Python && Golang性能分析指南
来源:互联网 发布:淘宝上的优惠券在哪领 编辑:程序博客网 时间:2024/06/06 05:20
转至http://www.oschina.net/translate/python-performance-analysis做个笔记。转载前请跟原作者联系!
虽然你所写的每个Python程序并不总是需要严密的性能分析,但是当这样的问题出现时,如果能知道Python生态系统中的许多种工具,这样总是可以让人安心的。
分析一个程序的性能可以归结为回答4个基本的问题:
1.它运行的有多块?
2.那里是速度的瓶颈?
3.它使用了多少内存?
4.哪里发生了内存泄漏?
下面,我们将用一些很酷的工具,深入细节的回答这些问题。
使用time工具粗糙定时
首先,我们可以使用快速然而粗糙的工具:古老的unix工具time,来为我们的代码检测运行时间。
$ time python yourprogram.pyreal 0m1.028suser 0m0.001ssys 0m0.003s上面三个输入变量的意义在文章 stackoverflow article 中有详细介绍。简单的说:- real - 表示实际的程序运行时间
- user - 表示程序在用户态的cpu总时间
- sys - 表示在内核态的cpu总时间
通过sys和user时间的求和,你可以直观的得到系统上没有其他程序运行时你的程序运行所需要的CPU周期。
若sys和user时间之和远远少于real时间,那么你可以猜测你的程序的主要性能问题很可能与IO等待相关。
使用计时上下文管理器进行细粒度计时
我们的下一个技术涉及访问细粒度计时信息的直接代码指令。这是一小段代码,我发现使用专门的计时测量是非常重要的:
timer.py
import timeclass Timer(object): def __init__(self, verbose=False): self.verbose = verbose def __enter__(self): self.start = time.time() return self def __exit__(self, *args): self.end = time.time() self.secs = self.end - self.start self.msecs = self.secs * 1000 # millisecs if self.verbose: print 'elapsed time: %f ms' % self.msecs为了使用它,你需要用Python的with关键字和Timer上下文管理器包装想要计时的代码块。它将会在你的代码块开始执行的时候启动计时器,在你的代码块结束的时候停止计时器。
这是一个使用上述代码片段的例子:
from timer import Timerfrom redis import Redisrdb = Redis()with Timer() as t: rdb.lpush("foo", "bar")print "=> elasped lpush: %s s" % t.secswith Timer as t: rdb.lpop("foo")print "=> elasped lpop: %s s" % t.secs我经常将这些计时器的输出记录到文件中,这样就可以观察我的程序的性能如何随着时间进化。
使用分析器逐行统计时间和执行频率
Robert Kern有一个称作line_profiler的不错的项目,我经常使用它查看我的脚步中每行代码多快多频繁的被执行。
想要使用它,你需要通过pip安装该python包:
$ pip install line_profiler
一旦安装完成,你将会使用一个称做“line_profiler”的新模组和一个“kernprof.py”可执行脚本。
想要使用该工具,首先修改你的源代码,在想要测量的函数上装饰@profile装饰器。不要担心,你不需要导入任何模组。kernprof.py脚本将会在执行的时候将它自动地注入到你的脚步的运行时。
primes.py
@profiledef primes(n): if n==2: return [2] elif n<2: return [] s=range(3,n+1,2) mroot = n ** 0.5 half=(n+1)/2-1 i=0 m=3 while m <= mroot: if s[i]: j=(m*m-3)/2 s[j]=0 while j<half: s[j]=0 j+=m i=i+1 m=2*i+3 return [2]+[x for x in s if x]primes(100)一旦你已经设置好了@profile装饰器,使用kernprof.py执行你的脚步。$ kernprof.py -l -v fib.py-l选项通知kernprof注入@profile装饰器到你的脚步的内建函数,-v选项通知kernprof在脚本执行完毕的时候显示计时信息。上述脚本的输出看起来像这样:
Wrote profile results to primes.py.lprofTimer unit: 1e-06 sFile: primes.pyFunction: primes at line 2Total time: 0.00019 sLine # Hits Time Per Hit % Time Line Contents============================================================== 2 @profile 3 def primes(n): 4 1 2 2.0 1.1 if n==2: 5 return [2] 6 1 1 1.0 0.5 elif n<2: 7 return [] 8 1 4 4.0 2.1 s=range(3,n+1,2) 9 1 10 10.0 5.3 mroot = n ** 0.5 10 1 2 2.0 1.1 half=(n+1)/2-1 11 1 1 1.0 0.5 i=0 12 1 1 1.0 0.5 m=3 13 5 7 1.4 3.7 while m <= mroot: 14 4 4 1.0 2.1 if s[i]: 15 3 4 1.3 2.1 j=(m*m-3)/2 16 3 4 1.3 2.1 s[j]=0 17 31 31 1.0 16.3 while j<half: 18 28 28 1.0 14.7 s[j]=0 19 28 29 1.0 15.3 j+=m 20 4 4 1.0 2.1 i=i+1 21 4 4 1.0 2.1 m=2*i+3 22 50 54 1.1 28.4 return [2]+[x for x in s if x]寻找具有高Hits值或高Time值的行。这些就是可以通过优化带来最大改善的地方。
程序使用了多少内存?
