群感知,知道数据在哪,客户端和网关节点通信。挂了重启即可,无需担心数据丢失。即时扩容可增加搜索能力
2 Cluster Health
GET _cluster/health结果:{ "cluster_name": "elasticsearch",//集群名,同名节点在一个集群 "status": "green", "timed_out": false, "number_of_nodes": 1,// 所有节点总数:数据、网关、主节点 "number_of_data_nodes": 1, //总节点中的数据节点数 "active_primary_shards": 0, //所有active的分片数中主分片数 "active_shards": 0, //所有active的分片数:包含主、副。 "relocating_shards": 0, //重平衡 "initializing_shards": 0, //初始 "unassigned_shards": 0 //未分配} status有3种状态:
- green
All primary and replica shards are active. - yellow
All primary shards are active(up and running ,the cluster is capable of serving any request successfully), but not all replica shards are active. - red,必须处理
Not all primary shards are active.
3 Add an Index
想给ES添加data ,需要一个index——a place to store related data.
index,是一个逻辑概念,一个逻辑的命名空间,指向一个或多个物理分片。
A shard is a low-level worker unit.
Inside a Shard :解释了一个shard是如何工作。
But for now it is enough to know that a shard is a single instance of Lucene, and is a complete search engine in its own right. Our documents are stored and indexed in shards, but our applications don’t talk to them directly. Instead, they talk to an index.
底层是shard,交互是index.
可以认为,shard是data的容器。随着集群扩容、缩容,ES将自动在节点间迁移shard,以使集群平衡。
A shard can be either a primary shard or a replica shard. Each document in your index belongs to a single primary shard.
一个主分片,技术上可存储 Integer.MAX_VALUE - 128(20亿左右) 个docs。所以,当一个索引的主分片数确定时,则该索引最多可容纳的docs是固定的。
The practical limit depends on your use case: the hardware you have, the size and complexity of your documents, how you index and query your documents, and your expected response times.
A replica shard is just a copy of a primary shard.容灾、增强读(搜索)能力。
主片:在建立索引时,一旦确定不可修改。
副本:任何时候都可修改。
The number of primary shards in an index is fixed at the time that an index is created, but the number of replica shards can be changed at any time.
只有一个节点:
PUT /blogs{ "settings" : { "number_of_shards" : 3, // 主片为3,通常建议2^N "number_of_replicas" : 1 //副本为1 }}此时,只有主分片分配,副本无法分配。
It doesn’t make sense to store copies of the same data on the same node.
4 Add Failover(增加副本来容错)
增加第2个节点,让各副本up and run.
5 Scale Horizontally(水平扩展)
增加第3个节点,集群重平衡各分片。
One shard each from Node 1 and Node 2 have moved to the new Node 3, and we have two shards per node, instead of three.
With our total of six shards (three primaries and three replicas), our index is capable of scaling out to a maximum of six nodes, with one shard on each node and each shard having access to 100% of its node’s resources.
每一shard是完全独立的搜索引擎。
Then Scale Some More(增强读能力):
But what if we want to scale our search to more than six nodes?
The number of primary shards is fixed at the moment an index is created. Effectively, that number defines the maximum amount of data that can be stored in the index. (The actual number depends on your data, your hardware and your use case.)
However, read requests—searches or document retrieval—can be handled by a primary or a replica shard, so the more copies of data that you have, the more search throughput you can handle.
The number of replica shards can be changed dynamically on a live cluster, allowing us to scale up or down as demand requires.
PUT /blogs/_settings{ "number_of_replicas" : 2}the blogs index now has nine shards: three primaries and six replicas.
注意: Just having more replica shards on the same number of nodes doesn’t increase our performance. You need to add hardware to increase throughput.
一个节点,对于同一编号的shard,无论主或副本,仅保留一个即可,太多的无意义。 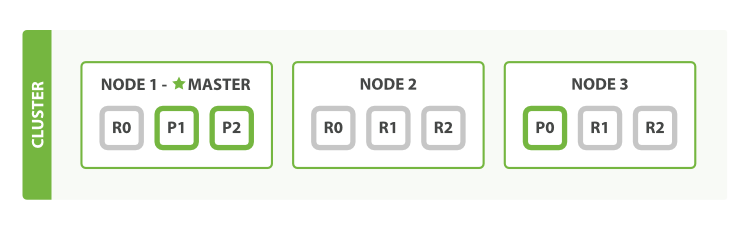
with the node configuration above, we can now afford to lose two nodes without losing any data.
6 Coping with Failure
当主分片丢失,副本会自动提升(promote)为主分片。
- ES权威指南_01_get start_02 Life Inside a Cluster(ES集群内部原理)
- ES权威指南_01_get start_11 Inside a Shard
- ES权威指南_01_get start_10 Index Management
- ES权威指南_01_get start_01 You Know, for Search…
- ES权威指南_01_get start_03 Data In, Data Out
- ES权威指南_01_get start_04 Distributed Document Store
- ES权威指南_01_get start_05 Searching—The Basic Tools
- ES权威指南_01_get start_06 Mapping and Analysis
- ES权威指南_01_get start_07 Full-Body Search
- ES权威指南_01_get start_08 Sorting and Relevance
- ES权威指南_01_get start_09 Distributed Search Execution
- es分片内部原理
- ES权威指南_05_Geolocation_02 Geohashes
- elasticsearch之life inside a cluster
- ES权威指南_04_aggs_01 High-Level Concepts
- ES权威指南_04_aggs_05 Scoping Aggs
- ES权威指南_04_aggs_07 Sorting Multivalue Buckets
- ES权威指南_04_aggs_11 Closing Thoughts
- SQL删除重复数据只保留一条
- Centos 6.5 安装 Atlassiana Crowd+JIRA+Confluence(Wiki)之三 JIRA篇(JIRA 6.3.6)
- 2016年总结
- ld3320的使用
- linux常用命令之 sed grep awk
- ES权威指南_01_get start_02 Life Inside a Cluster(ES集群内部原理)
- 数论之扩展欧几里得 (求解不定方程,线性同余,求解模的逆元) (但是加了一些自己的东西)
- ES权威指南_01_get start_03 Data In, Data Out
- oracle 管理员不用密码登录
- AAC的ADTS头文件信息介绍
- unittest流程
- 御剑web后台敏感目录扫描
- PAT甲级1060
- Maven项目管理工具初体验


