BSP模型学习
来源:互联网 发布:数控螺纹g92螺纹编程 编辑:程序博客网 时间:2024/05/29 04:35
第一次写CSDN,格式还不太熟悉,但是总算是一个好的开始,这个学期要保本校的研,但是由于大一大二大三上都不太努力,所以会有些难度,这博客是个新的开始,所以努力吧,这个博客主要是关于giraph部分的
BSP模型
BSP模型全称
整体同步并行计算模型(Bulk Synchronous Parallel Computing Model,简称BSP模型)
对BSP模型的一些理解
1.Processors指的是并行计算进程,它对应到集群中的多个结点,每个结点可以有多个Processor;
2.LocalComputation就是单个Processor的计算,每个Processor都会切分一些结点作计算;
3.Communication指的是Processor之间的通讯。接触的图计算往往需要做些递归或是使用全局变量,
在BSP模型中,对图结点的访问分布到了不同的Processor中,并且往往哪怕是关系紧密具有局部聚类特点的结点也未必会分布到同个Processor或同一个集群结点上,所有需要 用到的数据都需要通过Processor之间的消息传递来实现同步;
4.BarrierSynchronization又叫障碍同步或栅栏同步。每一次同步也是一个超步的完成和下一个超步的开始;
5.Superstep超步,这是BSP的一次计算迭代,拿图的广度优先遍历来举例,从起始结点每往前步进一层对应一个超步。
6.程序该什么时候结束呢?这个其实是程序自己控制,一个作业可以选出一个Proceessor作为Master,每个Processor每完成一个Superstep都向Master反馈完成情况,Master在N个Superstep之后发现所有Processor都没有计算可做了,便通知所有Processor结束并退出任务
这是某度里的介绍,感觉云里雾里的,但是了解了大概,下面是对查到的资料的一些总结,感觉认识的更加清楚
BSP模型是一种异步MIMD-DM模型(DM: distributed memory,SM: shared memory),BSP模型支持消息传递系统,块内异步并行,块间显式同步,该模型基于一个master协调,所有的worker同步(lock-step)执行, 数据从输入的队列中读取,该模型的架构如图所示:
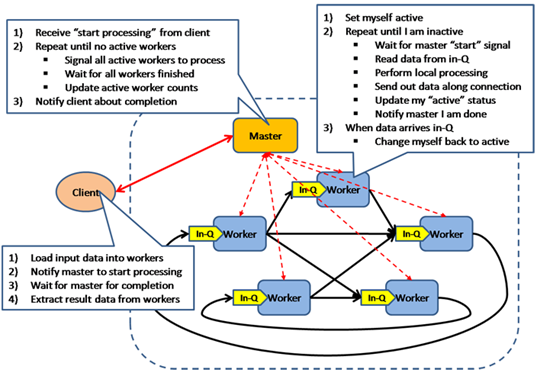
作为client 它要做到的是 作为master节点 它要做的是
1)将数据load到worker中 1)从client中接收开始的信号
2)向master发信号,让它开始运行 2) 重复下列操作直到没有活跃的worker
3)等待master节点完成 向所有active workers 发送运行的信号/等待所有的workers完成/更新active worker 数量
4)从workers里提取结果数据 3)向client报告完成
Worker要做的工作
1) 令自己变为active
2) 重复下列操作直到变得 inactive
等待master 发送 start信号
从输入队列in-q中读入数据
在本地进行相应的计算
在connection发送数据
更新本身的 active的数据
向master发送 本节点已经完成
3)当输入队列里来了新的数据 把自己状态改成active
参数描述
BSP并行计算模型可以用 p/s/g/I 4个参数进行描述:
1. P为处理器数目(带有存储器)
2. S为处理器的计算速度