现在我们对计时有了较好的理解,那么让我们继续弄清楚程序使用了多少内存。我们很幸运,Fabian Pedregosa模仿Robert Kern的line_profiler实现了一个不错的内存分析器。
首先使用pip安装:
$ pip install -U memory_profiler$ pip install psutil(这里建议安装psutil包,因为它可以大大改善memory_profiler的性能)。
就像line_profiler,memory_profiler也需要在感兴趣的函数上面装饰@profile装饰器:
@profiledef primes(n): ... ...想要观察你的函数使用了多少内存,像下面这样执行:$ python -m memory_profiler primes.py一旦程序退出,你将会看到看起来像这样的输出:
Filename: primes.pyLine # Mem usage Increment Line Contents============================================== 2 @profile 3 7.9219 MB 0.0000 MB def primes(n): 4 7.9219 MB 0.0000 MB if n==2: 5 return [2] 6 7.9219 MB 0.0000 MB elif n<2: 7 return [] 8 7.9219 MB 0.0000 MB s=range(3,n+1,2) 9 7.9258 MB 0.0039 MB mroot = n ** 0.5 10 7.9258 MB 0.0000 MB half=(n+1)/2-1 11 7.9258 MB 0.0000 MB i=0 12 7.9258 MB 0.0000 MB m=3 13 7.9297 MB 0.0039 MB while m <= mroot: 14 7.9297 MB 0.0000 MB if s[i]: 15 7.9297 MB 0.0000 MB j=(m*m-3)/2 16 7.9258 MB -0.0039 MB s[j]=0 17 7.9297 MB 0.0039 MB while j<half: 18 7.9297 MB 0.0000 MB s[j]=0 19 7.9297 MB 0.0000 MB j+=m 20 7.9297 MB 0.0000 MB i=i+1 21 7.9297 MB 0.0000 MB m=2*i+3 22 7.9297 MB 0.0000 MB return [2]+[x for x in s if x]line_profiler和memory_profiler的IPython快捷方式
memory_profiler和line_profiler有一个鲜为人知的小窍门,两者都有在IPython中的快捷命令。你需要做的就是在IPython会话中输入以下内容:
%load_ext memory_profiler%load_ext line_profiler
在这样做的时候你需要访问魔法命令%lprun和%mprun,它们的行为类似于他们的命令行形式。主要区别是你不需要使用@profiledecorator来修饰你要分析的函数。只需要在IPython会话中像先前一样直接运行分析:
In [1]: from primes import primesIn [2]: %mprun -f primes primes(1000)In [3]: %lprun -f primes primes(1000)这样可以节省你很多时间和精力,因为你的源代码不需要为使用这些分析命令而进行修改。
内存泄漏在哪里?
cPython解释器使用引用计数做为记录内存使用的主要方法。这意味着每个对象包含一个计数器,当某处对该对象的引用被存储时计数器增加,当引用被删除时计数器递减。当计数器到达零时,cPython解释器就知道该对象不再被使用,所以删除对象,释放占用的内存。
如果程序中不再被使用的对象的引用一直被占有,那么就经常发生内存泄漏。
查找这种“内存泄漏”最快的方式是使用Marius Gedminas编写的objgraph,这是一个极好的工具。该工具允许你查看内存中对象的数量,定位含有该对象的引用的所有代码的位置。
一开始,首先安装objgraph:
pip install objgraph一旦你已经安装了这个工具,在你的代码中插入一行声明调用调试器:
import pdb; pdb.set_trace()最普遍的对象是哪些?
