EasyPR--开发详解(8)文字定位
来源:互联网 发布:烟台龙口淘宝招聘网 编辑:程序博客网 时间:2024/05/20 09:06
今天我们来介绍车牌定位中的一种新方法--文字定位方法(MSER),包括其主要设计思想与实现。接着我们会介绍一下EasyPR v1.5-beta版本中带来的几项改动。
一. 文字定位法
在EasyPR前面几个版本中,最为人所诟病的就是定位效果不佳,尤其是在面对生活场景(例如手机拍摄)时。由于EasyPR最早的数据来源于卡口,因此对卡口数据进行了优化,而并没有对生活场景中图片有较好处理的策略。后来一个版本(v1.3)增加了颜色定位方法,改善了这种现象,但是对分辨率较大的图片处理仍然不好。再加上颜色定位在面对低光照,低对比度的图像时处理效果大幅度下降,颜色本身也是一个不稳定的特征。因此EasyPR的车牌定位的整体鲁棒性仍然不足。
针对这种现象,EasyPR v1.5增加了一种新的定位方法,文字定位方法,大幅度改善了这些问题。下面几幅图可以说明文字定位法的效果。


图1 夜间的车牌图像(左) , 图2 对比度非常低的图像(右)


图3 近距离的图像(左) , 图4 高分辨率的图像(右)
图1是夜间的车牌图像,图2是对比度非常低的图像,图3是非常近距离拍摄的图像,图4则是高分辨率(3200宽)的图像。
文字定位方法是采用了低级过滤器提取文字,然后再将其组合的一种定位方法。原先是利用在场景中定位文字,在这里利用其定位车牌。与在扫描文档中的文字不同,自然场景中的文字具有低对比度,背景各异,光亮干扰较多等情况,因此需要一个极为鲁棒的方法去提取出来。目前业界用的较多的是MSER(最大稳定极值区域)方法。EasyPR使用的是MSER的一个改良方法,专门针对文字进行了优化。在文字定位出来以后,一般需要用一个分类器将其中大部分的定位错误的文字去掉,例如ANN模型。为了获得最终的车牌,这些文字需要组合起来。由于实际情况的复杂,简单的使用普通的聚类效果往往不好,因此EasyPR使用了一种鲁棒性较强的种子生长方法(seed growing)去组合。
我在这里简单介绍一下具体的实现。关于方法的细节可以看代码,有很多的注释(代码可能较长)。关于方法的思想可以看附录的两篇论文。
 View Code
View Code
首先通过MSER提取区域,提取出的区域进行一个尺寸判断,滤除明显不符合车牌文字尺寸的。接下来使用一个文字分类器,将分类结果概率大于0.9的设为强种子(下图的绿色方框)。靠近的强种子进行聚合,划出一条线穿过它们的中心(图中白色的线)。一般来说,这条线就是车牌的中间轴线,斜率什么都相同。之后,就在这条线的附近寻找那些概率低于0.9的弱种子(蓝色方框)。由于车牌的特征,这些蓝色方框应该跟绿色方框距离不太远,同时尺寸也不会相差太大。蓝色方框实在绿色方框的左右查找的,有时候,几个绿色方框中间可能存在着一个方库,这可以通过每个方框之间的距离差推出来,这就是橙色的方框。全部找完以后。绿色方框加上蓝色与橙色方框的总数代表着目前在车牌区域中发现的文字数。有时这个数会低于7(中文车牌的文字数),这是因为有些区域即便通过MSER也提取不到(例如非常不稳定或光照变化大的),另外很多中文也无法通过MSER提取到(中文大多是不连通的,MSER提取的区域基本都是连通的)。所以下面需要再增加一个滑动窗口(红色方框)来寻找这些缺失的文字或者中文,如果分类器概率大于某个阈值,就可以将其加入到最终的结果中。最后,把所有文字的位置用一个方框框起来,就是车牌的区域。
想要通过中间图片进行调试程序的话,首先依次根据函数调用关系plateMserLocate->mserSearch->mserCharMatch在core_func.cpp找到位置。在函数的最后,把图片输出的判断符改为1。然后在resources/image下面依次新建tmp与plateDetect目录(跟代码中的一致),接下来再运行时在新目录里就可以看到这些调试图片。(EasyPR里还有很多其他类似的输出代码,只要按照代码的写法创建文件夹就可以看到输出结果了)。

图5 文字定位的中间结果(调试图像)
二. 更加合理准确的评价指标