3. g为每秒本地计算操作的数目/通信网络每秒传送的字节数 称之为选路器吞吐率,视为带宽因子 (time steps/packet)=1/bandwidth
4.I为全局的同步时间开销,称之为全局同步之间的时间间隔 (Barrier synchronization time)。
那么假设有p台处理器同时传送h个字节信息,则gh就是通信的开销。同步和通信的开销都规格化为处理器的指定条数
横向纵向理解BSP
BSP计算模型不仅是一种体系结构模型,也是设计并行程序的一种方法。BSP程序设计准则是整体同步(bulk synchrony),其独特之处在于超步(superstep)概念的引入。一个BSP程序同时具有水平和垂直两个方面的结构。从垂直上看,一个BSP程序由一系列串行的超步(superstep)组成,如图所示:
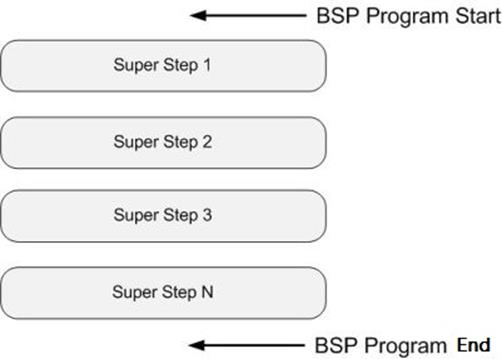
这种结构类似于一个串行程序结构。从水平上看,在一个超步中,所有的进程并行执行局部计算。一个超步可分为三个阶段,如图所示:
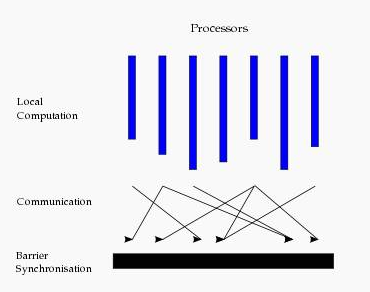
每一个超步中,分为3个阶段
1)本地计算阶段:在本地的计算
2全局通信阶段 :每个worker之间的数据的交流,即每个worker拿到不在本地的数据的阶段
3)栅栏同步阶段:是一个类似与栅栏的装置,使得已经完成的进程等待其它的进程结束
BSP模型的特点
1. BSP模型将计算划分为一个一个的超步(superstep),有效避免死锁。
2. 它将处理器和路由器分开,强调了计算任务和通信任务的分开,而路由器仅仅完成点到点的消息传递,不提供组合、复制和广播等功能,这样做既掩盖具体的互连网络拓扑,又简化了通信协议;
3. 采用障碍同步的方式以硬件实现的全局同步是在可控的粗粒度级,从而提供了执行紧耦合同步式并行算法的有效方式,而程序员并无过分的负担;
4. 在分析BSP模型的性能时,假定局部操作可以在一个时间步内完成,而在每一个超级步中,一个处理器至多发送或接收h条消息(称为h-relation)。假定s是传输建立时间,所以传送h条消息的时间为gh+s,如果 ,则L至少应该大于等于gh。
很清楚,硬件可以将L设置尽量小(例如使用流水线或大的通信带宽使g尽量小),而软件可以设置L的上限(因为L越大,并行粒度越大)。在实际使用中,g可以定义为每秒处理器所能完成的局部计算数目与每秒路由器所能传输的数据量之比。如果能够合适的平衡计算和通信,则BSP模型在可编程性方面具有主要的优点,而直接在BSP模型上执行算法(不是自动的编译它们),这个优点将随着g的增加而更加明显;
5. 为PRAM模型所设计的算法,都可以采用在每个BSP处理器上模拟一些PRAM处理器的方法来实现。
BSP模型的评价
1. 在并行计算时,Valiant试图也为软件和硬件之间架起一座类似于冯·诺伊曼机的桥梁,它论证了BSP模型可以起到这样的作用,正是因为如此,BSP模型也常叫做桥模型。
2. 一般而言,分布存储的MIMD模型的可编程性比较差,但在BSP模型中,如果计算和通信可以合适的平衡(例如g=1),则它在可编程方面呈现出主要的优点。
3. 在BSP模型上,曾直接实现了一些重要的算法(如矩阵乘、并行前序运算、FFT和排序等),他们均避免了自动存储管理的额外开销。
4. BSP模型可以有效的在超立方体网络和光交叉开关互连技术上实现,显示出,该模型与特定的技术实现无关,只要路由器有一定的通信吞吐率。
5. 在BSP模型中,超级步的长度必须能够充分的适应任意的h-relation,这一点是人们最不喜欢的。
6. 在BSP模型中,在超级步开始发送的消息,即使网络延迟时间比超级步的长度短,该消息也只能在下一个超级步才能被使用。