在运行的时候,你可以通过执行下述指令查看程序中前20个最普遍的对象:
(pdb) import objgraph(pdb) objgraph.show_most_common_types()MyBigFatObject 20000tuple 16938function 4310dict 2790wrapper_descriptor 1181builtin_function_or_method 934weakref 764list 634method_descriptor 507getset_descriptor 451type 439哪些对象已经被添加或删除?
我们也可以查看两个时间点之间那些对象已经被添加或删除:
(pdb) import objgraph(pdb) objgraph.show_growth()...(pdb) objgraph.show_growth() # this only shows objects that has been added or deleted since last show_growth() calltraceback 4 +2KeyboardInterrupt 1 +1frame 24 +1list 667 +1tuple 16969 +1谁引用着泄漏的对象?
继续,你还可以查看哪里包含给定对象的引用。让我们以下述简单的程序做为一个例子:
x = [1]y = [x, [x], {"a":x}]import pdb; pdb.set_trace()想要看看哪里包含变量x的引用,执行objgraph.show_backref()函数:(pdb) import objgraph(pdb) objgraph.show_backref([x], filename="/tmp/backrefs.png")该命令的输出应该是一副PNG图像,保存在/tmp/backrefs.png,它看起来是像这样:
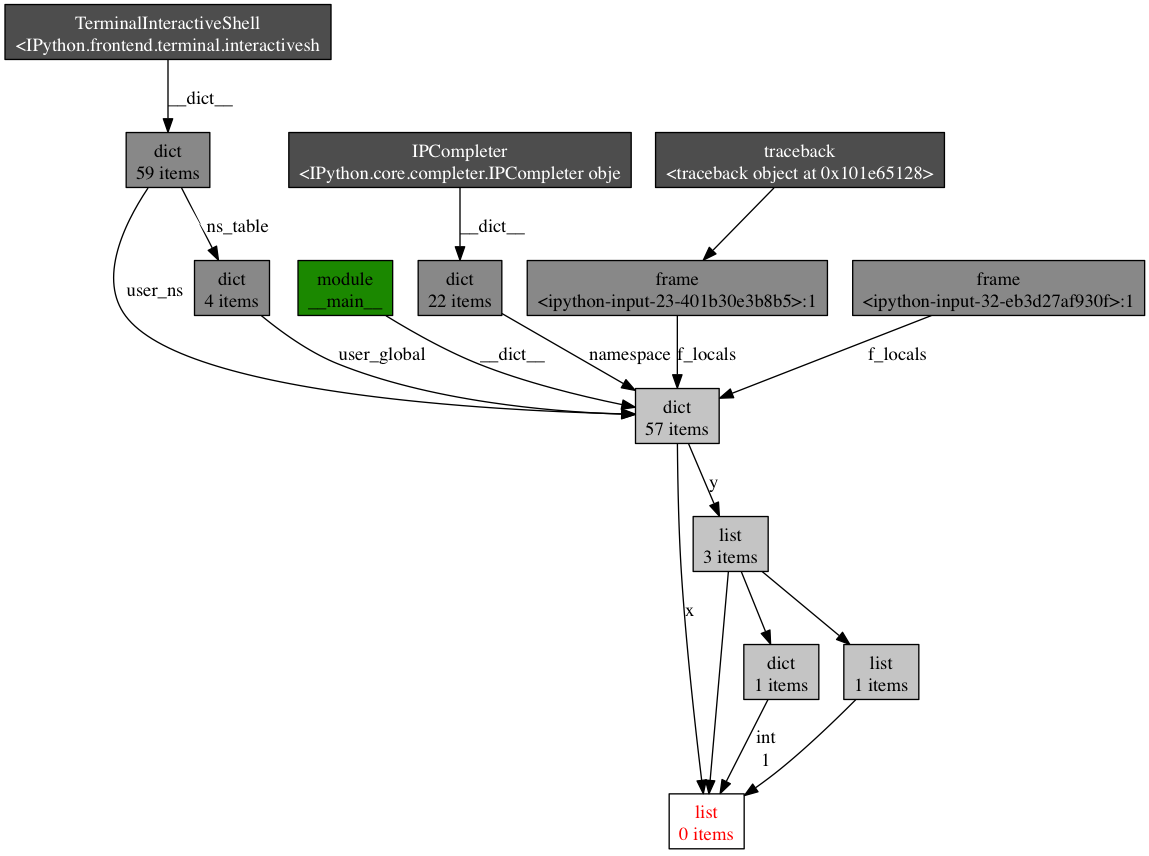
最下面有红字的盒子是我们感兴趣的对象。我们可以看到,它被符号x引用了一次,被列表y引用了三次。如果是x引起了一个内存泄漏,我们可以使用这个方法,通过跟踪它的所有引用,来检查为什么它没有自动的被释放。
回顾一下,objgraph 使我们可以:
- 显示占据python程序内存的头N个对象
- 显示一段时间以后哪些对象被删除活增加了
- 在我们的脚本中显示某个给定对象的所有引用
努力与精度
在本帖中,我给你显示了怎样用几个工具来分析python程序的性能。通过这些工具与技术的武装,你可以获得所有需要的信息,来跟踪一个python程序中大多数的内存泄漏,以及识别出其速度瓶颈。
对许多其他观点来说,运行一次性能分析就意味着在努力目标与事实精度之间做出平衡。如果感到困惑,那么就实现能适应你目前需求的最简单的解决方案。
参考
- stack overflow - time explained(堆栈溢出 - 时间解释)
- line_profiler(线性分析器)
- memory_profiler(内存分析器)
- objgraph(对象图)
go中提供了pprof包来做代码的性能监控,在两个地方有包:
- net/http/pprof
- runtime/pprof
其实net/http/pprof中只是使用runtime/pprof包来进行封装了一下,并在http端口上暴露出来。
使用 net/http/pprof 做WEB服务器的性能监控
如果你的go程序是用http包启动的web服务器,想要查看自己的web服务器的状态。这个时候就可以选择net/http/pprof。
