ES权威指南_01_get start_04 Distributed Document Store
来源:互联网 发布:status monitor软件 编辑:程序博客网 时间:2024/06/15 01:32
https://www.elastic.co/guide/en/elasticsearch/guide/current/distributed-docs.html
深入原理了解分布式存储。
1 Routing a Doc to a Shard
When you index a document, it is stored on a single primary shard.
shard = hash(routing) % number_of_primary_shardsrouting 默认值是_id 。计算结果的范围—— ” 0 to number_of_primary_shards - 1”
This explains why the number of primary shards can be set only when an index is created and never changed.
Designing for Scale.
All document APIs (get, index, delete, bulk, update, and mget) accept a routing parameter.
A custom routing value could be used to ensure that all related documents—for instance, all the documents belonging to the same user—are stored on the same shard.
2 How Primary and Replica Shards Interact
We can send our requests to any node(coordinating node) in the cluster. Every node is fully capable of serving any request. Every node knows the location of every doc in the cluster and so can forward requests directly to the required node.
提示:When sending requests, it is good practice to round-robin through all the nodes in the cluster, in order to spread the load.
待完善…
3 Creating, Indexing, and Deleting a Doc
Create, index, and delete requests are write operations, which must be successfully completed on the primary shard before they can be copied to any associated replica shards,
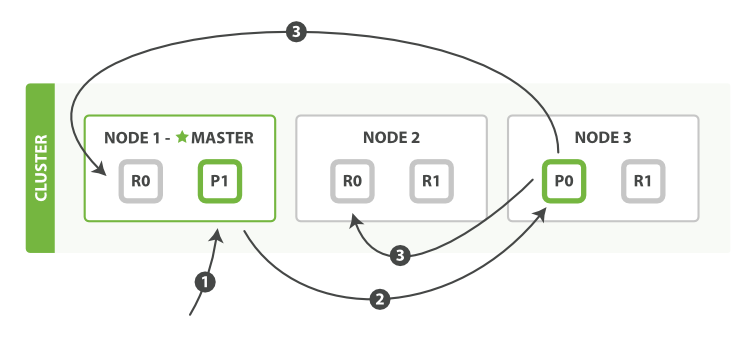
步骤:
- The client sends a create, index, or delete request to Node 1.
- The node uses the doc’s _id to determine that the doc belongs to shard 0. It forwards the request to Node 3, where the primary copy of shard 0 is currently allocated.
- Node 3 executes the request on the primary shard. If it is successful, it forwards the request in parallel to the replica shards on Node 1 and Node 2. Once all of the replica shards report success, Node 3 reports success to the coordinating node, which reports success to the client.
By the time the client receives a successful response, the document change has been executed on the primary shard and on all replica shards. Your change is safe.
可控选项:
consistency
By default, the primary shard requires a quorum, or majority, of shard copies (where a shard copy can be a primary or a replica shard) to be available before even attempting a write operation.Note that the
number_of_replicasis the number of replicas specified in the index settings, not the number of replicas that are currently active.quorum = int( (primary + number_of_replicas) / 2 ) + 1- one
- all ,primary and all replicas.
- quorum,默认,过半加1,若不满足则不能index or delete。
- timeout,默认1分钟,不指定单位是毫秒,可指定如10s表示10秒
What happens if insufficient shard copies are available? Elasticsearch waits, in the hope that more shards will appear.
注意:
A new index has 1 replica by default, which means that two active shard copies should be required in order to satisfy the need for a quorum. However, these default settings would prevent us from doing anything useful with a single-node cluster. To avoid this problem, the requirement for a quorum is enforced only when number_of_replicas is greater than 1.
4 Retrieving a Doc
A doc can be retrieved from a primary shard or from any of its replicas,
For read requests, the coordinating node will choose a different shard copy on every request in order to balance the load; it round-robins through all shard copies.
shard copy can be a primary or a replica。
It is possible that, while a document is being indexed, the document will already be present on the primary shard but not yet copied to the replica shards. In this case, a replica might report that the document doesn’t exist, while the primary would have returned the document successfully.
Once the indexing request has returned success to the user, the document will be available on the primary and all replica shards.
5 Partial Updates to a Doc
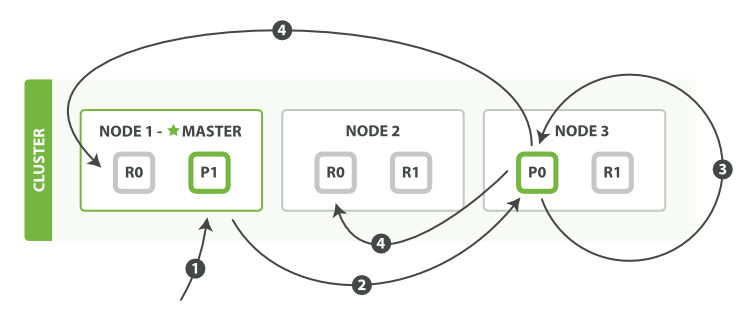
- The client sends an update request to Node 1.
