Python性能分析指南
来源:互联网 发布:linux下运行jar包 编辑:程序博客网 时间:2024/05/29 12:55
Python性能分析指南
英文原文:A guide to analyzing Python performance
尽管并非每个你写的Python程序都需要严格的性能分析,但了解一下Python的生态系统中很多优秀的在你需要做性能分析的时候可以使用的工具仍然是一件值得去做的事。
分析一个程序的性能,最终都归结为回答4个基本的问题:
- 程序运行速度有多快?
- 运行速度瓶颈在哪儿?
- 程序使用了多少内存?
- 内存泄露发生在哪里?
使用time工具粗糙定时
首先,我们可以使用快速然而粗糙的工具:古老的unix工具time,来为我们的代码检测运行时间。
1$ time python yourprogram.py2 3real 0m1.028s4user 0m0.001s5sys 0m0.003s- real - 表示实际的程序运行时间
- user - 表示程序在用户态的cpu总时间
- sys - 表示在内核态的cpu总时间
通过sys和user时间的求和,你可以直观的得到系统上没有其他程序运行时你的程序运行所需要的CPU周期。
若sys和user时间之和远远少于real时间,那么你可以猜测你的程序的主要性能问题很可能与IO等待相关。
使用计时上下文管理器进行细粒度计时
我们的下一个技术涉及访问细粒度计时信息的直接代码指令。这是一小段代码,我发现使用专门的计时测量是非常重要的:
timer.py
01import time02 03class Timer(object):04 def__init__(self, verbose=False):05 self.verbose= verbose06 07 def__enter__(self):08 self.start= time.time()09 returnself10 11 def__exit__(self,*args):12 self.end= time.time()13 self.secs= self.end- self.start14 self.msecs= self.secs* 1000 # millisecs15 ifself.verbose:16 print'elapsed time: %f ms' % self.msecs为了使用它,你需要用Python的with关键字和Timer上下文管理器包装想要计时的代码块。它将会在你的代码块开始执行的时候启动计时器,在你的代码块结束的时候停止计时器。
这是一个使用上述代码片段的例子:
01from timer import Timer02from redis import Redis03rdb =Redis()04 05with Timer() as t:06 rdb.lpush("foo","bar")07print "=> elasped lpush: %s s" % t.secs08 09with Timer as t:10 rdb.lpop("foo")11print "=> elasped lpop: %s s" % t.secs我经常将这些计时器的输出记录到文件中,这样就可以观察我的程序的性能如何随着时间进化。
使用分析器逐行统计时间和执行频率
Robert Kern有一个称作line_profiler的不错的项目,我经常使用它查看我的脚步中每行代码多快多频繁的被执行。
想要使用它,你需要通过pip安装该python包:
1$ pip install line_profiler一旦安装完成,你将会使用一个称做“line_profiler”的新模组和一个“kernprof.py”可执行脚本。
想要使用该工具,首先修改你的源代码,在想要测量的函数上装饰@profile装饰器。不要担心,你不需要导入任何模组。kernprof.py脚本将会在执行的时候将它自动地注入到你的脚步的运行时。
primes.py
01@profile02def primes(n): 03 ifn==2:04 return[2]05 elifn<2:06 return[]07 s=range(3,n+1,2)08 mroot= n **0.509 half=(n+1)/2-110 i=011 m=312 whilem <= mroot:13 ifs[i]:14 j=(m*m-3)/215 s[j]=016 whilej<half:17 s[j]=018 j+=m19 i=i+120 m=2*i+321 return[2]+[xfor x ins if x]22primes(100)1$ kernprof.py -l -v fib.py01Wrote profile results to primes.py.lprof02Timer unit: 1e-06 s03 04File: primes.py05Function: primes at line 206Total time: 0.00019 s07 08Line # Hits Time Per Hit % Time Line Contents09==============================================================10 2 @profile11 3 def primes(n):12 4 1 2 2.0 1.1 if n==2:13 5 return [2]14 6 1 1 1.0 0.5 elif n<2:15 7 return []16 8 1 4 4.0 2.1 s=range(3,n+1,2)17 9 1 10 10.0 5.3 mroot = n ** 0.518 10 1 2 2.0 1.1 half=(n+1)/2-119 11 1 1 1.0 0.5 i=020 12 1 1 1.0 0.5 m=321 13 5 7 1.4 3.7 while m <= mroot:22 14 4 4 1.0 2.1 if s[i]:23 15 3 4 1.3 2.1 j=(m*m-3)/224 16 3 4 1.3 2.1 s[j]=025 17 31 31 1.0 16.3 while j<half:26 18 28 28 1.0 14.7 s[j]=027 19 28 29 1.0 15.3 j+=m28 20 4 4 1.0 2.1 i=i+129 21 4 4 1.0 2.1 m=2*i+330 22 50 54 1.1 28.4 return [2]+[x forx in s if x]寻找具有高Hits值或高Time值的行。这些就是可以通过优化带来最大改善的地方。
程序使用了多少内存?
