3-9遇到的一些概念 以及CNN相关概念2
来源:互联网 发布:java 内部类 编辑:程序博客网 时间:2024/05/23 12:40
转载自:https://my.oschina.net/zzw922cn/blog/519175
步长stride的概念:
1....一行有 11 个像素(Width = 11), 对一个 32 位(每个像素 4 字节)的图像, Stride = 11 * 4 = 44.
但还有个字节对齐的问题, 譬如:
一行有 11 个像素(Width = 11), 对一个 24 位(每个像素 3 字节)的图像, Stride = 11 * 3 + 3 = 36.
为什么不是 Stride = 33? 因为它是按 4 字节对齐的.
根据上面道理, 我们可以手动计算 Stride 的值:
1、Stride = 每像素占用的字节数(也就是像素位数/8) * Width;
2、如果 Stride 不是 4 的倍数, 那么 Stride = Stride + (4 - Stride mod 4);
2....就是你每个convolution之间移动多少,这决定了你一层需要扫多少遍。直观理解就是每次观察局部和上一次重合度。
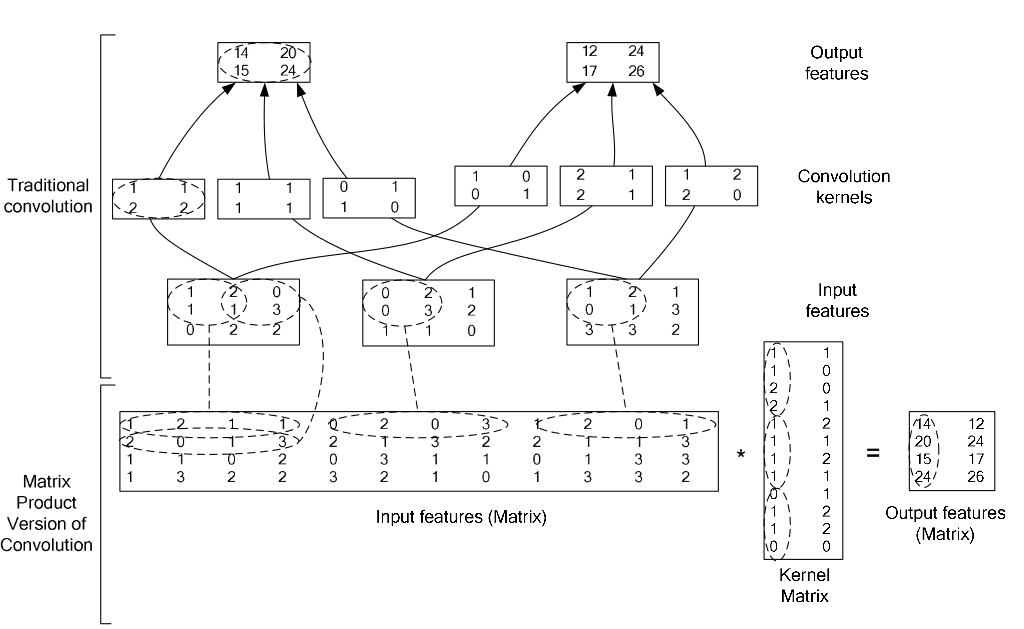
im2col层的内容:
softmax是一个分类器,计算的是类别的概率(Likelihood),是Logistic Regression 的一种推广。Logistic Regression 只能用于二分类,而softmax可以用于多分类。
softmax与softmax-loss的区别:
softmax计算公式:
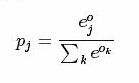
而softmax-loss计算公式:
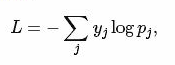
关于两者的区别更加具体的介绍,可参考:softmax vs. softmax-loss
用户可能最终目的就是得到各个类别的概率似然值,这个时候就只需要一个 Softmax层,而不一定要进行softmax-Loss 操作;或者是用户有通过其他什么方式已经得到了某种概率似然值,然后要做最大似然估计,此时则只需要后面的 softmax-Loss 而不需要前面的 Softmax 操作。因此提供两个不同的 Layer 结构比只提供一个合在一起的 Softmax-Loss Layer 要灵活许多。
不管是softmax layer还是softmax-loss layer,都是没有参数的,只是层类型不同而也
softmax-loss layer:输出loss值
最大似然概率 最大似然估计(Maximum likelihood estimation,MLE) 。
我承认上面的例子很牵强,不过主要是为了表达一个意思。后验概率在实际中一般是很难直接计算出来的,相反先验概率就容易多了。因此一般会利用先验概率来计算后验概率。
似然函数与最大似然估计
下面给出似然函数跟最大似然估计的定义。
我们假设f是一个概率密度函数,那么

是一个条件概率密度函数(θ 是固定的)
而反过来,
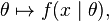
叫做似然函数 (x是固定的)。
一般把似然函数写成
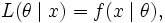
θ是因变量。
而最大似然估计 就是求在θ的定义域中,当似然函数取得最大值时θ的大小。
意思就是呢,当后验概率最大时θ的大小。也就是说要求最有可能的原因。
由于对数函数不会改变大小关系,有时候会将似然函数求一下对数,方便计算。
例子:
我们假设有三种硬币,他们扔到正面的概率分别是1/3,1/2,2/3。我们手上有一个硬币,但是我们并不知道这是哪一种。因此我们做了一下实验,我们扔了80次,有49次正面,31次背面。那么这个硬币最可能是哪种呢?我们动手来算一下。这里θ的定义域是{1/3,1/2,2/3}
![/begin{align}/Pr(/mathrm{H} = 49 /mid p=1/3) & = /binom{80}{49}(1/3)^{49}(1-1/3)^{31} /approx 0.000 //[6pt]/Pr(/mathrm{H} = 49 /mid p=1/2) & = /binom{80}{49}(1/2)^{49}(1-1/2)^{31} /approx 0.012 //[6pt]/Pr(/mathrm{H} = 49 /mid p=2/3) & = /binom{80}{49}(2/3)^{49}(1-2/3)^{31} /approx 0.054./end{align}](http://upload.wikimedia.org/math/2/4/a/24a9421e22fb6f08c316c27cfb95699f.png)
