Sigmoid neurons Sigmoid神经元
Learning algorithms sound terrific. But how can we devise such algorithms for a neural network? Suppose we have a network of perceptrons that we’d like to use to learn to solve some problem. For example, the inputs to the network might be the raw pixel data from a scanned, handwritten image of a digit. And we’d like the network to learn weights and biases so that the output from the network correctly classifies the digit. To see how learning might work, suppose we make a small change in some weight (or bias) in the network. What we’d like is for this small change in weight to cause only a small corresponding change in the output from the network. As we’ll see in a moment, this property will make learning possible. Schematically, here’s what we want (obviously this network is too simple to do handwriting recognition!):
学习算法听起来恐怖。但是我们怎么为神经网络产生这种算法呢?假设我们有一个感知器网络,我们想要使用它来解决一些问题。例如,这个网络的输入也许是扫描手写数字图片得到的像素数据。我们想要这个网络学习出权重和偏移量使得网络的输出可以正确的分类出数字。来看看学习算法是如何工作的,假设我们小小改变了一些网络中的权重(或者偏移量)。我们想要得到的是对权重的小小改变仅仅在输出产生一个对应的小小改变。正如这个时候我们看到的,这个性质使得学习成为可能。大略上,这就是我们想要的(显然这个网络对于笔迹识别来说太简单了!)。
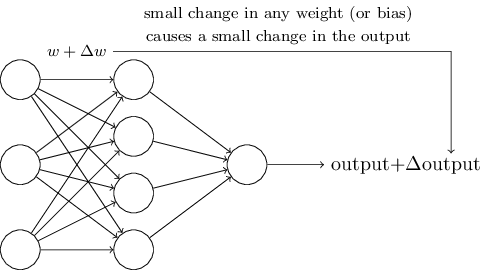
If it were true that a small change in a weight (or bias) causes only a small change in output, then we could use this fact to modify the weights and biases to get our network to behave more in the manner we want. For example, suppose the network was mistakenly classifying an image as an “8” when it should be a “9”. We could figure out how to make a small change in the weights and biases so the network gets a little closer to classifying the image as a “9”. And then we’d repeat this, changing the weights and biases over and over to produce better and better output. The network would be learning.
如果权重(或者偏移量)的微小改变仅仅使得输出小小改变是真的,那么我们可以利用这个性质来修改权重和偏移量使得我们的网络表现出更多我们想要的性质。举个例子,假设网络错误的将一张“9”的图片分类为“8”了。我们可以指出如何小小改变权重和偏移量使得网络更倾向于将这张图片分类为“9”。接下来我们不断重复这个步骤,不断调整权重和偏移量产生更好的结果。网络就这样学习了。
The problem is that this isn’t what happens when our network contains perceptrons. In fact, a small change in the weights or bias of any single perceptron in the network can sometimes cause the output of that perceptron to completely flip, say from 0 to 1. That flip may then cause the behaviour of the rest of the network to completely change in some very complicated way. So while your “9” might now be classified correctly, the behaviour of the network on all the other images is likely to have completely changed in some hard-to-control way. That makes it difficult to see how to gradually modify the weights and biases so that the network gets closer to the desired behaviour. Perhaps there’s some clever way of getting around this problem. But it’s not immediately obvious how we can get a network of perceptrons to learn.
问题是当我们的网络中包含感知器的话这种情况就不会发生。事实上,网络中某个感知器的权重和偏移量的微小改变有时候会使得感知器输出彻底翻转,也就是从0 变成1。基于某些复杂的情况,这个翻转接下来使得网络的其他部分产生根本性变化。因此这个“9”现在也许被正确归类了,但是基于某种很难控制的情况,网络识别其他图片的结果很大可能上发生根本性转变。这个导致发现如何逐渐修改权重和偏移量以使得网络逼近设计性能。也许存在某种聪明的方法来解决这个问题,但是我们不能迅速清晰的学习出一个感知器网络。
We can overcome this problem by introducing a new type of artificial neuron called a sigmoid neuron. Sigmoid neurons are similar to perceptrons, but modified so that small changes in their weights and bias cause only a small change in their output. That’s the crucial fact which will allow a network of sigmoid neurons to learn.
