spark sql
来源:互联网 发布:遇见这软件靠谱吗 编辑:程序博客网 时间:2024/06/17 11:37
Spark SQL 的前身是Shark,它发布时Hive 可以说是SQL on Hadoop 的唯一选择(Hive 负责将SQL 编译成可扩展的MapReduce 作业),鉴于Hive 的性能以及与Spark 的兼容,Shark 由此而生。
Shark 即Hive on Spark,本质上是通过Hive 的HQL 进行解析,把HQL 翻译成Spark 上对应的RDD 操作,然后通过Hive 的Metadata 获取数据库里的表信息,实际为HDFS 上的数据和文件,最后由Shark 获取并放到Spark 上运算。Shark 的最大特性就是速度快,能与Hive 的完全兼容,并且可以在Shell 模式下使用rdd2sql 这样的API,把HQL 得到的结果集继续在Scala环境下运算,支持用户编写简单的机器学习或简单分析处理函数,对HQL 结果进一步分析计算。
在2014 年7 月1 日的Spark Summit 上,Databricks 宣布终止对Shark 的开发,将重点放到Spark SQL 上。在此次会议上,Databricks 表示,Shark 更多是对Hive 的改造,替换了Hive 的物理执行引擎,使之有一个较快的处理速度。然而,不容忽视的是,Shark 继承了大量的Hive代码,因此给优化和维护带来大量的麻烦。随着性能优化和先进分析整合的进一步加深,基于MapReduce 设计的部分无疑成为了整个项目的瓶颈。因此,为了更好的发展,给用户提供一个更好的体验,Databricks 宣布终止Shark 项目,从而将更多的精力放到Spark SQL 上。
Spark SQL 允许开发人员直接处理RDD,同时也可查询在 Hive 上存在的外部数据。SparkSQL 的一个重要特点是能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL 命令进行外部查询,同时进行更复杂的数据分析。Spark SQL 的特点如下。
引入了新的RDD 类型SchemaRDD,可以像传统数据库定义表一样来定义SchemaRDD。SchemaRDD 由定义了列数据类型的行对象构成。SchemaRDD 既可以从RDD 转换过来,也可以从Parquet 文件读入,还可以使用HiveQL 从Hive 中获取。
内嵌了Catalyst 查询优化框架,在把SQL 解析成逻辑执行计划之后,利用Catalyst 包里的一些类和接口,执行了一些简单的执行计划优化,最后变成RDD 的计算。
在应用程序中可以混合使用不同来源的数据,如可以将来自HiveQL的数据和来自SQL的数据进行Join 操作。Shark 的出现使得SQL-on-Hadoop 的性能比Hive 有了10~100 倍的提高,那么,摆脱了Hive 的限制,Spark SQL 的性能又有怎么样的表现呢?虽然没有Shark 相对于Hive 那样瞩目的性能提升,但也表现得优异,如图1-10 所示(其中,右侧数据为Spark SQL)。
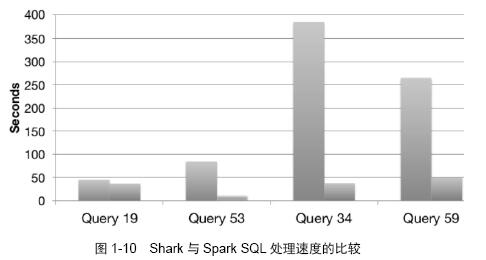
为什么Spark SQL 的性能会得到这么大的提升呢?主要是Spark SQL 在以下几点做了优化。
内存列存储(In-Memory Columnar Storage):Spark SQL 的表数据在内存中存储不是采用原生态的JVM 对象存储方式,而是采用内存列存储。
字节码生成技术(Bytecode Generation):Spark 1.1.0 在Catalyst 模块的Expressions 增加了Codegen 模块,使用动态字节码生成技术,对匹配的表达式采用特定的代码动态编译。另外对SQL 表达式都做了CG 优化。CG 优化的实现主要还是依靠Scala 2.10运行时的反射机制(Runtime Reflection)。
Scala 代码优化:Spark SQL 在使用Scala 编写代码的时候,尽量避免低效的、容易GC的代码;尽管增加了编写代码的难度,但对于用户来说接口统一。
- Spark Streaming+Spark SQL
- spark sql
- Spark SQL
- Spark SQL
- spark-sql
- spark sql
- spark sql
- spark sql
- Spark-Sql
- Spark SQL
- Spark SQL
- spark Sql
- spark-sql
- spark sql
- Spark Sql
- spark sql
- spark sql
- spark sql
- centos7下python连接 hive2
- ButterKnife注入时出错
- Java扩展知识点
- 一份非常内行的Linux LVM HOWTO
- 几个博弈小题总结 脑子是个好玩意,我也想有一个。
- spark sql
- Bootstrap学习-按钮
- A+B for Matrices
- 项目配置数据库连接
- iOS开发与PHP后台开发的交互
- 搬瓦工小折腾
- Fiddler的实践心得(六):显示请求服务器的IP地址(上)
- JavaScript高级程序设计[美]Nicholas C.Zakas著 读书笔记(三)
- Android Studio 安装过程及常见安装问题


