通过GBDT组合的特征作为LR的输入
来源:互联网 发布:和平网络电视频道地址 编辑:程序博客网 时间:2024/04/30 18:03
scikit-learn中的apply() 函数有什么作用?

请问,这个函数功能是和 facebook使用的 GBDT + LR 是类似的么?
如果类似,请问该怎么利用好这个函数? 或者如何使得它的效果和facebook的方法一样?
作者:知乎用户
链接:https://www.zhihu.com/question/39254529/answer/80440989
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
链接:https://www.zhihu.com/question/39254529/answer/80440989
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我觉得你看这个就可以了。Feature transformations with ensembles of trees
讲的已经很详细了,我的理解是,apply可以把特征转换到一个更高维空间形成稀疏矩阵,然后就可以用线性模型了。这个思想和SVM里的核函数有点类似。
你看看它的代码:

讲的已经很详细了,我的理解是,apply可以把特征转换到一个更高维空间形成稀疏矩阵,然后就可以用线性模型了。这个思想和SVM里的核函数有点类似。
你看看它的代码:
至于这个函数怎么用,你看看它自带的例子,效果比一般的rf/gbdt要好。
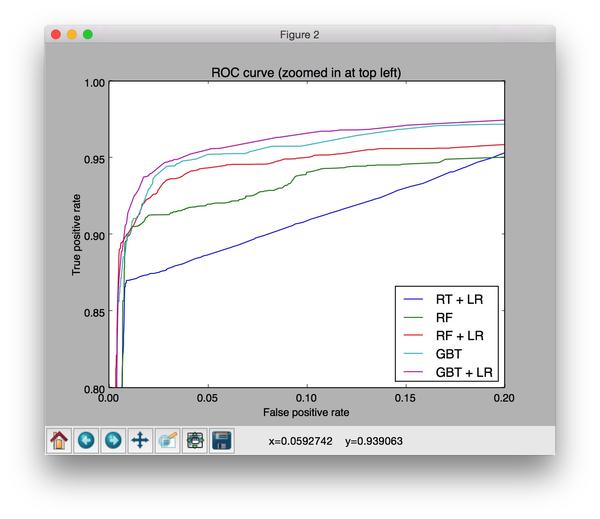
ROC曲线上来看,GBT+LR的效果是最好的。
我自己不用Python,不过推荐你用xgboost里xgboost.Booster的predict方法并将pred_leaf设置成TRUE,得到的结果应该是一样的,而且应该更好。因为xgboost自带一定的regularization而且利用了二阶泰勒展开的信息,所以学出来的feature应该会更好一些。因为Boosting本身就是一个学feature的过程,Friedman自己把Boosting过程看作是Additive Logistic Regression。其实得到的矩阵可以理解为很多Categorical Variable的不同Level,One-Hot Encoding展开了就是稀疏矩阵。
另外也要看你GBDT后面用什么模型,如果是Logistic Regression就One-Hot Encoding,如果后面是LibFFM,就直接用index,这样Variance应该还会小一些。
另外也要看你GBDT后面用什么模型,如果是Logistic Regression就One-Hot Encoding,如果后面是LibFFM,就直接用index,这样Variance应该还会小一些。
0 0
- 通过GBDT组合的特征作为LR的输入
- GBDT+LR特征融合的例子
- GBDT基本理论及利用GBDT组合特征的具体方法(收集的资料)
- GBDT构建组合特征
- GBDT算法的特征重要度计算
- GBDT+LR
- GBDT+LR
- GBDT参考 (GBDT+LR)
- 特征组合可以提高LR分类效果
- GBDT原理及利用GBDT构造新的特征-Python实现
- GBDT原理及利用GBDT构造新的特征-Python实现
- scikit-learn的GBDT工具进行特征选取。
- 组合索引的特征[摘]
- XGBoost Plotting API以及GBDT组合特征实践
- XGBoost Plotting API以及GBDT组合特征实践
- XGBoost Plotting API以及GBDT组合特征实践
- 逻辑回归LR的特征为什么要先离散化
- 逻辑回归LR的特征为什么要先离散化
- 将博客搬至CSDN
- #OSG+VS#第五周
- SSL 字符串
- LintCode :最大数
- tomcat7 内存配置修改方法
- 通过GBDT组合的特征作为LR的输入
- java基础学习之设计模式 十七
- 两种“两数互换的方式”
- java HotSpot虚拟机垃圾回收优化(一、Introduction)
- @TransactionConfiguration过时与替代写法
- computer-database 项目需求提测
- 使用asm.jar将Android手机屏幕投影到电脑
- 116. Populating Next Right Pointers in Each Node(unsolved)
- 关于typedef的用法小结