原先的EasyPR的评价标准中有很多不合理的地方。例如一张图片中找到了一个疑似的区域,就认为是定位成功了。或者如果一张图片中定位到了几个车牌,就用差距率最小的那个作为定位结果。这些地方不合理的地方在于,有可能找到的疑似区域根本不是车牌区域。另外一个包含几个车牌的图片仅仅用最大的一个作为结果,明显不合理。
因此新评价指标需要考虑定位区域和车牌区域的位置差异,只有当两者接近时才能认为是定位成功。另外,一张图片如果有几个车牌,对应的就有几个定位区域,每个区域与车牌做比对,综合起来才能作为定位效果。因此需要加入一个GroundTruth,标记各个车牌的位置信息。新版本中,我们标记了251张图片,其中共250个车牌的位置信息。为了衡量定位区域与车牌区域的位置差的比例,又引入了ICDAR2003的评价协议,来最终计算出定位的recall,precise与fscore值。
车牌定位评价中做了大改动。字符识别模块则做了小改动。首先是去除了“平均字符差距”这个意义较小的指标。转而用零字符差距,一字符差距,中文字符正确替代,这三者都是比率。零字符差距(0-error)指的是识别结果与车牌没有任何差异,跟原先的评价协议中的“完全正确率”指代一样。一字符差距(1-error)指的是错别仅仅只有1个字符或以下的,包括零字符差距。注意,中文一般是两个字符。中文字符正确(Chinese-precise)指代中文字符识别正确的比率。这三个指标,都是越大越好,100%最高。
为了实际看出这些指标的效果,拿通用测试集里增加的50张复杂图片做对此测试,文字定位方法在这些数据上的表现的差异与原先的SOBEL,COLOR定位方法的区别可以看下面的结果。
SOBEL+COLOR:
总图片数:50, Plates count:52, 定位率:51.9231%
Recall:46.1696%, Precise:26.3273%, Fscore:33.533%.
0-error:12.5%, 1-error:12.5%, Chinese-precise:37.5%
CMSER:
总图片数:50, Plates count:52, 定位率:78.8462%
Recall:70.6192%, Precise:70.1825%, Fscore:70.4002%.
0-error:59.4595%, 1-error:70.2703%, Chinese-precise:70.2703%
可以看出定位率提升了接近27个百分点,定位Fscore与中文识别正确率则提升了接近1倍。
三. 非极大值抑制
新版本中另一个较大的改动就是大量的使用了非极大值抑制(Non-maximum suppression)。使用非极大值抑制有几个好处:1.当有几个定位区域重叠时,可以根据它们的置信度(也是SVM车牌判断模型得出的值)来取出其中最大概率准确的一个,移除其他几个。这样,不同定位方法,例如Sobel与Color定位的同一个区域,只有一个可以保留。因此,EasyPR新版本中,最终定位出的一个车牌区域,不再会有几个框了。2.结合滑动窗口,可以用其来准确定位文字的位置,例如在车牌定位模块中找到概率最大的文字位置,或者在文字识别模块中,更准确的找到中文文字的位置。
非极大值抑制的使用使得EasyPR的定位方法与后面的识别模块解耦了。以前,每增加定位方法,可能会对最终输出产生影响。现在,无论多少定位方法定位出的车牌都会通过非极大值抑制取出最大概率的一个,对后面的方法没有一点影响。
另外,如今setMaxPlates()这个函数可以确实的作用了。以前可以设置,但没效果。现在,设置这个值为n以后,当在一副图像中检测到大于n个车牌区域(注意,这个是经过非极大值抑制后的)时,EasyPR只会输出n个可能性最高的车牌区域。
四. 字符分割与识别部分的强化
新版本中字符分割与识别部分都添加了新算法。例如使用了spatial-ostu替代普通的ostu算法,增加了图像分割在面对光照不均匀的图像上的二值化效果。

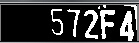

图6 车牌图像(左),普通大津阈值结果(中),空间大津阈值结果(右)
同时,识别部分针对中文增加了一种adaptive threshold方法。这种方法在二值化“川”字时有比ostu更好的效果。通过将两者一并使用,并选择其中字符识别概率最大的一个,显著提升了中文字符的识别准确率。在识别中文时,增加了一个小型的滑动窗口,以此来弥补通过省份字符直接查找中文字符时的定位不精等现象。
