QA问答系统中的深度学习技术实现
来源:互联网 发布:sql分组求和 编辑:程序博客网 时间:2024/05/20 23:06
应用场景
智能问答机器人火得不行,开始研究深度学习在NLP领域的应用已经有一段时间,最近在用深度学习模型直接进行QA系统的问答匹配。主流的还是CNN和LSTM,在网上没有找到特别合适的可用的代码,自己先写了一个CNN的(theano),效果还行,跟论文中的结论是吻合的。目前已经应用到了我们的产品上。
原理
参看《Applying Deep Learning To Answer Selection: A Study And An Open Task》,文中比较了好几种网络结构,选择了效果相对较好的其中一个来实现,网络描述如下:
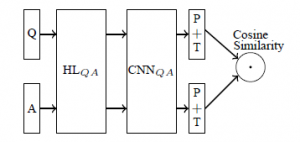
Q&A共用一个网络,网络中包括HL,CNN,P+T和Cosine_Similarity,HL是一个g(W*X+b)的非线性变换,CNN就不说了,P是max_pooling,T是激活函数Tanh,最后的Cosine_Similarity表示将Q&A输出的语义表示向量进行相似度计算。
详细描述下从输入到输出的矩阵变换过程:
- Qp:[batch_size, sequence_len],Qp是Q之前的一个表示(在上图中没有画出)。所有句子需要截断或padding到一个固定长度(因为后面的CNN一般是处理固定长度的矩阵),例如句子包含3个字ABC,我们选择固定长度sequence_len为100,则需要将这个句子padding成ABC<a><a>…<a>(100个字),其中的<a>就是添加的专门用于padding的无意义的符号。训练时都是做mini-batch的,所以这里是一个batch_size行的矩阵,每行是一个句子。
- Q:[batch_size, sequence_len, embedding_size]。句子中的每个字都需要转换成对应的字向量,字向量的维度大小是embedding_size,这样Qp就从一个2维的矩阵变成了3维的Q
- HL层输出:[batch_size, embedding_size, hl_size]。HL层:[embedding_size, hl_size],Q中的每个句子会通过和HL层的点积进行变换,相当于将每个字的字向量从embedding_size大小变换到hl_size大小。
- CNN+P+T输出:[batch_size, num_filters_total]。CNN的filter大小是[filter_size, hl_size],列大小是hl_size,这个和字向量的大小是一样的,所以对每个句子而言,每个filter出来的结果是一个列向量(而不是矩阵),列向量再取max-pooling就变成了一个数字,每个filter输出一个数字,num_filters_total个filter出来的结果当然就是[num_filters_total]大小的向量,这样就得到了一个句子的语义表示向量。T就是在输出结果上加上Tanh激活函数。
- Cosine_Similarity:[batch_size]。最后的一层并不是通常的分类或者回归的方法,而是采用了计算两个向量(Q&A)夹角的方法,下面是网络损失函数。
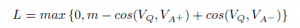 ,m是需要设定的参数margin,VQ、VA+、VA-分别是问题、正向答案、负向答案对应的语义表示向量。损失函数的意义就是:让正向答案和问题之间的向量cosine值要大于负向答案和问题的向量cosine值,大多少,就是margin这个参数来定义的。cosine值越大,两个向量越相近,所以通俗的说这个Loss就是要让正向的答案和问题愈来愈相似,让负向的答案和问题越来越不相似。
,m是需要设定的参数margin,VQ、VA+、VA-分别是问题、正向答案、负向答案对应的语义表示向量。损失函数的意义就是:让正向答案和问题之间的向量cosine值要大于负向答案和问题的向量cosine值,大多少,就是margin这个参数来定义的。cosine值越大,两个向量越相近,所以通俗的说这个Loss就是要让正向的答案和问题愈来愈相似,让负向的答案和问题越来越不相似。
实现
代码点击这里,使用的数据是一份英文的insuranceQA,下面介绍代码重点部分:
字向量。本文采用字向量的方法,没有使用词向量。使用字向量的目的主要是为了解决未登录词的问题,这样在测试的时候就很少会遇到Unknown的字向量的问题了。而且字向量的效果也不一定比词向量的效果差,还省去了分词的各种麻烦。先用word2vec生成一份字向量,相当于我们在做pre-training了(之后测试了随机初始化字向量的方法,效果差不多)
原理中的步骤2。这里没有做HL层的变换,实际测试中,增加HL层有非常非常小的提升,所以在这里就省去了改步骤。
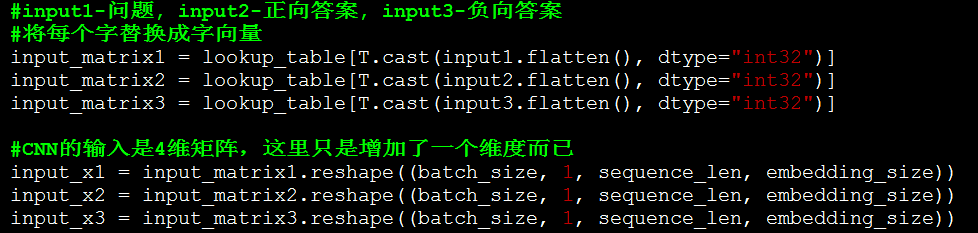
CNN可以设置多种大小的filter,最后各种filter的结果会拼接起来。

原理中的步骤4。这里执行卷积,max-pooling和Tanh激活。

生成的ouputs_1是一个python的list,使用concatenate将list的多个tensor拼接起来(list中的每个tensor表示一种大小的filter卷积的结果)
原理中的步骤5。计算问题、正向答案、负向答案的向量夹角

生成Loss损失函数和Accuracy。
核心的网络构建代码就是这些,其他的代码都是训练数据、验证数据的读入,以及theano构建训练时的一些常规代码。
如果需要增加HL层,可参照如下的代码。Whl即是HL层的网络,将input和Whl点积即可。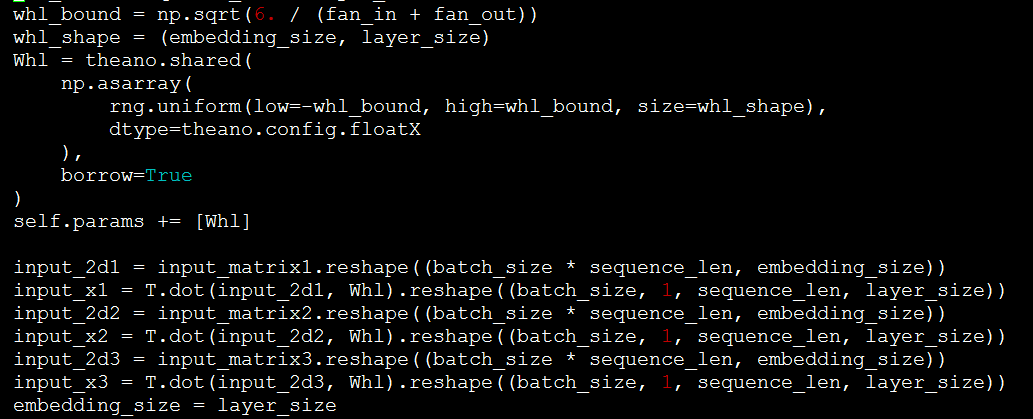
dropout的实现。

结果
使用上面的代码,Test 1的Top-1 Accuracy可以达到61%-62%,和论文中的结论基本一致了,至于论文中提到的GESD、AESD等方法没有再测试了,运行较慢,其他数据集也没有再测试了。
下面是国外友人用一个叫keras的工具(封装的theano和tensorflow)弄的类似代码,Test 1的Top-1准确率在50%左右,比他这个要高
http://benjaminbolte.com/blog/2016/keras-language-modeling.html
Test setTop-1 AccuracyMean Reciprocal RankTest 1
0.4933
0.6189
Test 2
0.4606
0.5968
Dev
0.4700
0.6088
另外,原始的insuranceQA需要进行一些处理才能在这个代码上使用,具体参看github上的说明吧。
一些技巧
- 字向量和词向量的效果相当。所以优先使用字向量,省去了分词的麻烦,还能更好的避免未登录词的问题,何乐而不为。
- 字向量不是固定的,在训练中会更新。
- Dropout的使用对最高的准确率没有很大的影响,但是使用了Dropout的结果更稳定,准确率的波动会更小,所以建议还是要使用Dropout的。不过Dropout也不易过度使用,比如Dropout的keep_prob概率如果设置到0.25,则模型收敛得更慢,训练时间长很多,效果也有可能会更差,设置会差很多。我这版代码使用的keep_prob为0.5,同时保证准确率和训练时间。另外,Dropout只应用到了max-pooling的结果上,其他地方没有再使用了,过多的使用反而不好。
- 如何生成训练集。每个训练case需要一个问题+一个正向答案+一个负向答案,很明显问题和正向答案都是有的,负向答案的生成方法就是随机采样,这样就不需要涉及任何人工标注工作了,可以很方便的应用到大数据集上。
- HL层的效果不明显,有很微量的提升。如果HL层的大小是200,字向量是100,则HL层相当于将字向量再放大一倍,这个感觉没有多少信息可利用的,还不如直接将字向量设置成200,还省去了HL这一层的变换。
- margin的值一般都设置得比较小。这里用的是0.05
- 如果将Cosine_similarity这一层换成分类或者回归,印象中效果是不如Cosine_similarity的(具体数据忘了)
- num_filters越大并不是效果越好,基本到了一定程度就很难提升了,反而会降低训练速度。
- 同时也写了tensorflow版本代码,对比theano的,效果差不多。
- Adam和SGD两种训练方法比较,Adam训练速度貌似会更快一些,效果基本也持平吧,没有太细节的对比。不过同样的网络+SGD,theano好像训练要更快一些。
- Loss和Accuracy是比较重要的监控参数。如果写一个新的网络的话,类似的指标是很有必要的,可以在每个迭代中评估网络是否正在收敛。因为调试比较麻烦,所以通过这些参数能评估你的网络写对没,参数设置是否正确。
- 网络的参数还是比较重要的,如果一些参数设置不合理,很有可能结果千差万别,记得最初用tensorflow实现的时候,应该是dropout设置得太小,导致效果很差,很久才找到原因。所以调参和微调网络还是需要一定的技巧和经验的,做这版代码的时候就经历了一段比较痛苦的调参过程,最开始还怀疑是网络设计或是代码有问题,最后总结应该就是参数没设置好。
结语
如果关注这个东西的人多的话,后面还可以有tensorflow版本的QA CNN,以及LSTM的代码奉上
Contact: jiangwen127@gmail.com weibo:码坛奥沙利文
发表在 机器学习,深度学习,自然语言处理,问答系统 |留下评论
达观数据搜索引擎的Query自动纠错技术和架构详解发表于2016年04月27号 由 recommender
1 背景
如今,搜索引擎是人们的获取信息最重要的方式之一,在搜索页面小小的输入框中,只需输入几个关键字,就能找到你感兴趣问题的相关网页。搜索巨头Google,甚至已经使Google这个创造出来的单词成为动词,有问题Google一下就可以。在国内,百度也同样成为一个动词。除了通用搜索需求外,很多垂直细分领域的搜索需求也很旺盛,比如电商网站的产品搜索,文学网站的小说搜索等。面对这些需求,达观数据(www.datagrand.com)作为国内提供中文云搜索服务的高科技公司,为合作伙伴提供高质量的搜索技术服务,并进行搜索服务的统计分析等功能。(达观数据联合创始人高翔)
搜索引擎系统最基本最核心的功能是信息检索,找到含有关键字的网页或文档,然后按照一定排序将结果给出。在此基础之上,搜索引擎能够提供更多更复杂的功能来提升用户体验。对于一个成熟的搜索引擎系统,用户看似简单的搜索过程,需要在系统中经过多个环节,多个模块协同工作,才能提供一个让人满意的搜索结果。其中拼写纠错(Error Correction,以下简称EC)是用户比较容易感知的一个功能,比如百度的纠错功能如下图所示:

图 1:百度纠错功能示例
EC其实是属于Query Rewrite(以下简称QR)模块中的一个功能,QR模块包括拼写纠错,同义改写,关联query等多个功能。QR模块对于提升用户体验有着巨大的帮助,对于搜索质量不佳的query进行改写后能返回更好的搜索结果。QR模块内容较多,以下着重介绍EC功能。
继续阅读 →
继续阅读 →
发表在 自然语言处理 |一条评论
非主流自然语言处理——遗忘算法系列(四):改进TF-IDF权重公式发表于2016年04月23号 由老憨
一、前言
前文介绍了利用词库进行分词,本文介绍词库的另一个应用:词权重计算。
二、词权重公式
1、公式的定义
定义如下公式,用以计算词的权重:

2、公式的由来
在前文中,使用如下公式作为分词的依据:

任给一个句子或文章,通过对最佳分词方案所对应的公式进行变换,可以得到:

按前面权重公式的定义,上面的公式可以理解为:一个句子出现的概率对数等于句子中各词的权重之和。
公式两边同时取负号使权重是个正值。
三、与TF-IDF的关系
词频、逆文档频率(TF-IDF)在自然语言处理中,应用十分广泛,也是提取关键词的常用方法,公式如下:

从形式上看,该公式与我们定义的权重公式很像,而且用途也近似,那么它们之间有没有关系呢?
答案是肯定的。
我们知道,IDF是按文档为单位统计的,无论文档的长短,统一都按一篇计数,感觉这个统计的粒度还是比较粗的,有没有办法将文本的长短,这个明显相关的因素也考虑进去呢,让这个公式更加精细些?
答案也是肯定的。
文章是由词铺排而成,长短不同,所包含的词的个数也就有多有少。
我们可以考虑在统计文档个数时,为每个文档引入包含多少个词这样一个权重,以区别长短不同的文档,沿着这个思路,改写一下IDF公式:

我们用所有文档中的词做成词库,那么上式中:

综合上面的推导过程,我们知道,本文所定义的词权重公式,本质上是tf-idf为长短文档引入权重的加强版,而该公式的应用也极为简单,只需要从词库中读取该词词频、词库总词频即可。
时间复杂度最快可达O(1)级,比如词库以Hash表存储。
关于TF-IDF更完整的介绍及主流用法,建议参看阮一峰老师的博文《TF-IDF与余弦相似性的应用(一):自动提取关键词》。
四、公式应用
词权重用途很广,几乎词袋类算法中,都可以考虑使用。常见的应用有:
1、关键词抽取、自动标签生成
作法都很简单,分词后排除停用词,然后按权重值排序,取排在前面的若干个词即可。
2、文本摘要
完整的文本摘要功能实现很复杂也很困难,这里所指,仅是简单应用:由前面推导过程中可知,句子的权重等于分词结果各词的权重之和,从而获得句子的权重排序。
3、相似度计算
相似度计算,我们将在下一篇文中单独介绍。
五、演示程序
在演示程序显示词库结果时,是按本文所介绍的权重公式排序的。
演示程序与词库生成的相同:
下载地址:遗忘算法(词库生成、分词、词权重)演示程序.rar
特别感谢:王斌老师指出,本文公式实质上是TF-ICF。
六、联系方式: 1、QQ:老憨 244589712
2、邮箱:gzdmcaoyc@163.com
发表在 自然语言处理 | 标签为TF-IDF,自然语言处理,遗忘算法 |留下评论
非主流自然语言处理——遗忘算法系列(三):分词发表于2016年04月23号 由老憨
一、前言
前面介绍了词库的自动生成的方法,本文介绍如何利用前文所生成的词库进行分词。
二、分词的原理
分词的原理,可以参看吴军老师《数学之美》中的相关章节,这里摘取Google黑板报版本中的部分:

从上文中,可以知道分词的任务目标:给出一个句子S,找到一种分词方案,使下面公式中的P(S)最大:

不过,联合概率求起来很困难,这种情况我们通常作马尔可夫假设,以简化问题,即:任意一个词wi的出现概率只同它前面的词 wi-1 有关。
关于这个问题,吴军老师讲的深入浅出,整段摘录如下:

另外,如果我们假设一个词与其他词都不相关,即相互独立时,此时公式最简,如下:
这个假设分词无关的公式,也是本文所介绍的分词算法所使用的。
三、算法分析
问:假设分词结果中各词相互无关是否可行?
答:可行,前提是使用遗忘算法系列(二)中所述方法生成的词库,理由如下:
分析ICTCLAS广受好评的分词系统的免费版源码,可以发现,在这套由张华平、刘群两位博士所开发分词系统的算法中假设了:分词结果中词只与其前面的一个词有关。
回忆我们词库生成的过程可以知道,如果相邻的两个词紧密相关,那么这两个词会连为一个粗粒度的词被加入词库中,如:除“清华”、“大学”会是单独的词外,“清华大学”也会是一个词,分词过程中具体选用那种,则由它们的概率来决定。
也就是说,我们在生成词库的同时,已经隐含的完成了相关性训练。
关于ICTCLAS源码分析的文章,可以参看吕震宇博文:《天书般的ICTCLAS分词系统代码》。
问:如何实现分词?
答:基于前文生成的词库,我们可以假设分词结果相互无关,分词过程就比较简单,使用下面的步骤可以O(N)级时间,单遍扫描完成分词:
逐字扫描句子,从词库中查出限定字长内,以该字结尾的所有词,分别计算其中的词与该词之前各词的概率乘积,取结果值最大的词,分别缓存下当前字所在位置的最大概率积,以及对应的分词结果。
重复上面的步骤,直到句子扫描完毕,最后一字位置所得到即为整句分词结果。
3、算法特点
3.1、无监督学习;
3.2、O(N)级时间复杂度;
3.3、词库自维护,程序可无需人工参与的情况下,自行发现并添加新词、调整词频、清理错词、移除生僻词,保持词典大小适当;
3.4、领域自适应:领域变化时,词条、词频自适应的随之调整;
3.5、支持多语种混合分词。
四、演示程序下载
演示程序与词库生成的相同:
下载地址:遗忘算法(词库生成、分词、词权重)演示程序.rar
五、联系方式:
1、QQ:老憨 244589712
2、邮箱:gzdmcaoyc@163.com
发表在 自然语言处理 | 标签为无监督分词,自然语言处理,自适应词典,跨语种,遗忘算法 |13 条评论
非主流自然语言处理——遗忘算法系列(二):大规模语料词库生成发表于2016年04月23号 由老憨
一、前言
本文介绍利用牛顿冷却模拟遗忘降噪,从大规模文本中无监督生成词库的方法。
二、词库生成
算法分析,先来考虑以下几个问题
问:目标是从文本中抽取词语,是否可以考虑使用遗忘的方法呢?
答:可以,词语具备以相对稳定周期重复再现的特征,所以可以考虑使用遗忘的方法。这意味着,我们只需要找一种适当的方法,将句子划分成若干子串,这些子串即为“候选词”。在遗忘的作用下,如果“候选词”会周期性重现,那么它就会被保留在词库中,相反如果只是偶尔或随机出现,则会逐渐被遗忘掉。
问:那用什么方法来把句子划分成子串比较合适呢?
答:考察句中任意相邻的两个字,相邻两字有两种可能:要么同属于一个共同的词,要么是两个词的边界。我们都会有这样一种感觉,属于同一个词的相邻两字的“关系”肯定比属于不同词的相邻两字的“关系”要强烈一些。
数学中并不缺少刻划“关系”的模型,这里我们选择公式简单并且参数容易统计的一种:如果两个字共现的概率大于它们随机排列在一起的概率,那么我们认为这两个字有关,反之则无关。
如果相邻两字无关,就可以将两字中间断开。逐字扫描句子,如果相邻两字满足下面的公式,则将两字断开,如此可将句子切成若干子串,从而获得“候选词”集,判断公式如下图所示:

公式中所需的参数可以通过统计获得:遍历一次语料,即可获得公式中所需的“单字的频数”、“相邻两字共现的频数”,以及“所有单字的频数总和”。
问:如何计算遗忘剩余量?
答:使用牛顿冷却公式,各参数在遗忘算法中的含义,如下图所示:
牛顿冷却公式的详情说明,可以参考阮一峰老师的博文《基于用户投票的排名算法(四):牛顿冷却定律》。

问:参数中时间是用现实时间吗,遗忘系数取多少合适呢?
答:a、关于时间:
可以使用现实时间,遗忘的发生与现实同步。
也可以考虑用处理语料中对象的数量来代替,这样仅当有数据处理时,才会发生遗忘。比如按处理的字数为计时单位,人阅读的速度约每秒5至7个字,当然每个人的阅读速度并不相同,这里的参数值要求并不需要特别严格。
b、遗忘系数可以参考艾宾浩斯曲线中的实验值,如下图(来自互联网)

我们取6天记忆剩余量约为25.4%这个值,按每秒阅读7个字,将其代入牛顿冷却公式可以求得遗忘系数:

注意艾宾浩斯曲线中的每组数值代入公式,所得的系数并不相同,会对词库的最大有效容量产生影响。
二、该算法生成词库的特点
3.1、无监督学习
3.2、O(N)级时间复杂度
3.3、训练、执行为同一过程,可无缝处理流式数据
3.4、未登录词、新词、登录词没有区别
3.5、领域自适应:领域变化时,词条、词频自适应的随之调整
3.6、算法中仅使用到频数这一语言的共性特征,无需对任何字符做特别处理,因此原理上跨语种。
三、词库成熟度
由于每个词都具备一个相对稳定的重现周期,不难证明,当训练语料达到一定规模后,在遗忘的作用下,每个词的词频在衰减和累加会达到平衡,也即衰减的速度与增加的速度基本一致。成熟的词库,词频的波动相对会比较小,利用这个特征,我们可以衡量词库的成熟程度。
四、源码(C#)、演示程序下载
使用内附语料(在“可直接运行的演示程序”下可以找到)生成词库效果如下:

下载地址:遗忘算法(词库生成、分词、词权重)演示程序.rar
五、联系方式:
1、QQ:老憨 244589712
2、邮箱:gzdmcaoyc@163.com
发表在 自然语言处理 | 标签为未登录词发现,牛顿冷却公式,自然语言处理,词库生成,遗忘算法 |4 条评论
非主流自然语言处理——遗忘算法系列(一):算法概述发表于2016年04月19号 由老憨
一、前言
这里“遗忘”不是笔误,这个系列要讲的“遗忘算法”,是以牛顿冷却公式模拟遗忘为基础、用于自然语言处理(NLP)的一类方法的统称,而不是大名鼎鼎的“遗传算法”!
在“遗忘”这条非主流自然语言处理路上,不知不觉已经摸索了三年有余,遗忘算法也算略成体系,虽然仍觉时机未到,还是决定先停一下,将脑中所积梳理成文,交由NLP的同好们点评交流。
二、遗忘算法原理
能够从未知的事物中发现关联、提炼规律才是真正智能的标志,而遗忘正是使智能生物具备这一能力的工具,也是适应变化的利器,“遗忘”这一颇具负能量特征的家伙是如何实现发现规律这么个神奇魔法的呢?
让我们从巴甫洛夫的狗说起:狗听到铃声就知道开饭了。
铃声和开饭之间并不存在必然的联系,我们知道之所以狗会将两者联系在一起,是因为巴甫洛夫有意的将两者一次次在狗那儿重复共现。所以,重复是建立关联的必要条件。
我们还可以想像,狗在进食的时候听到的声音可能还有鸟叫声、风吹树叶的沙沙声,为什么这些同样具备重复特征声音却没有和开饭建立关系呢?
细分辨我们不难想到:铃声和开饭之间不仅重复共现,而且这种重复共现还具备一个相对稳定的周期,而其他的那些声音和开饭的共现则是随机的。
那么遗忘又在其中如何起作用的呢?
1、所有事物一视同仁的按相同的规律进行遗忘;
2、偶尔或随机出现的事物因此会随时间而逐渐淡忘;
3、而具有相对稳定周期重复再现的事物,虽然也按同样的规律遗忘,但由于周期性的得到补充,从而可以动态的保留在记忆中。
在自然语言处理中,很多对象比如:词、词与词的关联、模板等,都具备按相对稳定重现的特征,因此非常适用遗忘来处理。
三、牛顿冷却公式
那么,我们用什么来模拟遗忘呢?
提到遗忘,很自然的会想到艾宾浩斯遗忘曲线,如果这条曲线有个函数形式,那么无疑是模拟遗忘的最佳建模选择。遗憾的是它只是一组离散的实验数据,但至少让我们知道,遗忘是呈指数衰减的。
另外有一个事实,有的人记性好些,有的人记性则差些,不同人之间的遗忘曲线是不同的,但这并不会从本质上影响不同人对事物的认知,也就是说,如果存在一个遗忘函数,它首先是指数形式的,其次在实用过程中,该函数的系数并不那么重要。
这提醒我们,可以尝试用一些指数形式的函数来代替遗忘曲线,然后用实践去检验,如果能满足工程实用就很好,这样的函数公式并不难找,比如:退火算法、半衰期公式等。
有次在阮一峰老师的博客上看关于帖子热度排行的算法时,其中一种方法使用的是牛顿冷却定律,遗忘与冷却有着相似的过程、简洁优美的函数形式、而且参数只与时间相关,这些都让我本能想到,它就是我想要的“遗忘公式”。
在实践检验中,牛顿冷却公式,确实有效好用,当然,不排除有其他更佳公式。
四、已经实现的功能
如果把自然语言处理比作从矿砂中淘金子,那么业界主流算法的方向是从矿砂中将金砂挑出来,而遗忘算法的方向则是将砂石筛出去,虽然殊途但同归,所处理的任务也都是主流中所常见。
本系列文章将逐一讲解遗忘算法如何以O(N)级算法性能实现:
1、大规模语料词库生成
1.1、跨语种,算法语种无关,比如:中日韩、少数民族等语种均可支持
1.2、未登录词发现(只要符合按相对稳定周期性重现的词汇都会被收录)
1.3、领域自适应,切换不同领域的训练文本时,词条、词频自行调整
1.4、词典成熟度:可以知道当前语料训练出的词典的成熟程度
1.1、跨语种,算法语种无关,比如:中日韩、少数民族等语种均可支持
1.2、未登录词发现(只要符合按相对稳定周期性重现的词汇都会被收录)
1.3、领域自适应,切换不同领域的训练文本时,词条、词频自行调整
1.4、词典成熟度:可以知道当前语料训练出的词典的成熟程度
2、分词(基于上述词库技术)
2.1、成长性分词:用的越多,切的越准
2.2、词典自维护:切词的同时动态维护词库的词条、词频、登录新词
2.2、领域自适应、跨语种(继承自词库特性)
2.1、成长性分词:用的越多,切的越准
2.2、词典自维护:切词的同时动态维护词库的词条、词频、登录新词
2.2、领域自适应、跨语种(继承自词库特性)
3、词权值计算
3.1、关键词提取、自动标签
3.2、文章摘要
3.3、长、短文本相似度计算
3.4、主题词集
3.1、关键词提取、自动标签
3.2、文章摘要
3.3、长、短文本相似度计算
3.4、主题词集
五、联系方式:
1、QQ:老憨 244589712
2、邮箱:gzdmcaoyc@163.com
发表在 自然语言处理 | 标签为牛顿冷却公式,自然语言处理,遗忘算法 |留下评论
达观数据对于大规模消息数据处理的系统架构发表于2015年12月2号 由recommender
达观数据是为企业提供大数据处理、个性化推荐系统服务的知名公司,在应对海量数据处理时,积累了大量实战经验。其中达观数据在面对大量的数据交互和消息处理时,使用了称为DPIO的设计思路进行快速、稳定、可靠的消息数据传递机制,本文分享了达观数据在应对大规模消息数据处理时所开发的通讯中间件DPIO的设计思路和处理经验(达观数据架构师 桂洪冠)
一、数据通讯进程模型
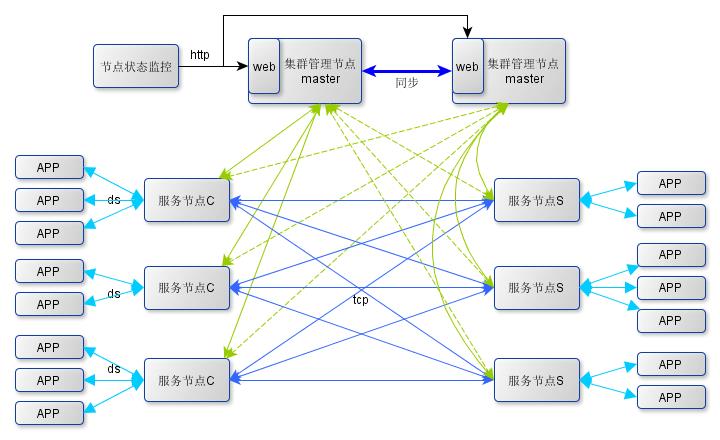 在设计达观数据的消息数据处理机制时,首先充分借鉴了ZeroMQ和ProxyIO的设计思想。ZeroMQ提供了一种底层的网络通讯框架,提供了基本的RoundRobin负载均衡算法,性能优越,而ProxyIO是雅虎的网络通讯中间件,承载了雅虎内部大量计算节点间的实时消息处理。但是ZeroMQ没有实现基于节点健康状态的最快响应算法,并且ZeroMQ和ProxyIO对节点的状态管理,连接管理,负载均衡调度等也需要各应用自己来实现。
在设计达观数据的消息数据处理机制时,首先充分借鉴了ZeroMQ和ProxyIO的设计思想。ZeroMQ提供了一种底层的网络通讯框架,提供了基本的RoundRobin负载均衡算法,性能优越,而ProxyIO是雅虎的网络通讯中间件,承载了雅虎内部大量计算节点间的实时消息处理。但是ZeroMQ没有实现基于节点健康状态的最快响应算法,并且ZeroMQ和ProxyIO对节点的状态管理,连接管理,负载均衡调度等也需要各应用自己来实现。达观科技在借鉴两种设计思路的基础上,从进程模型、服务架构、线程模型、通讯协议、负载均衡、雪崩处理、连接管理、消息流程、状态监控等各方面进行了开拓,开发了DPIO(达观ProxyIO的简写,下文统称DPIO),确保系统高性能处理相关数据。
在DPIO的整个通讯框架体系中,采用集中管理、统一监控策略管理节点提供服务,节点间直接进行交互,并不依赖统一的管理节点(桂洪冠)。几种节点间通过http或者tcp协议进行消息传递、配置更新、状态跟踪等通讯行为。集群将不同应用的服务抽象成组的概念,相同应用的服务启动时加入的相同的组。每个通讯组有两种端点client和server。应用启动时通过配置决定自己是client端点还是server端点,在一个组内,每个应用只能有一个身份;不同组没要求。
- 监控节点,顾名思义即提供系统监控服务的,用来给系统管理员查看集群中节点的服务状态及负载情况,系统对监控节点并无实时性及稳定性要求,在本模型中是单点系统。
- 在上图的架构中把管理节点设计成双master结构,参考zookeeper集群管理思路,多个master通过一定算法分别服务于集群中一部分节点,相对于另外的服务节点则为备份管理节点,他们通过内部通讯同步数据,每个管理节点都有一个web服务为监控节点提供服务节点的状态数据。
- 服务节点即是下文要谈的代理服务,根据服务对象不同分为应用端代理和服务端代理。集群中的服务节点根据提供服务的不同分为多个组,每个代理启动都需要注册到相应的组中,然后提供服务。
二、DPIO消息传递逻辑架构
DPIO服务节点内/间的通讯及消息传递模型见下图:
- clientHost和serverHost间使用socketapi进行tcp通讯,相同主机内部的多个进程间使用共享内存传递消息内容,client和clientproxy、server和serverproxy之间通过domain socket进行事件通知;在socket连接的一方收到对端的事件通知后,从共享内存中获取消息内容。
- clientproxy/serverproxy启动时绑定到host的一个端口响应应用api的连接,在连接到来时将该api对应的共享内存初始化,将偏移地址告诉给应用。clientproxy和serverproxy中分别维护了一个到应用api的连接句柄队列,并通过io复用技术监听这些连接上的读写事件。
- serverproxy在启动时通过socket绑定到服务器的一个端口,并以server身份注册到一个group监听该端口的连接事件,当事件到达时回调注册的事件处理函数响应事件。
- 在serverproxy内部通过不同的thread分别管理从本地应用建立的连接和从clientproxy建立的连接。thread的个数在启动proxy时由用户指定,默认是分别1个。每个clientproxy启动时会以client身份注册到一个group,并建立到同组的所有serverproxy的连接,clientproxy内部包含了连接的自管理能力及failover的处理(将在下面连接管理部分描述)。 DPIO实现了负载均衡,路由选择和透明代理的功能。
三、线程模型
DPIO的线程模型:

App epoll thread检测从api来的请求信息,并将请求信息转发到待处理队列中。从已处理队列中获取应答包,并将处理结果转发给api
Io epoll thread检测从远端的proxy来的可写事件,并将请求包转发到远端的proxy。检测从远端的proxy的可读事件,并将应答包放在已处理队列中
Monitor thread检测DPIO的工作状态请求,将DPIO的工作状态返回。并将决定Io epoll thread和app epoll thread的负载均衡(桂洪冠)。
四、通信协议

- Api与DPIO通信协议
- 共享内存存储消息格式
字段
含义
长度
protocol len
协议包的总长度
4bytes
protocol head len
协议头的长度
1byte
Version_protocol_id
协议的版本号和协议号
1byte
Flag
消息标志,标志路由模式,是否记录来源地址,有二级路由,所以这个字段一定要Eg,末位表示要记录src,倒数第二位表示按roundrobin路由,倒数第3位表示按消息头路由,xxx
1byte
Proxy
来源/目的 proxy
2bytes
Api
来源/目的 api
2bytes
ApiTtl
协议包的发送时间
2Bytes
ClientTtl
消息存活的时间,后面添加,增加路由策略,选择app_server
2Bytes
ClientProcessTime
客户端处理所用时间
2Bytes
ServerTtl
消息存活的时间,后面添加,增加路由策略,选择app_client
2Bytes
timeout
协议包的超时时间
2 byte
Sid
消息序列号
4bytes
protocol body len
Body长度
4bytes
protocol body
消息体
Size
- 请求协议包
字段
含义
长度
protocol head len
协议头的长度
1byte
Version_protocol_id
协议的版本号和协议号
1byte
Flag
消息标志,标志路由模式,是否记录来源地址,有二级路由,所以这个字段一定要Eg,末位表示要记录src,倒数第二位表示按roundrobin路由,倒数第3位表示按消息头路由,xxx
1byte
ApiTtl
协议包的发送时间
2bytes
Timeout
协议包的超时时间
2bytes
Api
来源/目的 api
2bytes
Sid
消息序列号
4byte
Begin_offset
协议包的起始偏移
4bytes
len
协议包长度
4bytes
- 响应协议包
字段
含义
长度
protocol head len
协议头的长度
1byte
Version_protocol_id
协议的版本号和协议号
1byte
Flag
消息标志,标志路由模式,是否记录来源地址,有二级路由,所以这个字段一定要Eg,末位表示要记录src,倒数第二位表示按roundrobin路由,倒数第3位表示按消息头路由,xxx
1byte
Result
处理结果
1byte
sid
消息序列号
4bytes
begin_offset
协议包的起始偏移
4bytes
len
协议包长度
4bytes
- Proxy与监控中心的监控信息
- 请求协议包
字段
含义
长度
protocol len
协议包的总长度
4bytes
protocol head len
协议头的长度
4bytes
Version
协议的版本号
4bytes
protocol id
协议的协议号
4bytess
status_version
当前状态版本
4bytes
Proxy_identify_len
该proxy标识长度
4bytess
Proxy_identify
该proxy 标识
4bytes
protocol body
消息体
Size
- 应答包
字段
含义
长度
protocol len
协议包的总长度
4bytes
protocol head len
协议头的长度
4bytes
Version
协议的版本号
4bytes
protocol id
协议的协议号
4bytess
protocol body len
Body长度
4bytes
protocol body
消息体
Size
五、负载均衡