我们可以通过构造一种新的人工神经元sigmoid神经元来克服这个问题。sigmoid神经元和感知器非常像,不过权重和偏移量的微小改变只会使得它的输出产生微小改变。这个关键特性使得sigmoid神经网络可以学习。
Okay, let me describe the sigmoid neuron. We’ll depict sigmoid neurons in the same way we depicted perceptrons:
好的,让我们来描述一下sigmoid神经元。我们将用类似于描述感知器的方式来描述sigmoid神经元:

Just like a perceptron, the sigmoid neuron has inputs, x1,x2,…But instead of being just 0 or 1, these inputs can also take on any values between 0 and 1. So, for instance, 0.638… is a valid input for a sigmoid neuron. Also just like a perceptron, the sigmoid neuron has weights for each input, w1,w2,…, and an overall bias, b. But the output is not 0 or 1. Instead, it’s σ(w⋅x+b), where σ is called the sigmoid function (Incidentally, σ is sometimes called the logistic function, and this new class of neurons called logistic neurons. It’s useful to remember this terminology, since these terms are used by many people working with neural nets. However, we’ll stick with the sigmoid terminology.), and is defined by:
就像感知器,sigmoid神经元有多个输入x1,x2,…,但是并不只能输入0或者1,可以输入任何在0和1 之间的值。所以,如0.638… 是sigmoid神经元可接受的输入。同样和感知器一样,sigmoid神经元的每个输入都有一个权重w1,w2,… 和一个偏移量b。但是输出不是0或者1。相反,输出是σ(w⋅x+b),这里σ 被称为sigmoid函数(σ 有时候被称为logistic函数,同时这类新的神经元被称为logistic神经元。记住这个术语是非常有用的,因为许多使用神经网络的人在使用这些措辞。但是,我们坚持使用sigmoid的名称),sigmoid定义为:
σ(z)≡11+e−z.(3)
To put it all a little more explicitly, the output of a sigmoid neuron with inputs x1,x2,…x1,x2,…, weights w1,w2,…w1,w2,…, and bias bb is
11+exp(−∑jwjxj−b).(4)
At first sight, sigmoid neurons appear very different to perceptrons. The algebraic form of the sigmoid function may seem opaque and forbidding if you’re not already familiar with it. In fact, there are many similarities between perceptrons and sigmoid neurons, and the algebraic form of the sigmoid function turns out to be more of a technical detail than a true barrier to understanding.
第一眼看上去,sigmoid神经元和感知器差别甚大。sigmoid函数的代数表达式也许看起来复杂且可怕,如果你不是已经熟悉它的话。事实上,感知器和sigmoid神经元之间还是有许多相似的地方,并且相比它带来的理解上的困难,sigmoid函数的代数表达式给出了更多的技术细节。
To understand the similarity to the perceptron model, suppose z≡w⋅x+b is a large positive number. Then e−z≈0 and so σ(z)≈1. In other words, when z=w⋅x+b is large and positive, the output from the sigmoid neuron is approximately 1, just as it would have been for a perceptron. Suppose on the other hand that z=w⋅x+b is very negative. Then e−z→∞, and σ(z)≈0. So when z=w⋅x+b is very negative, the behaviour of a sigmoid neuron also closely approximates a perceptron. It’s only when w⋅x+b is of modest size that there’s much deviation from the perceptron model.
为了理解和感知器模型的相似性,假设z≡w⋅x+b 的结果是一个大的正数。那么e−z≈0 且σ(z)≈1。换句话说,当z=w⋅x+b 很大且为正时,sigmoid神经元的输出近似于1,就像感知器的结果。另一方面假设z=w⋅x+b 是大的负数。那么e−z→∞,并且σ(z)≈0。因此当z=w⋅x+b 是个大负数时,sigmoid神经元的输出也近似于感知器。只有当w⋅x+b 不那么大时,它才和感知器的输出有大的区别。
What about the algebraic form of σ? How can we understand that? In fact, the exact form of σ isn’t so important - what really matters is the shape of the function when plotted. Here’s the shape:
σ 的代数表达式又是怎样的呢?我们能怎么理解它呢?事实上,σ 的精确形式并不那么重要——重要的是它的图像。这里是它的图像:

This shape is a smoothed out version of a step function:
这是平滑过的阶跃函数:

If σ had in fact been a step function, then the sigmoid neuron would be a perceptron, since the output would be 1 or 0 depending on whether w⋅x+b was positive or negative (Actually, when w⋅x+b the perceptron outputs 0, while the step function outputs 1. So, strictly speaking, we’d need to modify the step function at that one point. But you get the idea.) . By using the actual σ function we get, as already implied above, a smoothed out perceptron. Indeed, it’s the smoothness of the σ function that is the crucial fact, not its detailed form. The smoothness of σ means that small changes Δwj in the weights and Δb in the bias will produce a small change Δoutput in the output from the neuron. In fact, calculus tells us that Δoutput is well approximated by
如果σ 是个阶跃函数,那么sigmoid神经元将变成感知器,因为根据w⋅x+b 是正还是负,输出不是1 就是0。(实际上,w⋅x+b 使得感知器输出0 时,阶跃函数输出1。因此,严格来说,我们在这一点上需要修改阶跃函数。但是你理解就好)通过使用实际上的σ 函数,我们得到一个平滑输出的感知器。更进一步,σ 函数的平滑性是关键因素,而不是它的具体形式。σ 函数的平滑性意味着权重的微小变化Δwj 和偏移量的微小变化Δb 将促使神经元的输出产生微小变化Δoutput。事实上,微积分告诉我们Δoutput 近似于:
Δoutput≈∑j∂output∂wjΔwj+∂output∂bΔb,(5)
where the sum is over all the weights,
wj, and
∂output/∂wjand
∂output/∂b denote partial derivatives of the
output with respect to
wj and
b, respectively. Don’t panic if you’re not comfortable with partial derivatives! While the expression above looks complicated, with all the partial derivatives, it’s actually saying something very simple (and which is very good news):
Δoutput is a linear function of the changes
Δwj and
Δb in the weights and bias. This linearity makes it easy to choose small changes in the weights and biases to achieve any desired small change in the output. So while sigmoid neurons have much of the same qualitative behaviour as perceptrons, they make it much easier to figure out how changing the weights and biases will change the output.