7. BSP模型中的全局障碍同步假定是用特殊的硬件支持的,但很多并行机中可能没有相应的硬件。
BSP模型与MAP-REDUCE对比
执行机制:MapReduce是一个数据流模型,每个任务只是对输入数据进行处理,产生的输出数据作为另一个任务的输入数据,并行任务之间独立地进行,串行任务之间以磁盘和数据复制作为交换介质和接口。
BSP是一个状态模型,各个子任务在本地的子图数据上进行计算、通信、修改图的状态等操作,并行任务之间通过消息通信交流中间计算结果,不需要像MapReduce那样对全体数据进行复制。
迭代处理:MapReduce模型理论上需要连续启动若干作业才可以完成图的迭代处理,相邻作业之间通过分布式文件系统交换全部数据。BSP模型仅启动一个作业,利用多个超步就可以完成迭代处理,两次迭代之间通过消息传递中间计算结果。由于减少了作业启动、调度开销和磁盘存取开销,BSP模型的迭代执行效率较高。
数据分割:基于BSP的图处理模型,需要对加载后的图数据进行一次再分布的过程,以确定消息通信时的路由地址。例如,各任务并行加载数据过程中,根据一定的映射策略,将读入的数据重新分发到对应的计算任务上(通常是放在内存中),既有磁盘I/O又有网络通信,开销很大。但是一个BSP作业仅需一次数据分割,在之后的迭代计算过程中除了消息通信之外,不再需要进行数据的迁移。而基于MapReduce的图处理模型,一般情况下,不需要专门的数据分割处理。但是Map阶段和Reduce阶段存在中间结果的Shuffle过程,增加了磁盘I/O和网络通信开销。
MapReduce的设计初衷:解决大规模、非实时数据处理问题。"大规模"决定数据有局部性特性可利用(从而可以划分)、可以批处理;"非实时"代表响应时间可以较长,有充分的时间执行程序。而BSP模型在实时处理有优异的表现。这是两者最大的一个区别。
简单总结一下,即在执行机制方面,MAP-REDUCE要把数据全都复制传输,但是BSP只要传递中间数据即可,迭代处理方面来讲,mapreduce要启动若干次作业,而BSP只要启动一次即可,效率更高,数据分割方面,将数据Load到worker后,依然需要一次分割过程,确定消息通信的路由,但是只有一次数据分割,后面的阶段只是中间消息通信,没有数据的迁移(这里不是很理解的)- BSP模型学习
- BSP模型
- 并行计算中的BSP模型
- BSP模型的相关讲解
- 漫谈大数据仓库与挖掘系统:BSP模型(应用于数据挖掘、机器学习的云计算模型)
- 并发计算模型BSP与SEDA
- BSP编程模型(以NMF为例,试验基于消息传递的模型BSP过程)
- BSP编程模型(以NMF为例,试验基于消息传递的模型BSP过程)
- BSP编程模型(以NMF为例,试验基于消息传递的模型BSP过程)
- BSP编程模型(以NMF为例,试验基于消息传递的模型BSP过程)
- bsp
- BSP
- BSP
- BSP
- bsp
- BSP
- BSP
- BSP
- 面试感悟:一名3年工作经验的程序员应该具备的技能
- 嵌入式系统开发流程
- 从命令行运行 MyBatis Generator
- 2-3-4-5 获取时间的客户端例子 TCP相关
- 内部类
- BSP模型学习
- 【车】当前状况与规划(1)
- MyBatis-Spring配置简单了解
- Java编程题练习2017-02-19
- java基础八类的组成
- c语言和c++中值传递、指针传递和引用传递的比较和区别
- HTTP 请求头中的 X-Forwarded-For
- 移动端布局
- 0219