五. 新的特征与SVM模型,新的中文识别ANN模型
为了强化车牌判断的鲁棒性,新版本中更改了SVM模型的特征,使用LBP特征的模型在面对低对比度与光照的车牌图像中也有很好的判断效果。为了强化中文识别的准确率,现在单独为31类中文文字训练了一个ANN模型ann_chinese,使用这个模型在分类中文是的效果,相对原先的通用模型可以提升近10个百分点。
六. 其他
几天前EasyPR发布了1.5-alpha版本。今天发布的beta版本相对于alpha版本,增加了Grid Search功能, 对文字定位方法的参数又进行了部分调优,同时去除了一些中文注释以提高window下的兼容性,除此之外,在速度方面,此版本首次使用了多线程编程技术(OpenMP)来提高算法整体的效率等,使得最终的速度有了2倍左右的提升。
下面说一点新版本的不足:目前来看,文字定位方法的鲁棒性确实很高,不过遗憾的速度跟颜色定位方法相比,还是慢了接近一倍(与Sobel定位效率相当)。后面的改善中,考虑对其进行优化。另外,字符分割的效果实际上还是可以有更多的优化算法选择的,未来的版本可以考虑对其做一个较大的尝试与改进。
对EasyPR做下说明:EasyPR,一个开源的中文车牌识别系统,代码托管在github和gitosc。其次,在前面的博客文章中,包含EasyPR至今的开发文档与介绍。
版权说明:
本文中的所有文字,图片,代码的版权都是属于作者和博客园共同所有。欢迎转载,但是务必注明作者与出处。任何未经允许的剽窃以及爬虫抓取都属于侵权,作者和博客园保留所有权利。
参考文献:
1.Character-MSER : Scene Text Detection with Robust Character Candidate Extraction Method, ICDAR2015
2.Seed-growing : A robust hierarchical detection method for scene text based on convolutional neural networks, ICME2015
今天我们来介绍车牌定位中的一种新方法--文字定位方法(MSER),包括其主要设计思想与实现。接着我们会介绍一下EasyPR v1.5-beta版本中带来的几项改动。
一. 文字定位法
在EasyPR前面几个版本中,最为人所诟病的就是定位效果不佳,尤其是在面对生活场景(例如手机拍摄)时。由于EasyPR最早的数据来源于卡口,因此对卡口数据进行了优化,而并没有对生活场景中图片有较好处理的策略。后来一个版本(v1.3)增加了颜色定位方法,改善了这种现象,但是对分辨率较大的图片处理仍然不好。再加上颜色定位在面对低光照,低对比度的图像时处理效果大幅度下降,颜色本身也是一个不稳定的特征。因此EasyPR的车牌定位的整体鲁棒性仍然不足。
针对这种现象,EasyPR v1.5增加了一种新的定位方法,文字定位方法,大幅度改善了这些问题。下面几幅图可以说明文字定位法的效果。
图1 夜间的车牌图像(左) , 图2 对比度非常低的图像(右)
图3 近距离的图像(左) , 图4 高分辨率的图像(右)
图1是夜间的车牌图像,图2是对比度非常低的图像,图3是非常近距离拍摄的图像,图4则是高分辨率(3200宽)的图像。
文字定位方法是采用了低级过滤器提取文字,然后再将其组合的一种定位方法。原先是利用在场景中定位文字,在这里利用其定位车牌。与在扫描文档中的文字不同,自然场景中的文字具有低对比度,背景各异,光亮干扰较多等情况,因此需要一个极为鲁棒的方法去提取出来。目前业界用的较多的是MSER(最大稳定极值区域)方法。EasyPR使用的是MSER的一个改良方法,专门针对文字进行了优化。在文字定位出来以后,一般需要用一个分类器将其中大部分的定位错误的文字去掉,例如ANN模型。为了获得最终的车牌,这些文字需要组合起来。由于实际情况的复杂,简单的使用普通的聚类效果往往不好,因此EasyPR使用了一种鲁棒性较强的种子生长方法(seed growing)去组合。
