Spark on Yarn Client和Cluster模式详解
来源:互联网 发布:淘宝重复铺货定义规则 编辑:程序博客网 时间:2024/06/04 18:17
Spark在YARN中有yarn-cluster和yarn-client两种运行模式:
I. Yarn ClusterSpark Driver首先作为一个ApplicationMaster在YARN集群中启动,客户端提交给ResourceManager的每一个job都会在集群的worker节点上分配一个唯一的ApplicationMaster,由该ApplicationMaster管理全生命周期的应用。因为Driver程序在YARN中运行,所以事先不用启动Spark Master/Client,应用的运行结果不能在客户端显示(可以在history server中查看),所以最好将结果保存在HDFS而非stdout输出,客户端的终端显示的是作为YARN的job的简单运行状况。
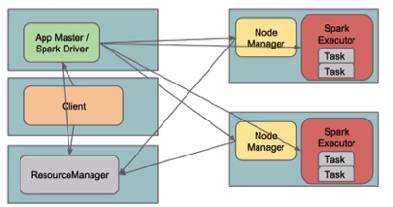
by @Sandy Ryza

by 明风@taobao
从terminal的output中看到任务初始化更详细的四个步骤:
1. 由client向ResourceManager提交请求,并上传jar到HDFS上
这期间包括四个步骤:
a). 连接到RM
b). 从RM ASM(ApplicationsManager )中获得metric、queue和resource等信息。
c). upload app jar and spark-assembly jar
d). 设置运行环境和container上下文(launch-container.sh等脚本)
这期间包括四个步骤:
a). 连接到RM
b). 从RM ASM(ApplicationsManager )中获得metric、queue和resource等信息。
c). upload app jar and spark-assembly jar
d). 设置运行环境和container上下文(launch-container.sh等脚本)
2. ResouceManager向NodeManager申请资源,创建Spark ApplicationMaster(每个SparkContext都有一个ApplicationMaster)
3. NodeManager启动Spark App Master,并向ResourceManager AsM注册
4. Spark ApplicationMaster从HDFS中找到jar文件,启动DAGscheduler和YARN Cluster Scheduler
5. ResourceManager向ResourceManager AsM注册申请container资源(INFO YarnClientImpl: Submitted application)
6. ResourceManager通知NodeManager分配Container,这时可以收到来自ASM关于container的报告。(每个container的对应一个executor)
7. Spark ApplicationMaster直接和container(executor)进行交互,完成这个分布式任务。
需要注意的是:
a). Spark中的localdir会被yarn.nodemanager.local-dirs替换
b). 允许失败的节点数(spark.yarn.max.worker.failures)为executor数量的两倍数量,最小为3.
c). SPARK_YARN_USER_ENV传递给spark进程的环境变量
d). 传递给app的参数应该通过–args指定。
部署:
环境介绍:
hdp0[1-4]四台主机
hadoop使用CDH 5.1版本: hadoop-2.3.0+cdh5.1.0+795-1.cdh5.1.0.p0.58.el6.x86_64
直接下载对应2.3.0的pre-build版本http://spark.apache.org/downloads.html
下载完毕后解压,检查spark-assembly目录:
然后输出环境变量HADOOP_CONF_DIR/YARN_CONF_DIR和SPARK_JAR(可以设置到spark-env.sh中)
如果使用cloudera manager 5,在Spark Service的操作中可以找到Upload Spark Jar将spark-assembly上传到HDFS上。
Spark Jar Location (HDFS)
spark_jar_hdfs_path
/user/spark/share/lib/spark-assembly.jar
默认值
The location of the Spark jar in HDFS
Spark History Location (HDFS) spark.eventLog.dir
/user/spark/applicationHistory
默认值
The location of Spark application history logs in HDFS. Changing this value will not move existing logs to the new location.
提交任务,此时在YARN的web UI和history Server上就可以看到运行状态信息。
II. yarn-client
(YarnClientClusterScheduler)查看对应类的文件
在yarn-client模式下,Driver运行在Client上,通过ApplicationMaster向RM获取资源。本地Driver负责与所有的executor container进行交互,并将最后的结果汇总。结束掉终端,相当于kill掉这个spark应用。一般来说,如果运行的结果仅仅返回到terminal上时需要配置这个。
在yarn-client模式下,Driver运行在Client上,通过ApplicationMaster向RM获取资源。本地Driver负责与所有的executor container进行交互,并将最后的结果汇总。结束掉终端,相当于kill掉这个spark应用。一般来说,如果运行的结果仅仅返回到terminal上时需要配置这个。
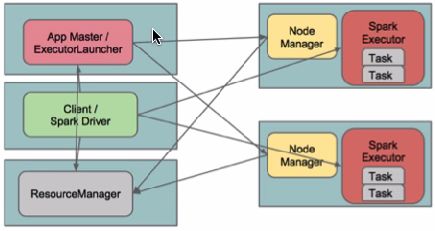
客户端的Driver将应用提交给Yarn后,Yarn会先后启动ApplicationMaster和executor,另外ApplicationMaster和executor都 是装载在container里运行,container默认的内存是1G,ApplicationMaster分配的内存是driver- memory,executor分配的内存是executor-memory。同时,因为Driver在客户端,所以程序的运行结果可以在客户端显 示,Driver以进程名为SparkSubmit的形式存在。
配置YARN-Client模式同样需要HADOOP_CONF_DIR/YARN_CONF_DIR和SPARK_JAR变量。
提交任务测试:
##最后将结果输出到terminal中
0 0
- Spark on Yarn Client和Cluster模式详解
- Spark on yarn client 和cluster模式运行序列图
- Spark on yarn有分为两种模式yarn-cluster和yarn-client
- Spark on Yarn-cluster与Yarn-client
- Spark-submit模式yarn-cluster和yarn-client的区别
- 分析spark on yarn cluster 与 client 模式的区别
- spark on yarn cluster 与 client 模式的区别
- Spark on YARN cluster & client 模式作业运行全过程分析
- spark yarn-client和yarn-cluster
- spark on yarn中yarn-cluster与yarn-client区别
- spark在yarn上面的运行模型:yarn-cluster和yarn-client两种运行模式:
- Spark on Yarn: Cluster模式Scheduler实现
- spark on yarn 两种运行模式(client 、cluster)对比
- 从源码角度看Spark on yarn client & cluster模式的本质区别
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- Spark:Yarn-cluster和Yarn-client区别与联系
- bootstrap table th内容太多表格撑破(自动换行)
- 学习记录第三天
- 游戏服务端之AOI概述
- 数据结构与算法分析笔记与总结(java实现)--排序算法的分析
- 自我成长之单例
- Spark on Yarn Client和Cluster模式详解
- 你还在为移动端选择器而捉急吗?【原创】
- iOS开发经验总结1
- maven的环境构建和简单使用
- 单点登录CAS9-服务端RememberMe
- CCF之相邻数对(java)
- 前端精选文摘:BFC 神奇背后的原理
- 数据结构与算法分析笔记与总结(java实现)--排序6:计数排序练习题
- BUG