DPIO的负载均衡基于最快响应法
DPIO将所有的统计信息更新到监控中心,监控中心通过处理所有的节点的状态信息,统一负责负载均衡。
DPIO从监控中心获取所有连接的负载均衡策略。每个连接知道只需知道自己的处理能力。
以上图为例,有三个proxy server处理程序。处理能力分别为50、30、20,一次epoll过程能够同时探测多个连接的可写事件。
假设:三个proxy server的属于同一epoll thread,且三个proxy server假设都处理能力无限大。
限制:如果刚开始时待处理队列的数据包个数为100个,多次发送轮回后proxy server A≥proxy server B≥proxy server C, 每个发送的最多发送协议包数为待处理队列协议包个数 * 该连接所占权重
六、雪崩处理
大型在线服务,特别是对于时延敏感的服务,当系统外部请求超过系统服务能力,而没有适当的过载保护措施时,当系统累计的超时请求达到一定规模,将可能导致系统缓冲区队列溢出,后端服务资源耗尽,最终像雪崩一样形成恶性循环。这时系统处理的每个请求都因为超时而无效,系统对外呈现的服务能力为0,且这种情况下不能自动恢复。
我们的解决策略是对协议包进行生命周期管理,现在协议包进出待处理队列和已处理队列时进行超时检测和超时处理(超时则丢弃)。
proxy client:
当app epoll thread将协议包放入待处理队列时,会将该协议包的发送时间、该协议包的超时时间,当前时间戳来判断该协议包是否已经超时。
当app epoll thread将协议包从已处理队列中移除时,会将该协议包的发送时间、该协议包的超时时间,已经当前时间戳来判断该协议包是否已经超时。
当Io epoll thread将协议包从待处理队列中移除时,会将该协议包的发送时间、该协议包的超时时间,当前时间戳,该连接的协议包的平均处理时间移除。
当io epoll thread将协议包放入已处理队列时,会将将该协议包的发送时间、该协议包的超时时间,已经当前时间戳来判断该协议包是否已经超时。
proxy server:
当App epoll thread将协议包从待处理队列中移除时,会将该协议包在客户端的处理时间、该协议包的超时时间、该协议包的proxy server接收时间戳、当前时间戳来判断该协议包是否已超时。
当app epoll thread将协议包放入已处理队列时,会将该协议包的发送时间、该协议包的超时时间,已经当前时间戳来判断该协议包是否已经超时。
当io epoll thread将协议包从已处理队列中移除时,会将该协议包的发送时间、该协议包的超时时间,已经当前时间戳来判断该协议包是否已经超时。
当io epoll thread将协议包放入待处理队列时,会将该协议包的发送时间、该协议包的超时时间来判断该协议包是否已超时。
七、连接管理
红黑树:

红黑树:保存所有连接的最近的读/写时间戳。
当epoll_wait时,首先从红黑树中获取oldest的时间戳,并将当前时间戳与oldest时间戳的时间差作为epoll_wait的超时时间,当连接中有可读/写事件发送时,首先从红黑树中删除该节点,当可读/写事件处理完毕后,再将节点插入到红黑树中,当处理完所有连接的可读/写事件时,再从红黑树中依次从移除时间戳小于当前时间戳的连接,并触发该连接的timeout事件。
八、消息处理流程

- apiclient通过调用api的接口,将消息传给
- api接受消息体,从共享内存中申请内存,填写消息头size(协议总长度)、Offset (协议版本号和协议号)、Headsize (协议头的总长度)、flag(路由策略),ApiTtl (协议包的发送时间)、timeout (协议包的超时时间)、sid(序列号),size(消息体长度)字段,封装成协议包,将协议包写入共享内存。
- api通过socket发送请求给proxy。
- app epoll thread通过检测api的可读事件,接受请求。通过解析请求内容,获取请求协议包所在的共享内存的偏移、请求协议包的长度和api连接index加入到处理队列。
- proxy client的io epoll thread通过检测对端DPIO连接的可写事件,从发送队列中获取请求包,将api的index加入到协议包的api index字段。
- proxy client的io epoll thread从共享内存中读取协议包,释放由请求包中所标识的内存空间。
- proxy server的io epoll thread通过检测对端DPIO的可读事件,接受请求。
- proxy server的io epoll thread从共享内存中申请空间,将proxy的index加入到协议包的proxy index字段。将请求内存写入到申请的空间中。
- proxy server的io epoll thread 将协议包在共享内存的偏移和协议包的长度加入的待处理队列中。
- app epoll thread从待处理队列中获取请求包,将协议包转发给相应的api进行处理。
- api通过检测DPIO的可读事件,解析请求内容。
- api通过解析请求内容,获取请求协议包在共享内存中的偏移和请求协议包的长度。从共享内存中读取请求内容,并释放相应空间。
- api将请求协议包返回给应用层进行处理。
- 应用层将应答包传给api。
- Api从共享内存中申请空间,将应答包写入到共享内存中。
- Api将应答包在共享内存中的偏移和应答包的大小写入到共享内存中。
- App epoll thread通过检测可读事件,将应答包写入到已处理队列中。
- proxy server的Io epoll thread通过检测对端的DPIO的可写事件,将已处理队列中获取应答包。
- proxy server的Io epoll thread从共享内存中读取应答包。
- Proxy client的Io epoll thread检测可读事件,读取应答包。
- Proxy client的Io epoll thread通过解析应答包,从共享内存中申请空间,将应答包写入到申请的内存中。
- Proxy client的Io epoll thread将应答包移入到已处理队列。
- App epoll thread通过检测api的可写事件,将已处理队列中获取应答包。
- App epoll thread发送应答包。
- Api通过检测可读事件,获取应答包,通过解析应到包,获取应答包在共享内存中的偏移和应到的大小,从共享内存中读取应到包。
- Api将应答包返回给应用端。(桂洪冠 陈运文)。
九、状态监控