我在这里简单介绍一下具体的实现。关于方法的细节可以看代码,有很多的注释(代码可能较长)。关于方法的思想可以看附录的两篇论文。
View Code
首先通过MSER提取区域,提取出的区域进行一个尺寸判断,滤除明显不符合车牌文字尺寸的。接下来使用一个文字分类器,将分类结果概率大于0.9的设为强种子(下图的绿色方框)。靠近的强种子进行聚合,划出一条线穿过它们的中心(图中白色的线)。一般来说,这条线就是车牌的中间轴线,斜率什么都相同。之后,就在这条线的附近寻找那些概率低于0.9的弱种子(蓝色方框)。由于车牌的特征,这些蓝色方框应该跟绿色方框距离不太远,同时尺寸也不会相差太大。蓝色方框实在绿色方框的左右查找的,有时候,几个绿色方框中间可能存在着一个方库,这可以通过每个方框之间的距离差推出来,这就是橙色的方框。全部找完以后。绿色方框加上蓝色与橙色方框的总数代表着目前在车牌区域中发现的文字数。有时这个数会低于7(中文车牌的文字数),这是因为有些区域即便通过MSER也提取不到(例如非常不稳定或光照变化大的),另外很多中文也无法通过MSER提取到(中文大多是不连通的,MSER提取的区域基本都是连通的)。所以下面需要再增加一个滑动窗口(红色方框)来寻找这些缺失的文字或者中文,如果分类器概率大于某个阈值,就可以将其加入到最终的结果中。最后,把所有文字的位置用一个方框框起来,就是车牌的区域。
想要通过中间图片进行调试程序的话,首先依次根据函数调用关系plateMserLocate->mserSearch->mserCharMatch在core_func.cpp找到位置。在函数的最后,把图片输出的判断符改为1。然后在resources/image下面依次新建tmp与plateDetect目录(跟代码中的一致),接下来再运行时在新目录里就可以看到这些调试图片。(EasyPR里还有很多其他类似的输出代码,只要按照代码的写法创建文件夹就可以看到输出结果了)。
图5 文字定位的中间结果(调试图像)
二. 更加合理准确的评价指标
原先的EasyPR的评价标准中有很多不合理的地方。例如一张图片中找到了一个疑似的区域,就认为是定位成功了。或者如果一张图片中定位到了几个车牌,就用差距率最小的那个作为定位结果。这些地方不合理的地方在于,有可能找到的疑似区域根本不是车牌区域。另外一个包含几个车牌的图片仅仅用最大的一个作为结果,明显不合理。
因此新评价指标需要考虑定位区域和车牌区域的位置差异,只有当两者接近时才能认为是定位成功。另外,一张图片如果有几个车牌,对应的就有几个定位区域,每个区域与车牌做比对,综合起来才能作为定位效果。因此需要加入一个GroundTruth,标记各个车牌的位置信息。新版本中,我们标记了251张图片,其中共250个车牌的位置信息。为了衡量定位区域与车牌区域的位置差的比例,又引入了ICDAR2003的评价协议,来最终计算出定位的recall,precise与fscore值。
车牌定位评价中做了大改动。字符识别模块则做了小改动。首先是去除了“平均字符差距”这个意义较小的指标。转而用零字符差距,一字符差距,中文字符正确替代,这三者都是比率。零字符差距(0-error)指的是识别结果与车牌没有任何差异,跟原先的评价协议中的“完全正确率”指代一样。一字符差距(1-error)指的是错别仅仅只有1个字符或以下的,包括零字符差距。注意,中文一般是两个字符。中文字符正确(Chinese-precise)指代中文字符识别正确的比率。这三个指标,都是越大越好,100%最高。
为了实际看出这些指标的效果,拿通用测试集里增加的50张复杂图片做对此测试,文字定位方法在这些数据上的表现的差异与原先的SOBEL,COLOR定位方法的区别可以看下面的结果。
SOBEL+COLOR:
总图片数:50, Plates count:52, 定位率:51.9231%
Recall:46.1696%, Precise:26.3273%, Fscore:33.533%.
0-error:12.5%, 1-error:12.5%, Chinese-precise:37.5%
CMSER:
总图片数:50, Plates count:52, 定位率:78.8462%
Recall:70.6192%, Precise:70.1825%, Fscore:70.4002%.