当p=2/3时,似然函数的值最大,因此呢,这个硬币很可能是2/3。
1.CNN介绍
CNN是应用在图像识别领域较多的一种机器学习算法,它与普通的神经网络有点类似,通过输入层然后乘以权重加上偏置,并且通过一个非线性的激活函数,即可得到输出值。CNN要做的是给定一幅图,对该图像进行编码最终即可将该图进行分类,而此过程中参数相比普通神经网络的参数要少,并且更加高效。
CNN通常由三个部分组成,分别是Conv layer、Pooling layer、Full-connected layer,它们组成了一个完整的CNN结构。通常输入是一幅图片,w*h*c,分别为图像的宽度高度以及频道数目(RGB),conv layer将计算输入层与权重矩阵的卷积,然后将该结果通过ReLU函数,Pooling layer用于对卷积后的矩阵进行抽样降维,例如按2*2矩形大小对原卷积矩阵分成若干个2*2大小的块,然后对于每个块只取其中的最大值,这样就可以使得维度降低为原来的1/4,而这就是max pooling方法,该方法的优点是减少了计算过程中参数的个数以及防止过拟合的产生。最后,经过的是MLP,方法类似,可以参考以前的博文(逻辑回归及感知器)。
总结一下,CNN就是将一幅图像经过一层又一层的编码过后,可以得到一个结论值,该值是对该图像的分类或描述。
2.CNN基本原理
当输入数据的维度很大时,如图像,就不能简单地每个输入值连接一个神经元,这时候每一个神经元要负责一片感知场,例如若输入数据为32*32*3,而感知场的个数为5*5,则此时conv layer的权重为5*5*3,因此共有75个权重。这样就可以有效减少参数的数目。
一般情况下,CNN的结构形式是:输入层--->Conv层--->Pooling层--->(重复Conv、Pooling层)...--->FC层--->输出结果。具体说来,通常还有以下几种形式:
Input--->((Conv--->ReLU--->Conv--->ReLU)--->Pooling)*3--->(FC--->ReLU)*2--->Output
Input--->(Conv--->ReLU--->Pooling)*2--->FC--->ReLU--->Output
通常输入层大小一般为2的整数倍,如32,64,96,224,384等。
通常卷积层使用较小的filter,如3*3,最多也就5*5,并且使用stride=1(stride表示卷积时对input进行每次移动一步,上下左右都是),并且对原来的input进行padding(使用0元素填充)。 例如 当stride 为1时候,会发生卷积的重叠。
Pooling层用于对卷积结果进行降低维度,例如选择2*2的区域对卷积层进行降低维度,则选择2*2区域的最大值作为输出,这样卷积层的维度就降为之前一半。
卷积层和Pooling层是CNN的核心所在,下图显示了CNN的结构图:

较低层是用来卷积以及抽样的,较高的层用来进行逻辑回归。
3.CNN的python实现
github:https://github.com/zzw922cn/machinelearning/tree/master/CNN
- 3-9遇到的一些概念 以及CNN相关概念2
- CNN中的一些概念
- CNN和图像的一些概念解释
- 一些硬件相关的概念
- OLAP的一些相关概念
- 神经网络和CNN的一些基础概念,基础知识的梳理
- 阅读中遇到的一些概念
- 一些编程中遇到的概念回顾
- 深度学习中遇到的一些概念
- 一些操作系统相关概念
- 一些相关概念
- 和3D相关的一些数学概念和公式
- Struts + Hibernate一些相关概念的小结
- 视频的一些相关概念(一)
- 视频的一些相关概念(二)
- 视频的一些相关概念(三)
- NP的一些相关概念和认识
- DSP开发相关的一些概念
- 个人作业1——四则运算题目生成
- swift开发中的一些小方法
- 正则详解及实战(JavaScript)
- Mysql 数据库(九)配置utf8编码集
- android系统UID定义
- 3-9遇到的一些概念 以及CNN相关概念2
- eclipse内存分配
- swift 面向协议学习思考
- activity与fragment---监听fragment返回键,fragment中横竖屏切换
- python pickle模块
- 微信小程序开发一
- 测试工具安装文件
- 安装postman
- CentOS 6.5 LNMP架构Zabbix 3.2.4监控端搭建