连接池中存在:当前可用连接个数
连接池中再分别获取每个连接的状态
每个可用连接分别维护以下信息:
连接处理的数据包个数、连接send失败次数、连接协议包的平均处理时间。
连接的连接状态(当重连失败达到一定次数时,定义为连接失败)。
连接的重连次数、连接的超时次数。
当监控线程accept到client的连接时,解析请求内容,然后调用连接池对象的statistics方法,连接池对象首先写入自己的统计信息,然后分别调用每个连接的statistics方法,每个连接分别填写自己的统计信息
本文小结
大规模消息传递会遇到很多可靠性、稳定性的问题,DPIO是达观在处理大数据通讯时的一些经验,和感兴趣的朋友们分享,期待与大家不断交流与合作
发表在 数据挖掘 | 标签为数据处理,数据通讯 |留下评论
在微信公众号里使用LaTeX数学公式发表于2015年11月17号 由52nlp
因为有同学在微信后台咨询这个问题,所以这里简单记录一下,其实自己之前也摸索了一些方法,不是太完美,目前所使用的这个方法算是折中后比较好的。
这段时间在鼓捣“NLPJob”这个公众号,特别是微信公众号支持“原创声明”后,就很乐意将52nlp上积攒的一些文章搬上去,但是逐渐会遇到一些数学公式的问题。目前在52nlp上用的是mathjax完美支持LaTeX数学公式展现,但是微信公众号的编辑器没有这个支持,另外mathjax支持的公式形式不是图片形式,所以不能直接将文章拷贝上去,但是如果是数学公式图片,微信编辑器可以直接拷贝,所以最直接的想法就是将mathjax支持的LaTeX公式转换为公式图片保存在文章中,然后再全文拷贝到微信公众号编辑器中。
其实在mathjax之前,网页上的很多数学公式都是用这种折中的方式,包括很多wordpress数学公式插件,当年我也因为52nlp上的公式问题还自己动手写了一个小的wordpress插件,但是当mathjax出现之后,之前的方案就显得很一般了。所以就开始尝试找一下支持img缓存的LaTeX公式插件,不过多数都不满意或者有瑕疵,甚至自己又开始动手修改代码,然后blablabla….,最终发现quicklatex这个神器和它的wordpress插件QuickLaTeX,几乎完美支持和兼容Mathjax所支持的LaTeX数学公式。方法很简单,只要在wordpress中安装quicklatex,然后在文章的开头添加一个:[latexpage] ,然后文章中所有的latext公式都会转换为图片形式,类似昨天发出的rickjin的这篇文章:LDA数学八卦:神奇的Gamma函数(1)。当然需要先在wordpress中完成编辑转换,再全文拷贝到微信公众号中,微信会自动的将这些图片上传到它自己的图片服务器上。不过依然希望微信公众号编辑器能早日支持LaTeX公式编辑甚至Mathjax。
发表在 随笔 | 标签为latex公式,latex数学公式,MathJax,微信,微信latex,微信公众号,微信公众号数学公式编辑器,微信公式编辑器,微信数学公式 |2 条评论
斯坦福大学深度学习与自然语言处理第四讲:词窗口分类和神经网络发表于2015年09月14号 由 52nlp
斯坦福大学在三月份开设了一门“深度学习与自然语言处理”的课程:CS224d: Deep Learning for Natural Language Processing,授课老师是青年才俊 Richard Socher,以下为相关的课程笔记。
第四讲:词窗口分类和神经网络(Word Window Classification and Neural Networks)
推荐阅读材料:
- [UFLDL tutorial]
- [Learning Representations by Backpropogating Errors]
- 第四讲Slides [slides]
- 第四讲视频 [video]
以下是第四讲的相关笔记,主要参考自课程的slides,视频和其他相关资料。
继续阅读 →
继续阅读 →
发表在 机器学习,深度学习,自然语言处理 | 标签为Deep Learning,Deep Learning公开课,Deep NLP,DL,NER,Richard Socher,softmax,word vectors,word2vec,wordnet,二元逻辑回归,人名识别,公开课,分类,分类器,前馈网络记录,反向传播算法,命名实体识别,回归,地名识别,斯坦福大学,机器学习,梯度下降,深度学习,深度学习与自然语言处理,深度学习技术,深度学习模型,神经元,神经网络,窗口向量,窗口向量分类,自然语义处理,自然语言处理,词向量,词嵌入,语义词典,逻辑回归,随机梯度下降 |3 条评论
出门问问宣布完成由Google投资的C轮融资,累计融资7500万美金发表于2015年09月2号 由 52nlp
注:出门问问是我们的老朋友,创始人李志飞也是NLP和机器翻译领域的大牛,今天出门问问拿到了Google的C轮融资,志飞兄第一时间和我分享了这条新闻,太牛了。
人工智能创业公司出门问问(Mobvoi),于近日完成了由Google投资的C轮融资,累计融资7500万美金。现有投资方包括红杉资本、真格基金,SIG海纳亚洲、圆美光电、及歌尔声学。此轮投资Google并不控股,出门问问团队依旧有绝对控制权。
此次由Google投资的C轮融资,能够保证出门问问在人工智能领域长期持续深耕,专注核心技术上的进一步研发,在可穿戴、车载以及机器人领域拓展新的人机交互产品形态,更深入地完善用户体验,在吸引全球顶尖技术与商务人才上更具优势。对于海外市场的扩展,此次融资也将发挥非常重要的作用。
Google 企业发展部副总裁Don Harrison 说到选择投资出门问问的原因:“出门问问研发了非常独特自成体系的语音识别与自然语言处理技术。我们被他们的创新科技与发展潜力打动,所以我们很迅速地决定用投资的方式帮助他们在未来快速成长。”
红杉资本全球执行合伙人沈南鹏评价:“出门问问一直处于高速的不断创新过程中,从移动app到硬件产品到语音搜索平台,不同形式的产品背后是团队长期以来形成的强大技术核心,获得Google的投资是对这种中国原创能力的最好肯定。我很高兴Google这样的巨头看好出门问问,并和我们一起投入到这支高速创新的团队中。”
真格基金创始人徐小平说:“我第一次遇见谷歌科学家李志飞博士,是三年前。那时候,他的语音搜索创业计划,真是一个“异想天开”的梦。志飞相信自己的梦,相信自己的技术,相信市场对这个技术产品的需求,历经万难,终于“搜索”到了属于他自己的那片天空。志飞的创业历程,是又一个中国好故事,会激励更多人追求并实现自己的好梦。”
志同道合是此次融资达成的最重要的原因。扎实做技术和产品,运用科技的力量改变人们的日常生活,是出门问问一直笃信的价值观。
出门问问CEO 李志飞表示:“引入Google的投资,不仅意味Google对于我们技术的认可,更是源于双方持有共同的价值观,通过对人工智能技术的极致追求,打造毫不妥协的用户体验。”
与Google相似,出门问问也是信仰“工程师文化”的团队,强大的研发团队由Google前科学家、人工智能专家领衔,团队成员来自哈佛、MIT、斯坦福、剑桥、清华等名校名企。
此次融资是中国人工智能创业公司首次获得像Google这样的国际技术巨头的投资与认可。这在某种程度上说明,在人工智能领域,中国的创业公司不容小觑。
继续阅读 →
继续阅读 →
应用场景
智能问答机器人火得不行,开始研究深度学习在NLP领域的应用已经有一段时间,最近在用深度学习模型直接进行QA系统的问答匹配。主流的还是CNN和LSTM,在网上没有找到特别合适的可用的代码,自己先写了一个CNN的(theano),效果还行,跟论文中的结论是吻合的。目前已经应用到了我们的产品上。
原理
参看《Applying Deep Learning To Answer Selection: A Study And An Open Task》,文中比较了好几种网络结构,选择了效果相对较好的其中一个来实现,网络描述如下:
Q&A共用一个网络,网络中包括HL,CNN,P+T和Cosine_Similarity,HL是一个g(W*X+b)的非线性变换,CNN就不说了,P是max_pooling,T是激活函数Tanh,最后的Cosine_Similarity表示将Q&A输出的语义表示向量进行相似度计算。
详细描述下从输入到输出的矩阵变换过程:
- Qp:[batch_size, sequence_len],Qp是Q之前的一个表示(在上图中没有画出)。所有句子需要截断或padding到一个固定长度(因为后面的CNN一般是处理固定长度的矩阵),例如句子包含3个字ABC,我们选择固定长度sequence_len为100,则需要将这个句子padding成ABC<a><a>…<a>(100个字),其中的<a>就是添加的专门用于padding的无意义的符号。训练时都是做mini-batch的,所以这里是一个batch_size行的矩阵,每行是一个句子。
- Q:[batch_size, sequence_len, embedding_size]。句子中的每个字都需要转换成对应的字向量,字向量的维度大小是embedding_size,这样Qp就从一个2维的矩阵变成了3维的Q
- HL层输出:[batch_size, embedding_size, hl_size]。HL层:[embedding_size, hl_size],Q中的每个句子会通过和HL层的点积进行变换,相当于将每个字的字向量从embedding_size大小变换到hl_size大小。
- CNN+P+T输出:[batch_size, num_filters_total]。CNN的filter大小是[filter_size, hl_size],列大小是hl_size,这个和字向量的大小是一样的,所以对每个句子而言,每个filter出来的结果是一个列向量(而不是矩阵),列向量再取max-pooling就变成了一个数字,每个filter输出一个数字,num_filters_total个filter出来的结果当然就是[num_filters_total]大小的向量,这样就得到了一个句子的语义表示向量。T就是在输出结果上加上Tanh激活函数。
- Cosine_Similarity:[batch_size]。最后的一层并不是通常的分类或者回归的方法,而是采用了计算两个向量(Q&A)夹角的方法,下面是网络损失函数。,m是需要设定的参数margin,VQ、VA+、VA-分别是问题、正向答案、负向答案对应的语义表示向量。损失函数的意义就是:让正向答案和问题之间的向量cosine值要大于负向答案和问题的向量cosine值,大多少,就是margin这个参数来定义的。cosine值越大,两个向量越相近,所以通俗的说这个Loss就是要让正向的答案和问题愈来愈相似,让负向的答案和问题越来越不相似。
实现
代码点击这里,使用的数据是一份英文的insuranceQA,下面介绍代码重点部分:
字向量。本文采用字向量的方法,没有使用词向量。使用字向量的目的主要是为了解决未登录词的问题,这样在测试的时候就很少会遇到Unknown的字向量的问题了。而且字向量的效果也不一定比词向量的效果差,还省去了分词的各种麻烦。先用word2vec生成一份字向量,相当于我们在做pre-training了(之后测试了随机初始化字向量的方法,效果差不多)
原理中的步骤2。这里没有做HL层的变换,实际测试中,增加HL层有非常非常小的提升,所以在这里就省去了改步骤。
CNN可以设置多种大小的filter,最后各种filter的结果会拼接起来。
原理中的步骤4。这里执行卷积,max-pooling和Tanh激活。
生成的ouputs_1是一个python的list,使用concatenate将list的多个tensor拼接起来(list中的每个tensor表示一种大小的filter卷积的结果)
原理中的步骤5。计算问题、正向答案、负向答案的向量夹角
生成Loss损失函数和Accuracy。
核心的网络构建代码就是这些,其他的代码都是训练数据、验证数据的读入,以及theano构建训练时的一些常规代码。
如果需要增加HL层,可参照如下的代码。Whl即是HL层的网络,将input和Whl点积即可。
dropout的实现。
结果
使用上面的代码,Test 1的Top-1 Accuracy可以达到61%-62%,和论文中的结论基本一致了,至于论文中提到的GESD、AESD等方法没有再测试了,运行较慢,其他数据集也没有再测试了。
下面是国外友人用一个叫keras的工具(封装的theano和tensorflow)弄的类似代码,Test 1的Top-1准确率在50%左右,比他这个要高
http://benjaminbolte.com/blog/2016/keras-language-modeling.html
Test setTop-1 AccuracyMean Reciprocal RankTest 1
0.4933
0.6189
Test 2
0.4606
0.5968
Dev
0.4700
0.6088
另外,原始的insuranceQA需要进行一些处理才能在这个代码上使用,具体参看github上的说明吧。
一些技巧
- 字向量和词向量的效果相当。所以优先使用字向量,省去了分词的麻烦,还能更好的避免未登录词的问题,何乐而不为。
- 字向量不是固定的,在训练中会更新。
- Dropout的使用对最高的准确率没有很大的影响,但是使用了Dropout的结果更稳定,准确率的波动会更小,所以建议还是要使用Dropout的。不过Dropout也不易过度使用,比如Dropout的keep_prob概率如果设置到0.25,则模型收敛得更慢,训练时间长很多,效果也有可能会更差,设置会差很多。我这版代码使用的keep_prob为0.5,同时保证准确率和训练时间。另外,Dropout只应用到了max-pooling的结果上,其他地方没有再使用了,过多的使用反而不好。