0-error:59.4595%, 1-error:70.2703%, Chinese-precise:70.2703%
可以看出定位率提升了接近27个百分点,定位Fscore与中文识别正确率则提升了接近1倍。
三. 非极大值抑制
新版本中另一个较大的改动就是大量的使用了非极大值抑制(Non-maximum suppression)。使用非极大值抑制有几个好处:1.当有几个定位区域重叠时,可以根据它们的置信度(也是SVM车牌判断模型得出的值)来取出其中最大概率准确的一个,移除其他几个。这样,不同定位方法,例如Sobel与Color定位的同一个区域,只有一个可以保留。因此,EasyPR新版本中,最终定位出的一个车牌区域,不再会有几个框了。2.结合滑动窗口,可以用其来准确定位文字的位置,例如在车牌定位模块中找到概率最大的文字位置,或者在文字识别模块中,更准确的找到中文文字的位置。
非极大值抑制的使用使得EasyPR的定位方法与后面的识别模块解耦了。以前,每增加定位方法,可能会对最终输出产生影响。现在,无论多少定位方法定位出的车牌都会通过非极大值抑制取出最大概率的一个,对后面的方法没有一点影响。
另外,如今setMaxPlates()这个函数可以确实的作用了。以前可以设置,但没效果。现在,设置这个值为n以后,当在一副图像中检测到大于n个车牌区域(注意,这个是经过非极大值抑制后的)时,EasyPR只会输出n个可能性最高的车牌区域。
四. 字符分割与识别部分的强化
新版本中字符分割与识别部分都添加了新算法。例如使用了spatial-ostu替代普通的ostu算法,增加了图像分割在面对光照不均匀的图像上的二值化效果。
图6 车牌图像(左),普通大津阈值结果(中),空间大津阈值结果(右)
同时,识别部分针对中文增加了一种adaptive threshold方法。这种方法在二值化“川”字时有比ostu更好的效果。通过将两者一并使用,并选择其中字符识别概率最大的一个,显著提升了中文字符的识别准确率。在识别中文时,增加了一个小型的滑动窗口,以此来弥补通过省份字符直接查找中文字符时的定位不精等现象。
五. 新的特征与SVM模型,新的中文识别ANN模型
为了强化车牌判断的鲁棒性,新版本中更改了SVM模型的特征,使用LBP特征的模型在面对低对比度与光照的车牌图像中也有很好的判断效果。为了强化中文识别的准确率,现在单独为31类中文文字训练了一个ANN模型ann_chinese,使用这个模型在分类中文是的效果,相对原先的通用模型可以提升近10个百分点。
六. 其他
几天前EasyPR发布了1.5-alpha版本。今天发布的beta版本相对于alpha版本,增加了Grid Search功能, 对文字定位方法的参数又进行了部分调优,同时去除了一些中文注释以提高window下的兼容性,除此之外,在速度方面,此版本首次使用了多线程编程技术(OpenMP)来提高算法整体的效率等,使得最终的速度有了2倍左右的提升。
下面说一点新版本的不足:目前来看,文字定位方法的鲁棒性确实很高,不过遗憾的速度跟颜色定位方法相比,还是慢了接近一倍(与Sobel定位效率相当)。后面的改善中,考虑对其进行优化。另外,字符分割的效果实际上还是可以有更多的优化算法选择的,未来的版本可以考虑对其做一个较大的尝试与改进。
对EasyPR做下说明:EasyPR,一个开源的中文车牌识别系统,代码托管在github和gitosc。其次,在前面的博客文章中,包含EasyPR至今的开发文档与介绍。
版权说明:
本文中的所有文字,图片,代码的版权都是属于作者和博客园共同所有。欢迎转载,但是务必注明作者与出处。任何未经允许的剽窃以及爬虫抓取都属于侵权,作者和博客园保留所有权利。
参考文献:
1.Character-MSER : Scene Text Detection with Robust Character Candidate Extraction Method, ICDAR2015
2.Seed-growing : A robust hierarchical detection method for scene text based on convolutional neural networks, ICME2015
- EasyPR--开发详解(8)文字定位
- EasyPR--开发详解(9)文字定位
- EasyPR--开发详解(2)车牌定位
- EasyPR--开发详解(2)车牌定位
- EasyPR--开发详解(2)车牌定位
- EasyPR--开发详解(7)颜色定位与偏斜扭转
- EasyPR--开发详解(5)颜色定位与偏斜扭转
- EasyPR--开发详解(8)字符分割
- (转载)车牌识别EasyPR--开发详解
- EasyPR--开发详解(7)字符分割
- EasyPR--开发详解(6)SVM开发详解
- EasyPR--开发详解(6)SVM开发详解
- EasyPR--开发详解(6)SVM开发详解
- 车牌识别EasyPR--开发详解
- 车牌识别EasyPR--开发详解
- 车牌识别EasyPR--开发详解
- 读EasyPR开发详解实践感想1
- EasyPR--中文开源车牌识别系统 开发详解(1)
- Java WebService_cxf (1) 入门案例
- ubuntu 12.04 系统密码破译
- JS实现JSON.stringify
- 黑客的攻击(UVA 11825)
- css样式布局的椭圆
- EasyPR--开发详解(8)文字定位
- jquery 选择器
- JSON 字符串 与 java 对象的转换
- yum -b 参数学习
- dokuwiki插件的常用配置及其他Tips
- deledate
- ZBrush骨骼雕刻的三个技巧
- 控件的抬起和按下事件
- sql函数