import _ "net/http/pprof"然后就可以在浏览器中使用http://localhost:port/debug/pprof/ 直接看到当前web服务的状态,包括CPU占用情况和内存使用情况等。 当然,非WEB的也可以用下面方式启动WEB。 在 main 方法中增加
func main() {go func() {http.ListenAndServe("localhost:6060", nil)}()下图就是访问该网址的一次截图: 
CPU消耗分析
使用 runtime/pprof 做应用程序性能监控
关键代码:
import "runtime/pprof"func main() {
f, err := os.OpenFile("./tmp/cpu.prof", os.O_RDWR|os.O_CREATE, 0644)
if err != nil {
log.Fatal(err)
}
defer f.Close()
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()// 注意,有时候 defer f.Close(), defer pprof.StopCPUProfile() 会执行不到,这时候我们就会看到 prof 文件是空的, 我们需要在自己代码退出的地方,增加上下面两行,确保写文件内容了。pprof.StopCPUProfile()f.Close()}对产生的文件进行分析:
我们可以使用 go tool pprof (应用程序) (应用程序的prof文件) 方式来对这个 prof 文件进行分析。
$ go tool pprof HuaRongDao ./tmp/cpu.prof
Entering interactive mode (type "help" for commands)
(pprof)
一些常用 pprof 的命令:
top
在默认情况下,top命令会输出以本地取样计数为顺序的列表。我们可以把这个列表叫做本地取样计数排名列表。
(pprof) top
2700ms of 3200ms total (84.38%)
Dropped 58 nodes (cum <= 16ms)
Showing top 10 nodes out of 111 (cum >= 80ms)
flat flat% sum% cum cum%
670ms 20.94% 20.94% 670ms 20.94% runtime.mach_semaphore_signal
580ms 18.12% 39.06% 590ms 18.44% runtime.cgocall
370ms 11.56% 50.62% 370ms 11.56% runtime.mach_semaphore_wait
360ms 11.25% 61.88% 360ms 11.25% runtime.memmove
210ms 6.56% 68.44% 580ms 18.12% golang.org/x/mobile/gl.(*context).DoWork
120ms 3.75% 72.19% 120ms 3.75% runtime.usleep
110ms 3.44% 75.62% 110ms 3.44% image/png.filterPaeth
100ms 3.12% 78.75% 160ms 5.00% compress/flate.(*decompressor).huffSym
100ms 3.12% 81.88% 100ms 3.12% image/draw.drawNRGBASrc
80ms 2.50% 84.38% 80ms 2.50% runtime.memclr
(pprof)
参考: https://github.com/hyper-carrot/go_command_tutorial/blob/master/0.12.md
默认情况下top命令会列出前10项内容。但是如果在top命令后面紧跟一个数字,那么其列出的项数就会与这个数字相同。