- 如何生成训练集。每个训练case需要一个问题+一个正向答案+一个负向答案,很明显问题和正向答案都是有的,负向答案的生成方法就是随机采样,这样就不需要涉及任何人工标注工作了,可以很方便的应用到大数据集上。
- HL层的效果不明显,有很微量的提升。如果HL层的大小是200,字向量是100,则HL层相当于将字向量再放大一倍,这个感觉没有多少信息可利用的,还不如直接将字向量设置成200,还省去了HL这一层的变换。
- margin的值一般都设置得比较小。这里用的是0.05
- 如果将Cosine_similarity这一层换成分类或者回归,印象中效果是不如Cosine_similarity的(具体数据忘了)
- num_filters越大并不是效果越好,基本到了一定程度就很难提升了,反而会降低训练速度。
- 同时也写了tensorflow版本代码,对比theano的,效果差不多。
- Adam和SGD两种训练方法比较,Adam训练速度貌似会更快一些,效果基本也持平吧,没有太细节的对比。不过同样的网络+SGD,theano好像训练要更快一些。
- Loss和Accuracy是比较重要的监控参数。如果写一个新的网络的话,类似的指标是很有必要的,可以在每个迭代中评估网络是否正在收敛。因为调试比较麻烦,所以通过这些参数能评估你的网络写对没,参数设置是否正确。
- 网络的参数还是比较重要的,如果一些参数设置不合理,很有可能结果千差万别,记得最初用tensorflow实现的时候,应该是dropout设置得太小,导致效果很差,很久才找到原因。所以调参和微调网络还是需要一定的技巧和经验的,做这版代码的时候就经历了一段比较痛苦的调参过程,最开始还怀疑是网络设计或是代码有问题,最后总结应该就是参数没设置好。
结语
如果关注这个东西的人多的话,后面还可以有tensorflow版本的QA CNN,以及LSTM的代码奉上
Contact: jiangwen127@gmail.com weibo:码坛奥沙利文
发表在 机器学习,深度学习,自然语言处理,问答系统 |留下评论
达观数据搜索引擎的Query自动纠错技术和架构详解发表于2016年04月27号 由 recommender
1 背景
如今,搜索引擎是人们的获取信息最重要的方式之一,在搜索页面小小的输入框中,只需输入几个关键字,就能找到你感兴趣问题的相关网页。搜索巨头Google,甚至已经使Google这个创造出来的单词成为动词,有问题Google一下就可以。在国内,百度也同样成为一个动词。除了通用搜索需求外,很多垂直细分领域的搜索需求也很旺盛,比如电商网站的产品搜索,文学网站的小说搜索等。面对这些需求,达观数据(www.datagrand.com)作为国内提供中文云搜索服务的高科技公司,为合作伙伴提供高质量的搜索技术服务,并进行搜索服务的统计分析等功能。(达观数据联合创始人高翔)
搜索引擎系统最基本最核心的功能是信息检索,找到含有关键字的网页或文档,然后按照一定排序将结果给出。在此基础之上,搜索引擎能够提供更多更复杂的功能来提升用户体验。对于一个成熟的搜索引擎系统,用户看似简单的搜索过程,需要在系统中经过多个环节,多个模块协同工作,才能提供一个让人满意的搜索结果。其中拼写纠错(Error Correction,以下简称EC)是用户比较容易感知的一个功能,比如百度的纠错功能如下图所示:
图 1:百度纠错功能示例
EC其实是属于Query Rewrite(以下简称QR)模块中的一个功能,QR模块包括拼写纠错,同义改写,关联query等多个功能。QR模块对于提升用户体验有着巨大的帮助,对于搜索质量不佳的query进行改写后能返回更好的搜索结果。QR模块内容较多,以下着重介绍EC功能。
继续阅读 →
继续阅读 →
发表在 自然语言处理 |一条评论
非主流自然语言处理——遗忘算法系列(四):改进TF-IDF权重公式发表于2016年04月23号 由老憨
一、前言
前文介绍了利用词库进行分词,本文介绍词库的另一个应用:词权重计算。
二、词权重公式
1、公式的定义
定义如下公式,用以计算词的权重:
2、公式的由来
在前文中,使用如下公式作为分词的依据:
任给一个句子或文章,通过对最佳分词方案所对应的公式进行变换,可以得到:
按前面权重公式的定义,上面的公式可以理解为:一个句子出现的概率对数等于句子中各词的权重之和。
公式两边同时取负号使权重是个正值。
三、与TF-IDF的关系
词频、逆文档频率(TF-IDF)在自然语言处理中,应用十分广泛,也是提取关键词的常用方法,公式如下:
从形式上看,该公式与我们定义的权重公式很像,而且用途也近似,那么它们之间有没有关系呢?
答案是肯定的。
我们知道,IDF是按文档为单位统计的,无论文档的长短,统一都按一篇计数,感觉这个统计的粒度还是比较粗的,有没有办法将文本的长短,这个明显相关的因素也考虑进去呢,让这个公式更加精细些?
答案也是肯定的。
文章是由词铺排而成,长短不同,所包含的词的个数也就有多有少。
我们可以考虑在统计文档个数时,为每个文档引入包含多少个词这样一个权重,以区别长短不同的文档,沿着这个思路,改写一下IDF公式:
我们用所有文档中的词做成词库,那么上式中:
综合上面的推导过程,我们知道,本文所定义的词权重公式,本质上是tf-idf为长短文档引入权重的加强版,而该公式的应用也极为简单,只需要从词库中读取该词词频、词库总词频即可。
时间复杂度最快可达O(1)级,比如词库以Hash表存储。
关于TF-IDF更完整的介绍及主流用法,建议参看阮一峰老师的博文《TF-IDF与余弦相似性的应用(一):自动提取关键词》。
四、公式应用
词权重用途很广,几乎词袋类算法中,都可以考虑使用。常见的应用有:
1、关键词抽取、自动标签生成
作法都很简单,分词后排除停用词,然后按权重值排序,取排在前面的若干个词即可。
2、文本摘要
完整的文本摘要功能实现很复杂也很困难,这里所指,仅是简单应用:由前面推导过程中可知,句子的权重等于分词结果各词的权重之和,从而获得句子的权重排序。
3、相似度计算
相似度计算,我们将在下一篇文中单独介绍。
五、演示程序
在演示程序显示词库结果时,是按本文所介绍的权重公式排序的。
演示程序与词库生成的相同:
下载地址:遗忘算法(词库生成、分词、词权重)演示程序.rar
特别感谢:王斌老师指出,本文公式实质上是TF-ICF。
六、联系方式: 1、QQ:老憨 244589712
2、邮箱:gzdmcaoyc@163.com
发表在 自然语言处理 | 标签为TF-IDF,自然语言处理,遗忘算法 |留下评论
非主流自然语言处理——遗忘算法系列(三):分词发表于2016年04月23号 由老憨
一、前言
前面介绍了词库的自动生成的方法,本文介绍如何利用前文所生成的词库进行分词。
二、分词的原理
分词的原理,可以参看吴军老师《数学之美》中的相关章节,这里摘取Google黑板报版本中的部分:
从上文中,可以知道分词的任务目标:给出一个句子S,找到一种分词方案,使下面公式中的P(S)最大:
不过,联合概率求起来很困难,这种情况我们通常作马尔可夫假设,以简化问题,即:任意一个词wi的出现概率只同它前面的词 wi-1 有关。
关于这个问题,吴军老师讲的深入浅出,整段摘录如下:
另外,如果我们假设一个词与其他词都不相关,即相互独立时,此时公式最简,如下:
这个假设分词无关的公式,也是本文所介绍的分词算法所使用的。
三、算法分析
问:假设分词结果中各词相互无关是否可行?
答:可行,前提是使用遗忘算法系列(二)中所述方法生成的词库,理由如下:
分析ICTCLAS广受好评的分词系统的免费版源码,可以发现,在这套由张华平、刘群两位博士所开发分词系统的算法中假设了:分词结果中词只与其前面的一个词有关。
回忆我们词库生成的过程可以知道,如果相邻的两个词紧密相关,那么这两个词会连为一个粗粒度的词被加入词库中,如:除“清华”、“大学”会是单独的词外,“清华大学”也会是一个词,分词过程中具体选用那种,则由它们的概率来决定。
也就是说,我们在生成词库的同时,已经隐含的完成了相关性训练。
关于ICTCLAS源码分析的文章,可以参看吕震宇博文:《天书般的ICTCLAS分词系统代码》。
问:如何实现分词?
答:基于前文生成的词库,我们可以假设分词结果相互无关,分词过程就比较简单,使用下面的步骤可以O(N)级时间,单遍扫描完成分词:
逐字扫描句子,从词库中查出限定字长内,以该字结尾的所有词,分别计算其中的词与该词之前各词的概率乘积,取结果值最大的词,分别缓存下当前字所在位置的最大概率积,以及对应的分词结果。
重复上面的步骤,直到句子扫描完毕,最后一字位置所得到即为整句分词结果。
3、算法特点
3.1、无监督学习;
3.2、O(N)级时间复杂度;
3.3、词库自维护,程序可无需人工参与的情况下,自行发现并添加新词、调整词频、清理错词、移除生僻词,保持词典大小适当;
3.4、领域自适应:领域变化时,词条、词频自适应的随之调整;
3.5、支持多语种混合分词。
四、演示程序下载
演示程序与词库生成的相同:
下载地址:遗忘算法(词库生成、分词、词权重)演示程序.rar
五、联系方式:
1、QQ:老憨 244589712
2、邮箱:gzdmcaoyc@163.com
发表在 自然语言处理 | 标签为无监督分词,自然语言处理,自适应词典,跨语种,遗忘算法 |13 条评论
非主流自然语言处理——遗忘算法系列(二):大规模语料词库生成发表于2016年04月23号 由老憨
一、前言
本文介绍利用牛顿冷却模拟遗忘降噪,从大规模文本中无监督生成词库的方法。
二、词库生成
算法分析,先来考虑以下几个问题
问:目标是从文本中抽取词语,是否可以考虑使用遗忘的方法呢?
答:可以,词语具备以相对稳定周期重复再现的特征,所以可以考虑使用遗忘的方法。这意味着,我们只需要找一种适当的方法,将句子划分成若干子串,这些子串即为“候选词”。在遗忘的作用下,如果“候选词”会周期性重现,那么它就会被保留在词库中,相反如果只是偶尔或随机出现,则会逐渐被遗忘掉。
问:那用什么方法来把句子划分成子串比较合适呢?
答:考察句中任意相邻的两个字,相邻两字有两种可能:要么同属于一个共同的词,要么是两个词的边界。我们都会有这样一种感觉,属于同一个词的相邻两字的“关系”肯定比属于不同词的相邻两字的“关系”要强烈一些。
数学中并不缺少刻划“关系”的模型,这里我们选择公式简单并且参数容易统计的一种:如果两个字共现的概率大于它们随机排列在一起的概率,那么我们认为这两个字有关,反之则无关。
如果相邻两字无关,就可以将两字中间断开。逐字扫描句子,如果相邻两字满足下面的公式,则将两字断开,如此可将句子切成若干子串,从而获得“候选词”集,判断公式如下图所示:
公式中所需的参数可以通过统计获得:遍历一次语料,即可获得公式中所需的“单字的频数”、“相邻两字共现的频数”,以及“所有单字的频数总和”。
问:如何计算遗忘剩余量?
答:使用牛顿冷却公式,各参数在遗忘算法中的含义,如下图所示:
牛顿冷却公式的详情说明,可以参考阮一峰老师的博文《基于用户投票的排名算法(四):牛顿冷却定律》。
问:参数中时间是用现实时间吗,遗忘系数取多少合适呢?
答:a、关于时间:
可以使用现实时间,遗忘的发生与现实同步。
也可以考虑用处理语料中对象的数量来代替,这样仅当有数据处理时,才会发生遗忘。比如按处理的字数为计时单位,人阅读的速度约每秒5至7个字,当然每个人的阅读速度并不相同,这里的参数值要求并不需要特别严格。
b、遗忘系数可以参考艾宾浩斯曲线中的实验值,如下图(来自互联网)
我们取6天记忆剩余量约为25.4%这个值,按每秒阅读7个字,将其代入牛顿冷却公式可以求得遗忘系数:
注意艾宾浩斯曲线中的每组数值代入公式,所得的系数并不相同,会对词库的最大有效容量产生影响。
二、该算法生成词库的特点
3.1、无监督学习
3.2、O(N)级时间复杂度
3.3、训练、执行为同一过程,可无缝处理流式数据
3.4、未登录词、新词、登录词没有区别
3.5、领域自适应:领域变化时,词条、词频自适应的随之调整
3.6、算法中仅使用到频数这一语言的共性特征,无需对任何字符做特别处理,因此原理上跨语种。
三、词库成熟度
由于每个词都具备一个相对稳定的重现周期,不难证明,当训练语料达到一定规模后,在遗忘的作用下,每个词的词频在衰减和累加会达到平衡,也即衰减的速度与增加的速度基本一致。成熟的词库,词频的波动相对会比较小,利用这个特征,我们可以衡量词库的成熟程度。
四、源码(C#)、演示程序下载
使用内附语料(在“可直接运行的演示程序”下可以找到)生成词库效果如下:
下载地址:遗忘算法(词库生成、分词、词权重)演示程序.rar
五、联系方式:
1、QQ:老憨 244589712
2、邮箱:gzdmcaoyc@163.com
发表在 自然语言处理 | 标签为未登录词发现,牛顿冷却公式,自然语言处理,词库生成,遗忘算法 |4 条评论
非主流自然语言处理——遗忘算法系列(一):算法概述发表于2016年04月19号 由老憨
一、前言
这里“遗忘”不是笔误,这个系列要讲的“遗忘算法”,是以牛顿冷却公式模拟遗忘为基础、用于自然语言处理(NLP)的一类方法的统称,而不是大名鼎鼎的“遗传算法”!
在“遗忘”这条非主流自然语言处理路上,不知不觉已经摸索了三年有余,遗忘算法也算略成体系,虽然仍觉时机未到,还是决定先停一下,将脑中所积梳理成文,交由NLP的同好们点评交流。
二、遗忘算法原理
能够从未知的事物中发现关联、提炼规律才是真正智能的标志,而遗忘正是使智能生物具备这一能力的工具,也是适应变化的利器,“遗忘”这一颇具负能量特征的家伙是如何实现发现规律这么个神奇魔法的呢?
让我们从巴甫洛夫的狗说起:狗听到铃声就知道开饭了。