- It forwards the request to Node 3, where the primary shard is allocated.
- Node 3 retrieves the document from the primary shard, changes the JSON in the _source field, and tries to reindex the document on the primary shard. If the document has already been changed by another process, it retries step 3 up to retry_on_conflict times, before giving up.
- If Node 3 has managed to update the document successfully, it forwards the new version of the document in parallel to the replica shards on Node 1 and Node 2 to be reindexed. Once all replica shards report success, Node 3 reports success to the coordinating node, which reports success to the client.
The update API also accepts the routing, consistency, and timeout parameters
Document-Based Replication【基于doc的复制】
When a primary shard forwards changes to its replica shards, it doesn’t forward the update request. Instead it forwards the new version of the full document. Remember that these changes are forwarded to the replica shards asynchronously, and there is no guarantee that they will arrive in the same order that they were sent.
可能乱序,但是完整的doc。
If Elasticsearch forwarded just the change, it is possible that changes would be applied in the wrong order, resulting in a corrupt document.
6 Multidocument Patterns【mget 、bulk:读、写】
The patterns for the mget and bulk APIs are similar to those for individual documents. The difference is that the coordinating node knows in which shard each document lives. It breaks up the multidocument request into a multidocument request per shard, and forwards these in parallel to each participating node.
Once it receives answers from each node, it collates their responses into a single response, which it returns to the client.
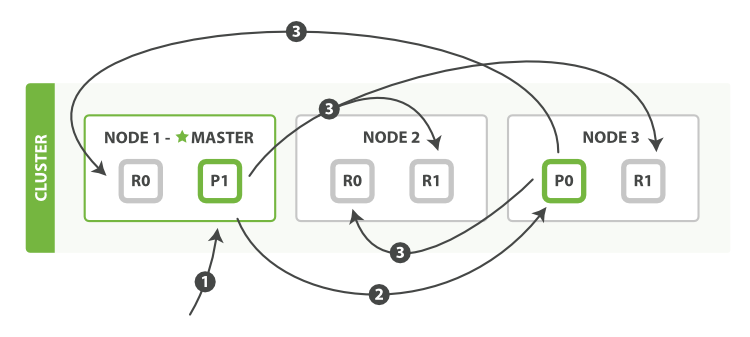
- The client sends a bulk request to Node 1.
- Node 1 builds a bulk request per shard, and forwards these requests in parallel to the nodes hosting each involved primary shard.
- The primary shard executes each action serially, one after another. As each action succeeds, the primary forwards the new document (or deletion) to its replica shards in parallel, and then moves on to the next action. Once all replica shards report success for all actions, the node reports success to the coordinating node, which collates the responses and returns them to the client.
Why the Funny Format?
It uses the newline characters to identify and parse just the small action/metadata lines in order to decide which shard should handle each request.
These raw requests are forwarded directly to the correct shard. There is no redundant copying of data, no wasted data structures. The entire request process is handled in the smallest amount of memory possible.
- ES权威指南_01_get start_04 Distributed Document Store
- ES权威指南_01_get start_09 Distributed Search Execution
- ES权威指南_01_get start_10 Index Management
- ES权威指南_01_get start_01 You Know, for Search…
- ES权威指南_01_get start_03 Data In, Data Out
- ES权威指南_01_get start_05 Searching—The Basic Tools
- ES权威指南_01_get start_06 Mapping and Analysis
- ES权威指南_01_get start_07 Full-Body Search
- ES权威指南_01_get start_08 Sorting and Relevance
- ES权威指南_01_get start_11 Inside a Shard
- ES权威指南_01_get start_02 Life Inside a Cluster(ES集群内部原理)
- ES权威指南_05_Geolocation_02 Geohashes
- [ElasticSearch]分布式文档存储(Distributed Document Store)
- ES权威指南_04_aggs_01 High-Level Concepts
- ES权威指南_04_aggs_05 Scoping Aggs
- ES权威指南_04_aggs_07 Sorting Multivalue Buckets
- ES权威指南_04_aggs_11 Closing Thoughts
- ES权威指南_05_Geolocation_01 Geo Points
- ASP.NET MVC分页问题解决
- SQLSERVER存储过程(一)
- Creating CocoaPods
- AndroidStudio 集成高德地图,无法实例化com.amap.api.maps.MapView。
- windows系统如何设置串口
- ES权威指南_01_get start_04 Distributed Document Store
- 三星公布Note7燃损原因未来创新的同时将更加注重安全检查
- 创业布局移动端App,应该先做Android还是iOS?
- Dynamic Library 动态库
- Android客户端和服务端如何使用Token和Session
- webservice篇之简单开发(二)
- SLF4J官网手册个人翻译
- 汇编语言王爽(第二版)课后习题答案
- 手动写一个Behavior Designer任务节点