web
与gv命令类似,web命令也会用图形化的方式来显示概要文件。但不同的是,web命令是在一个Web浏览器中显示它。如果你的Web浏览器已经启动,那么它的显示速度会非常快。如果想改变所使用的Web浏览器,可以在Linux下设置符号链接/etc/alternatives/gnome-www-browser或/etc/alternatives/x-www-browser,或在OS X下改变SVG文件的关联Finder。
mac 下 修改默认打开方式: 右键一个想处理的文件,按alt 键(lion)出现always open with,然后打开,整个过程中, 先右键,然后一直按 alt, 一直到打开为止。

参考资料:
go tool pprof
https://github.com/hyper-carrot/go_command_tutorial/blob/master/0.12.md
Go的pprof使用
http://www.cnblogs.com/yjf512/archive/2012/12/27/2835331.html
Profiling Go Programs
https://blog.golang.org/profiling-go-programs
内存泄漏或消耗分析
关键代码
fm, err := os.OpenFile("./tmp/mem.out", os.O_RDWR|os.O_CREATE, 0644)
if err != nil {
log.Fatal(err)
}
pprof.WriteHeapProfile(fm)
fm.Close()
在我们需要生成当时的内存情况时,只需要执行上面代码即可。
触发的条件可以通过 http 的一个接口,或者退出时,或者接收到某个特殊信号,这些逻辑就需要自己实现了。
分析方法,跟之上CPU的分析方法一致。

参考资料:
[golang]内存不断增长bytes.makeSlice
http://studygolang.com/articles/2763
- Python && Golang性能分析指南
- Python性能分析指南
- Python性能分析指南
- Python性能分析指南
- Python性能分析指南
- Python性能分析指南
- Python性能分析指南
- Python 性能分析入门指南
- Python 性能分析入门指南
- Python程序的性能分析指南
- Python程序的性能分析指南
- Python程序的性能分析指南
- Python程序的性能分析指南
- Python程序的性能分析指南
- Python程序的性能分析指南
- Python程序的性能分析指南
- [golang]pprof性能分析工具
- Python性能优化指南
- Codeforces Round #406 (Div. 1) C. Till I Collapse(可持久化线段树)
- 编写一个学生信息系统的菜单程序,在菜单其中的增加记录的菜单选项中实现对一条学生记录的录入,记录中需要有学号、姓名、性别,年龄籍贯等字段,要求用最合适的控件录入。
- 蓝桥杯 煤球数目
- linux的一些基础命令
- PHP实现前端页面跳转三种实现方法
- Python && Golang性能分析指南
- Caused by: java.net.BindException: Address already in use: bind
- 前腾讯高级产品经理:新产品如何从0快速做到千万用户?
- PHP static 关键字和 self 关键字实例化的区别
- Spark 架构-初识
- 系统编程
- 【matlab】GUI 编译程序,打包成独立软件
- 士兵队列操作模拟
- 方法参数 java核心技术程序清单:4-4