铃声和开饭之间并不存在必然的联系,我们知道之所以狗会将两者联系在一起,是因为巴甫洛夫有意的将两者一次次在狗那儿重复共现。所以,重复是建立关联的必要条件。
我们还可以想像,狗在进食的时候听到的声音可能还有鸟叫声、风吹树叶的沙沙声,为什么这些同样具备重复特征声音却没有和开饭建立关系呢?
细分辨我们不难想到:铃声和开饭之间不仅重复共现,而且这种重复共现还具备一个相对稳定的周期,而其他的那些声音和开饭的共现则是随机的。
那么遗忘又在其中如何起作用的呢?
1、所有事物一视同仁的按相同的规律进行遗忘;
2、偶尔或随机出现的事物因此会随时间而逐渐淡忘;
3、而具有相对稳定周期重复再现的事物,虽然也按同样的规律遗忘,但由于周期性的得到补充,从而可以动态的保留在记忆中。
在自然语言处理中,很多对象比如:词、词与词的关联、模板等,都具备按相对稳定重现的特征,因此非常适用遗忘来处理。
三、牛顿冷却公式
那么,我们用什么来模拟遗忘呢?
提到遗忘,很自然的会想到艾宾浩斯遗忘曲线,如果这条曲线有个函数形式,那么无疑是模拟遗忘的最佳建模选择。遗憾的是它只是一组离散的实验数据,但至少让我们知道,遗忘是呈指数衰减的。
另外有一个事实,有的人记性好些,有的人记性则差些,不同人之间的遗忘曲线是不同的,但这并不会从本质上影响不同人对事物的认知,也就是说,如果存在一个遗忘函数,它首先是指数形式的,其次在实用过程中,该函数的系数并不那么重要。
这提醒我们,可以尝试用一些指数形式的函数来代替遗忘曲线,然后用实践去检验,如果能满足工程实用就很好,这样的函数公式并不难找,比如:退火算法、半衰期公式等。
有次在阮一峰老师的博客上看关于帖子热度排行的算法时,其中一种方法使用的是牛顿冷却定律,遗忘与冷却有着相似的过程、简洁优美的函数形式、而且参数只与时间相关,这些都让我本能想到,它就是我想要的“遗忘公式”。
在实践检验中,牛顿冷却公式,确实有效好用,当然,不排除有其他更佳公式。
四、已经实现的功能
如果把自然语言处理比作从矿砂中淘金子,那么业界主流算法的方向是从矿砂中将金砂挑出来,而遗忘算法的方向则是将砂石筛出去,虽然殊途但同归,所处理的任务也都是主流中所常见。
本系列文章将逐一讲解遗忘算法如何以O(N)级算法性能实现:
1、大规模语料词库生成
1.1、跨语种,算法语种无关,比如:中日韩、少数民族等语种均可支持
1.2、未登录词发现(只要符合按相对稳定周期性重现的词汇都会被收录)
1.3、领域自适应,切换不同领域的训练文本时,词条、词频自行调整
1.4、词典成熟度:可以知道当前语料训练出的词典的成熟程度
1.1、跨语种,算法语种无关,比如:中日韩、少数民族等语种均可支持
1.2、未登录词发现(只要符合按相对稳定周期性重现的词汇都会被收录)
1.3、领域自适应,切换不同领域的训练文本时,词条、词频自行调整
1.4、词典成熟度:可以知道当前语料训练出的词典的成熟程度
2、分词(基于上述词库技术)
2.1、成长性分词:用的越多,切的越准
2.2、词典自维护:切词的同时动态维护词库的词条、词频、登录新词
2.2、领域自适应、跨语种(继承自词库特性)
2.1、成长性分词:用的越多,切的越准
2.2、词典自维护:切词的同时动态维护词库的词条、词频、登录新词
2.2、领域自适应、跨语种(继承自词库特性)
3、词权值计算
3.1、关键词提取、自动标签
3.2、文章摘要
3.3、长、短文本相似度计算
3.4、主题词集
3.1、关键词提取、自动标签
3.2、文章摘要
3.3、长、短文本相似度计算
3.4、主题词集
五、联系方式:
1、QQ:老憨 244589712
2、邮箱:gzdmcaoyc@163.com
发表在 自然语言处理 | 标签为牛顿冷却公式,自然语言处理,遗忘算法 |留下评论
达观数据对于大规模消息数据处理的系统架构发表于2015年12月2号 由recommender
达观数据是为企业提供大数据处理、个性化推荐系统服务的知名公司,在应对海量数据处理时,积累了大量实战经验。其中达观数据在面对大量的数据交互和消息处理时,使用了称为DPIO的设计思路进行快速、稳定、可靠的消息数据传递机制,本文分享了达观数据在应对大规模消息数据处理时所开发的通讯中间件DPIO的设计思路和处理经验(达观数据架构师 桂洪冠)
一、数据通讯进程模型
在设计达观数据的消息数据处理机制时,首先充分借鉴了ZeroMQ和ProxyIO的设计思想。ZeroMQ提供了一种底层的网络通讯框架,提供了基本的RoundRobin负载均衡算法,性能优越,而ProxyIO是雅虎的网络通讯中间件,承载了雅虎内部大量计算节点间的实时消息处理。但是ZeroMQ没有实现基于节点健康状态的最快响应算法,并且ZeroMQ和ProxyIO对节点的状态管理,连接管理,负载均衡调度等也需要各应用自己来实现。达观科技在借鉴两种设计思路的基础上,从进程模型、服务架构、线程模型、通讯协议、负载均衡、雪崩处理、连接管理、消息流程、状态监控等各方面进行了开拓,开发了DPIO(达观ProxyIO的简写,下文统称DPIO),确保系统高性能处理相关数据。
在DPIO的整个通讯框架体系中,采用集中管理、统一监控策略管理节点提供服务,节点间直接进行交互,并不依赖统一的管理节点(桂洪冠)。几种节点间通过http或者tcp协议进行消息传递、配置更新、状态跟踪等通讯行为。集群将不同应用的服务抽象成组的概念,相同应用的服务启动时加入的相同的组。每个通讯组有两种端点client和server。应用启动时通过配置决定自己是client端点还是server端点,在一个组内,每个应用只能有一个身份;不同组没要求。
- 监控节点,顾名思义即提供系统监控服务的,用来给系统管理员查看集群中节点的服务状态及负载情况,系统对监控节点并无实时性及稳定性要求,在本模型中是单点系统。
- 在上图的架构中把管理节点设计成双master结构,参考zookeeper集群管理思路,多个master通过一定算法分别服务于集群中一部分节点,相对于另外的服务节点则为备份管理节点,他们通过内部通讯同步数据,每个管理节点都有一个web服务为监控节点提供服务节点的状态数据。
- 服务节点即是下文要谈的代理服务,根据服务对象不同分为应用端代理和服务端代理。集群中的服务节点根据提供服务的不同分为多个组,每个代理启动都需要注册到相应的组中,然后提供服务。
二、DPIO消息传递逻辑架构
DPIO服务节点内/间的通讯及消息传递模型见下图:
- clientHost和serverHost间使用socketapi进行tcp通讯,相同主机内部的多个进程间使用共享内存传递消息内容,client和clientproxy、server和serverproxy之间通过domain socket进行事件通知;在socket连接的一方收到对端的事件通知后,从共享内存中获取消息内容。
- clientproxy/serverproxy启动时绑定到host的一个端口响应应用api的连接,在连接到来时将该api对应的共享内存初始化,将偏移地址告诉给应用。clientproxy和serverproxy中分别维护了一个到应用api的连接句柄队列,并通过io复用技术监听这些连接上的读写事件。
- serverproxy在启动时通过socket绑定到服务器的一个端口,并以server身份注册到一个group监听该端口的连接事件,当事件到达时回调注册的事件处理函数响应事件。
- 在serverproxy内部通过不同的thread分别管理从本地应用建立的连接和从clientproxy建立的连接。thread的个数在启动proxy时由用户指定,默认是分别1个。每个clientproxy启动时会以client身份注册到一个group,并建立到同组的所有serverproxy的连接,clientproxy内部包含了连接的自管理能力及failover的处理(将在下面连接管理部分描述)。 DPIO实现了负载均衡,路由选择和透明代理的功能。
三、线程模型
DPIO的线程模型:
App epoll thread检测从api来的请求信息,并将请求信息转发到待处理队列中。从已处理队列中获取应答包,并将处理结果转发给api
Io epoll thread检测从远端的proxy来的可写事件,并将请求包转发到远端的proxy。检测从远端的proxy的可读事件,并将应答包放在已处理队列中
Monitor thread检测DPIO的工作状态请求,将DPIO的工作状态返回。并将决定Io epoll thread和app epoll thread的负载均衡(桂洪冠)。
四、通信协议
- Api与DPIO通信协议
- 共享内存存储消息格式
字段
含义
长度
protocol len
协议包的总长度
4bytes
protocol head len
协议头的长度
1byte
Version_protocol_id
协议的版本号和协议号
1byte
Flag
消息标志,标志路由模式,是否记录来源地址,有二级路由,所以这个字段一定要Eg,末位表示要记录src,倒数第二位表示按roundrobin路由,倒数第3位表示按消息头路由,xxx
1byte
Proxy
来源/目的 proxy
2bytes
Api
来源/目的 api
2bytes
ApiTtl
协议包的发送时间
2Bytes
ClientTtl
消息存活的时间,后面添加,增加路由策略,选择app_server
2Bytes
ClientProcessTime
客户端处理所用时间
2Bytes
ServerTtl
消息存活的时间,后面添加,增加路由策略,选择app_client
2Bytes
timeout
协议包的超时时间
2 byte
Sid
消息序列号
4bytes
protocol body len
Body长度
4bytes
protocol body
消息体
Size
- 请求协议包
字段
含义
长度
protocol head len
协议头的长度
1byte
Version_protocol_id
协议的版本号和协议号
1byte
Flag
消息标志,标志路由模式,是否记录来源地址,有二级路由,所以这个字段一定要Eg,末位表示要记录src,倒数第二位表示按roundrobin路由,倒数第3位表示按消息头路由,xxx
1byte
ApiTtl
协议包的发送时间
2bytes
Timeout
协议包的超时时间
2bytes
Api
来源/目的 api
2bytes
Sid
消息序列号
4byte
Begin_offset
协议包的起始偏移
4bytes
len
协议包长度
4bytes
- 响应协议包
字段
含义
长度
protocol head len
协议头的长度
1byte
Version_protocol_id
协议的版本号和协议号
1byte
Flag
消息标志,标志路由模式,是否记录来源地址,有二级路由,所以这个字段一定要Eg,末位表示要记录src,倒数第二位表示按roundrobin路由,倒数第3位表示按消息头路由,xxx
1byte
Result
处理结果
1byte
sid
消息序列号
4bytes
begin_offset
协议包的起始偏移
4bytes
len
协议包长度
4bytes
- Proxy与监控中心的监控信息
- 请求协议包
字段
含义
长度
protocol len
协议包的总长度
4bytes
protocol head len
协议头的长度
4bytes
Version
协议的版本号
4bytes
protocol id
协议的协议号
4bytess
status_version
当前状态版本
4bytes
Proxy_identify_len
该proxy标识长度
4bytess
Proxy_identify
该proxy 标识
4bytes
protocol body
消息体
Size
- 应答包
字段
含义
长度
protocol len
协议包的总长度
4bytes
protocol head len
协议头的长度
4bytes
Version
协议的版本号
4bytes
protocol id
协议的协议号
4bytess
protocol body len
Body长度
4bytes
protocol body
消息体
Size
五、负载均衡
DPIO的负载均衡基于最快响应法
DPIO将所有的统计信息更新到监控中心,监控中心通过处理所有的节点的状态信息,统一负责负载均衡。
DPIO从监控中心获取所有连接的负载均衡策略。每个连接知道只需知道自己的处理能力。
以上图为例,有三个proxy server处理程序。处理能力分别为50、30、20,一次epoll过程能够同时探测多个连接的可写事件。
假设:三个proxy server的属于同一epoll thread,且三个proxy server假设都处理能力无限大。
限制:如果刚开始时待处理队列的数据包个数为100个,多次发送轮回后proxy server A≥proxy server B≥proxy server C, 每个发送的最多发送协议包数为待处理队列协议包个数 * 该连接所占权重
六、雪崩处理
大型在线服务,特别是对于时延敏感的服务,当系统外部请求超过系统服务能力,而没有适当的过载保护措施时,当系统累计的超时请求达到一定规模,将可能导致系统缓冲区队列溢出,后端服务资源耗尽,最终像雪崩一样形成恶性循环。这时系统处理的每个请求都因为超时而无效,系统对外呈现的服务能力为0,且这种情况下不能自动恢复。
我们的解决策略是对协议包进行生命周期管理,现在协议包进出待处理队列和已处理队列时进行超时检测和超时处理(超时则丢弃)。
proxy client:
当app epoll thread将协议包放入待处理队列时,会将该协议包的发送时间、该协议包的超时时间,当前时间戳来判断该协议包是否已经超时。
当app epoll thread将协议包从已处理队列中移除时,会将该协议包的发送时间、该协议包的超时时间,已经当前时间戳来判断该协议包是否已经超时。