这里是对所有权重
wj 求和,并且
∂output/∂wj 和
∂output/∂b 表示
output 对
wj 和
b 的偏导数。不用为偏导数而痛苦!当然上面的表达式看起来很复杂,用了偏导数,但是它事实上说的事情很简单(这是一个非常好的消息):
Δoutput 是
Δwj 和
Δb 的线性方程。这种线性特性使得很容易微调权重和偏置来一点点的改变输出。既然sigmoid神经元和感知器有着非常类似的特性,这就使得推导如何改变权重和偏置来改变输出变得十分简单。
If it’s the shape of σ which really matters, and not its exact form, then why use the particular form used for σ in Equation (3)? In fact, later in the book we will occasionally consider neurons where the output is f(w⋅x+b) for some other activation function f(⋅). The main thing that changes when we use a different activation function is that the particular values for the partial derivatives in Equation (5) change. It turns out that when we compute those partial derivatives later, using σ will simplify the algebra, simply because exponentials have lovely properties when differentiated. In any case, σ is commonly-used in work on neural nets, and is the activation function we’ll use most often in this book.
既然σ 的图像而不是表达式这么重要,在等式(3)中为什么要使用σ 的精确表达式?实际上,在本书的后面章节我们偶尔才会考虑在其他的激活函数f(⋅) 下神经元的输出是f(w⋅x+b)。当我们是使用不同的激活函数时,主要的改变是等式(5)的特定形式下的具体值。在我们计算这些特定形式的时候使用σ 将简化表达式,这是因为指数在微分时有着优秀的特性。无论如何,σ 在神经网络中被广泛使用,而且是本书中使用最多的激活函数。
How should we interpret the output from a sigmoid neuron? Obviously, one big difference between perceptrons and sigmoid neurons is that sigmoid neurons don’t just output 0 or 1. They can have as output any real number between 0 and 1, so values such as 0.173… and 0.689… are legitimate outputs. This can be useful, for example, if we want to use the output value to represent the average intensity of the pixels in an image input to a neural network. But sometimes it can be a nuisance. Suppose we want the output from the network to indicate either “the input image is a 9” or “the input image is not a 9”. Obviously, it’d be easiest to do this if the output was a 0 or a 1, as in a perceptron. But in practice we can set up a convention to deal with this, for example, by deciding to interpret any output of at least 0.5 as indicating a “9”, and any output less than 0.5 as indicating “not a 9”. I’ll always explicitly state when we’re using such a convention, so it shouldn’t cause any confusion.
我们如何解读sigmoid神经元的输出呢?很明显,感知器和sigmoid神经元之间的一个大不同是sigmoid神经元不是仅仅输出0 或者1。它可以输出0至1 之间的任意实数,例如 0.173…和0.689… 都是合法的输出。这可以是有用的,例如如果我们把一张图片输出神经网络,我们想用输出来表征平均像素明暗度时。但是有时候这个确实讨厌的。设想我们想从网络输出“输入的图片是9”或者“输入的图片不是9”。显然如果输出是0 或者1 这个很容易做到。但是在实践中我们可以设置一个约定来处理这个情况,例如将输出大于等于0.5 的解释为“是9”,输出小于0.5 的解释为“不是9”。当我们用这样的约定的时候我通常会明确说明,因此它不会造成任何混淆。
Exercises
Sigmoid neurons simulating perceptrons, part I
Suppose we take all the weights and biases in a network of perceptrons, and multiply them by a positive constant, c>0. Show that the behaviour of the network doesn’t change.
设想我们把一个感知器网络的所有权重和偏置都乘以一个正常数c>0。证明这个网络的特性不会改变。
Sigmoid neurons simulating perceptrons, part II
Suppose we have the same setup as the last problem - a network of perceptrons. Suppose also that the overall input to the network of perceptrons has been chosen. We won’t need the actual input value, we just need the input to have been fixed. Suppose the weights and biases are such that w⋅x+b≠0 for the input x to any particular perceptron in the network. Now replace all the perceptrons in the network by sigmoid neurons, and multiply the weights and biases by a positive constant c>0. Show that in the limit as c→∞ the behaviour of this network of sigmoid neurons is exactly the same as the network of perceptrons. How can this fail when w⋅x+b=0 for one of the perceptrons?
设想我们和上面的问题有相同的设定——一个感知器网络。设想网络中所有感知器的输入已经定好。我们不需要真的输入值,我们仅仅需要输入被确定。设想任意网络中的感知器的权重和偏置对于输入x满足w⋅x+b≠0。现在将网络中的所有感知器替换为sigmoid神经元,然后将所有的权重和偏置乘以一个正常数c>0。证明当c→∞ 这个sigmoid神经元网络的性质和感知器网络相同。只要一个感知器出现w⋅x+b=0,这个都不会成立。