当Io epoll thread将协议包从待处理队列中移除时,会将该协议包的发送时间、该协议包的超时时间,当前时间戳,该连接的协议包的平均处理时间移除。
当io epoll thread将协议包放入已处理队列时,会将将该协议包的发送时间、该协议包的超时时间,已经当前时间戳来判断该协议包是否已经超时。
proxy server:
当App epoll thread将协议包从待处理队列中移除时,会将该协议包在客户端的处理时间、该协议包的超时时间、该协议包的proxy server接收时间戳、当前时间戳来判断该协议包是否已超时。
当app epoll thread将协议包放入已处理队列时,会将该协议包的发送时间、该协议包的超时时间,已经当前时间戳来判断该协议包是否已经超时。
当io epoll thread将协议包从已处理队列中移除时,会将该协议包的发送时间、该协议包的超时时间,已经当前时间戳来判断该协议包是否已经超时。
当io epoll thread将协议包放入待处理队列时,会将该协议包的发送时间、该协议包的超时时间来判断该协议包是否已超时。
七、连接管理
红黑树:
红黑树:保存所有连接的最近的读/写时间戳。
当epoll_wait时,首先从红黑树中获取oldest的时间戳,并将当前时间戳与oldest时间戳的时间差作为epoll_wait的超时时间,当连接中有可读/写事件发送时,首先从红黑树中删除该节点,当可读/写事件处理完毕后,再将节点插入到红黑树中,当处理完所有连接的可读/写事件时,再从红黑树中依次从移除时间戳小于当前时间戳的连接,并触发该连接的timeout事件。
八、消息处理流程
- apiclient通过调用api的接口,将消息传给
- api接受消息体,从共享内存中申请内存,填写消息头size(协议总长度)、Offset (协议版本号和协议号)、Headsize (协议头的总长度)、flag(路由策略),ApiTtl (协议包的发送时间)、timeout (协议包的超时时间)、sid(序列号),size(消息体长度)字段,封装成协议包,将协议包写入共享内存。
- api通过socket发送请求给proxy。
- app epoll thread通过检测api的可读事件,接受请求。通过解析请求内容,获取请求协议包所在的共享内存的偏移、请求协议包的长度和api连接index加入到处理队列。
- proxy client的io epoll thread通过检测对端DPIO连接的可写事件,从发送队列中获取请求包,将api的index加入到协议包的api index字段。
- proxy client的io epoll thread从共享内存中读取协议包,释放由请求包中所标识的内存空间。
- proxy server的io epoll thread通过检测对端DPIO的可读事件,接受请求。
- proxy server的io epoll thread从共享内存中申请空间,将proxy的index加入到协议包的proxy index字段。将请求内存写入到申请的空间中。
- proxy server的io epoll thread 将协议包在共享内存的偏移和协议包的长度加入的待处理队列中。
- app epoll thread从待处理队列中获取请求包,将协议包转发给相应的api进行处理。
- api通过检测DPIO的可读事件,解析请求内容。
- api通过解析请求内容,获取请求协议包在共享内存中的偏移和请求协议包的长度。从共享内存中读取请求内容,并释放相应空间。
- api将请求协议包返回给应用层进行处理。
- 应用层将应答包传给api。
- Api从共享内存中申请空间,将应答包写入到共享内存中。
- Api将应答包在共享内存中的偏移和应答包的大小写入到共享内存中。
- App epoll thread通过检测可读事件,将应答包写入到已处理队列中。
- proxy server的Io epoll thread通过检测对端的DPIO的可写事件,将已处理队列中获取应答包。
- proxy server的Io epoll thread从共享内存中读取应答包。
- Proxy client的Io epoll thread检测可读事件,读取应答包。
- Proxy client的Io epoll thread通过解析应答包,从共享内存中申请空间,将应答包写入到申请的内存中。
- Proxy client的Io epoll thread将应答包移入到已处理队列。
- App epoll thread通过检测api的可写事件,将已处理队列中获取应答包。
- App epoll thread发送应答包。
- Api通过检测可读事件,获取应答包,通过解析应到包,获取应答包在共享内存中的偏移和应到的大小,从共享内存中读取应到包。
- Api将应答包返回给应用端。(桂洪冠 陈运文)。
九、状态监控
连接池中存在:当前可用连接个数
连接池中再分别获取每个连接的状态
每个可用连接分别维护以下信息:
连接处理的数据包个数、连接send失败次数、连接协议包的平均处理时间。
连接的连接状态(当重连失败达到一定次数时,定义为连接失败)。
连接的重连次数、连接的超时次数。
当监控线程accept到client的连接时,解析请求内容,然后调用连接池对象的statistics方法,连接池对象首先写入自己的统计信息,然后分别调用每个连接的statistics方法,每个连接分别填写自己的统计信息
本文小结
大规模消息传递会遇到很多可靠性、稳定性的问题,DPIO是达观在处理大数据通讯时的一些经验,和感兴趣的朋友们分享,期待与大家不断交流与合作
发表在 数据挖掘 | 标签为数据处理,数据通讯 |留下评论
在微信公众号里使用LaTeX数学公式发表于2015年11月17号 由52nlp
因为有同学在微信后台咨询这个问题,所以这里简单记录一下,其实自己之前也摸索了一些方法,不是太完美,目前所使用的这个方法算是折中后比较好的。
这段时间在鼓捣“NLPJob”这个公众号,特别是微信公众号支持“原创声明”后,就很乐意将52nlp上积攒的一些文章搬上去,但是逐渐会遇到一些数学公式的问题。目前在52nlp上用的是mathjax完美支持LaTeX数学公式展现,但是微信公众号的编辑器没有这个支持,另外mathjax支持的公式形式不是图片形式,所以不能直接将文章拷贝上去,但是如果是数学公式图片,微信编辑器可以直接拷贝,所以最直接的想法就是将mathjax支持的LaTeX公式转换为公式图片保存在文章中,然后再全文拷贝到微信公众号编辑器中。
其实在mathjax之前,网页上的很多数学公式都是用这种折中的方式,包括很多wordpress数学公式插件,当年我也因为52nlp上的公式问题还自己动手写了一个小的wordpress插件,但是当mathjax出现之后,之前的方案就显得很一般了。所以就开始尝试找一下支持img缓存的LaTeX公式插件,不过多数都不满意或者有瑕疵,甚至自己又开始动手修改代码,然后blablabla….,最终发现quicklatex这个神器和它的wordpress插件QuickLaTeX,几乎完美支持和兼容Mathjax所支持的LaTeX数学公式。方法很简单,只要在wordpress中安装quicklatex,然后在文章的开头添加一个:[latexpage] ,然后文章中所有的latext公式都会转换为图片形式,类似昨天发出的rickjin的这篇文章:LDA数学八卦:神奇的Gamma函数(1)。当然需要先在wordpress中完成编辑转换,再全文拷贝到微信公众号中,微信会自动的将这些图片上传到它自己的图片服务器上。不过依然希望微信公众号编辑器能早日支持LaTeX公式编辑甚至Mathjax。
发表在 随笔 | 标签为latex公式,latex数学公式,MathJax,微信,微信latex,微信公众号,微信公众号数学公式编辑器,微信公式编辑器,微信数学公式 |2 条评论
斯坦福大学深度学习与自然语言处理第四讲:词窗口分类和神经网络发表于2015年09月14号 由 52nlp
斯坦福大学在三月份开设了一门“深度学习与自然语言处理”的课程:CS224d: Deep Learning for Natural Language Processing,授课老师是青年才俊 Richard Socher,以下为相关的课程笔记。
第四讲:词窗口分类和神经网络(Word Window Classification and Neural Networks)
推荐阅读材料:
- [UFLDL tutorial]
- [Learning Representations by Backpropogating Errors]
- 第四讲Slides [slides]
- 第四讲视频 [video]
以下是第四讲的相关笔记,主要参考自课程的slides,视频和其他相关资料。
继续阅读 →
继续阅读 →
发表在 机器学习,深度学习,自然语言处理 | 标签为Deep Learning,Deep Learning公开课,Deep NLP,DL,NER,Richard Socher,softmax,word vectors,word2vec,wordnet,二元逻辑回归,人名识别,公开课,分类,分类器,前馈网络记录,反向传播算法,命名实体识别,回归,地名识别,斯坦福大学,机器学习,梯度下降,深度学习,深度学习与自然语言处理,深度学习技术,深度学习模型,神经元,神经网络,窗口向量,窗口向量分类,自然语义处理,自然语言处理,词向量,词嵌入,语义词典,逻辑回归,随机梯度下降 |3 条评论
出门问问宣布完成由Google投资的C轮融资,累计融资7500万美金发表于2015年09月2号 由 52nlp
注:出门问问是我们的老朋友,创始人李志飞也是NLP和机器翻译领域的大牛,今天出门问问拿到了Google的C轮融资,志飞兄第一时间和我分享了这条新闻,太牛了。
人工智能创业公司出门问问(Mobvoi),于近日完成了由Google投资的C轮融资,累计融资7500万美金。现有投资方包括红杉资本、真格基金,SIG海纳亚洲、圆美光电、及歌尔声学。此轮投资Google并不控股,出门问问团队依旧有绝对控制权。
此次由Google投资的C轮融资,能够保证出门问问在人工智能领域长期持续深耕,专注核心技术上的进一步研发,在可穿戴、车载以及机器人领域拓展新的人机交互产品形态,更深入地完善用户体验,在吸引全球顶尖技术与商务人才上更具优势。对于海外市场的扩展,此次融资也将发挥非常重要的作用。
Google 企业发展部副总裁Don Harrison 说到选择投资出门问问的原因:“出门问问研发了非常独特自成体系的语音识别与自然语言处理技术。我们被他们的创新科技与发展潜力打动,所以我们很迅速地决定用投资的方式帮助他们在未来快速成长。”
红杉资本全球执行合伙人沈南鹏评价:“出门问问一直处于高速的不断创新过程中,从移动app到硬件产品到语音搜索平台,不同形式的产品背后是团队长期以来形成的强大技术核心,获得Google的投资是对这种中国原创能力的最好肯定。我很高兴Google这样的巨头看好出门问问,并和我们一起投入到这支高速创新的团队中。”
真格基金创始人徐小平说:“我第一次遇见谷歌科学家李志飞博士,是三年前。那时候,他的语音搜索创业计划,真是一个“异想天开”的梦。志飞相信自己的梦,相信自己的技术,相信市场对这个技术产品的需求,历经万难,终于“搜索”到了属于他自己的那片天空。志飞的创业历程,是又一个中国好故事,会激励更多人追求并实现自己的好梦。”
志同道合是此次融资达成的最重要的原因。扎实做技术和产品,运用科技的力量改变人们的日常生活,是出门问问一直笃信的价值观。
出门问问CEO 李志飞表示:“引入Google的投资,不仅意味Google对于我们技术的认可,更是源于双方持有共同的价值观,通过对人工智能技术的极致追求,打造毫不妥协的用户体验。”
与Google相似,出门问问也是信仰“工程师文化”的团队,强大的研发团队由Google前科学家、人工智能专家领衔,团队成员来自哈佛、MIT、斯坦福、剑桥、清华等名校名企。
此次融资是中国人工智能创业公司首次获得像Google这样的国际技术巨头的投资与认可。这在某种程度上说明,在人工智能领域,中国的创业公司不容小觑。
继续阅读 →
继续阅读 →
0 0
- QA问答系统中的深度学习技术实现
- QA问答系统中的深度学习技术实现
- QA问答系统
- 问答系统(QA)0
- QA问答系统
- 用深度学习解决问答(QA)方法
- 深度学习之《社交网络问答系统-问题重复检测任务》实现
- 基于深度学习的VQA(视觉问答)技术
- 深度学习quora问答
- 深度学习笔记——利用深度学习构建社区问答系统之相似问题对匹配
- AIR 040丨加拿大皇家学院院士李明:深度学习在机器人问答中的应用
- 深度学习在推荐系统中的应用
- 简单问答系统实现原理
- 基于深度学习的智能问答
- 基于深度学习的智能问答
- 智能问答系统学习笔记
- 问答系统(QA)1—基于词典的正向最大匹配算法
- 基于Servlet的技术问答网站系统实现(附源码)
- Android中AsyncTask的使用场景、使用时的注意事项以及如何关闭
- poj 3254 Corn Fields(状压dp)
- android开发中需要关闭指定activity的方法
- Vector3.Slerp 球形插值详解
- web页面排版(2) - css3 弹性布局和多列布局
- QA问答系统中的深度学习技术实现
- 欢迎使用CSDN-markdown编辑器
- PyQt4 常用
- 安卓中的MVP模式
- Unity编程Tips
- 单例模式之双锁机制
- WdatePicker详解
- 第34篇 一对多自由控制语音(十三)
- CentOS 7中firewall防火墙详解和配置以及切换为iptables防火墙