现在我们对计时有了较好的理解,那么让我们继续弄清楚程序使用了多少内存。我们很幸运,Fabian Pedregosa模仿Robert Kern的line_profiler实现了一个不错的内存分析器。
首先使用pip安装:
1$ pip install-U memory_profiler2$ pip installpsutil(这里建议安装psutil包,因为它可以大大改善memory_profiler的性能)。
就像line_profiler,memory_profiler也需要在感兴趣的函数上面装饰@profile装饰器:
1@profile2def primes(n): 3 ...4 ...1$ python -m memory_profiler primes.py01Filename: primes.py02 03Line # Mem usage Increment Line Contents04==============================================05 2 @profile06 3 7.9219 MB 0.0000MB def primes(n): 07 4 7.9219 MB 0.0000MB if n==2:08 5 return [2]09 6 7.9219 MB 0.0000MB elif n<2:10 7 return []11 8 7.9219 MB 0.0000MB s=range(3,n+1,2)12 9 7.9258 MB 0.0039MB mroot = n ** 0.513 10 7.9258 MB 0.0000MB half=(n+1)/2-114 11 7.9258 MB 0.0000MB i=015 12 7.9258 MB 0.0000MB m=316 13 7.9297 MB 0.0039MB while m <= mroot:17 14 7.9297 MB 0.0000MB if s[i]:18 15 7.9297 MB 0.0000MB j=(m*m-3)/219 16 7.9258 MB -0.0039MB s[j]=020 17 7.9297 MB 0.0039MB while j<half:21 18 7.9297 MB 0.0000MB s[j]=022 19 7.9297 MB 0.0000MB j+=m23 20 7.9297 MB 0.0000MB i=i+124 21 7.9297 MB 0.0000MB m=2*i+325 22 7.9297 MB 0.0000MB return [2]+[xfor x ins if x]line_profiler和memory_profiler的IPython快捷方式
memory_profiler和line_profiler有一个鲜为人知的小窍门,两者都有在IPython中的快捷命令。你需要做的就是在IPython会话中输入以下内容:
1%load_ext memory_profiler2%load_ext line_profiler在这样做的时候你需要访问魔法命令%lprun和%mprun,它们的行为类似于他们的命令行形式。主要区别是你不需要使用@profiledecorator来修饰你要分析的函数。只需要在IPython会话中像先前一样直接运行分析:
1In [1]: from primesimport primes2In [2]: %mprun -f primes primes(1000)3In [3]: %lprun -f primes primes(1000)这样可以节省你很多时间和精力,因为你的源代码不需要为使用这些分析命令而进行修改。
内存泄漏在哪里?
cPython解释器使用引用计数做为记录内存使用的主要方法。这意味着每个对象包含一个计数器,当某处对该对象的引用被存储时计数器增加,当引用被删除时计数器递减。当计数器到达零时,cPython解释器就知道该对象不再被使用,所以删除对象,释放占用的内存。
如果程序中不再被使用的对象的引用一直被占有,那么就经常发生内存泄漏。
查找这种“内存泄漏”最快的方式是使用Marius Gedminas编写的objgraph,这是一个极好的工具。该工具允许你查看内存中对象的数量,定位含有该对象的引用的所有代码的位置。
一开始,首先安装objgraph:
1pip install objgraph1import pdb; pdb.set_trace()最普遍的对象是哪些?
在运行的时候,你可以通过执行下述指令查看程序中前20个最普遍的对象:
01(pdb) importobjgraph02(pdb) objgraph.show_most_common_types()03 04MyBigFatObject 2000005tuple 1693806function 431007dict 279008wrapper_descriptor 118109builtin_function_or_method93410weakref 76411list 63412method_descriptor 50713getset_descriptor 45114type 439哪些对象已经被添加或删除?
我们也可以查看两个时间点之间那些对象已经被添加或删除:
01(pdb) importobjgraph02(pdb) objgraph.show_growth()03.04.05.06(pdb) objgraph.show_growth() # this only shows objects that has been added or deleted since last show_growth() call07 08traceback 4 +209KeyboardInterrupt 1 +110frame 24 +111list 667 +112tuple 16969 +1谁引用着泄漏的对象?
继续,你还可以查看哪里包含给定对象的引用。让我们以下述简单的程序做为一个例子:
1x =[1]2y =[x, [x], {"a":x}]3import pdb; pdb.set_trace()1(pdb) importobjgraph2(pdb) objgraph.show_backref([x], filename="/tmp/backrefs.png")该命令的输出应该是一副PNG图像,保存在/tmp/backrefs.png,它看起来是像这样:
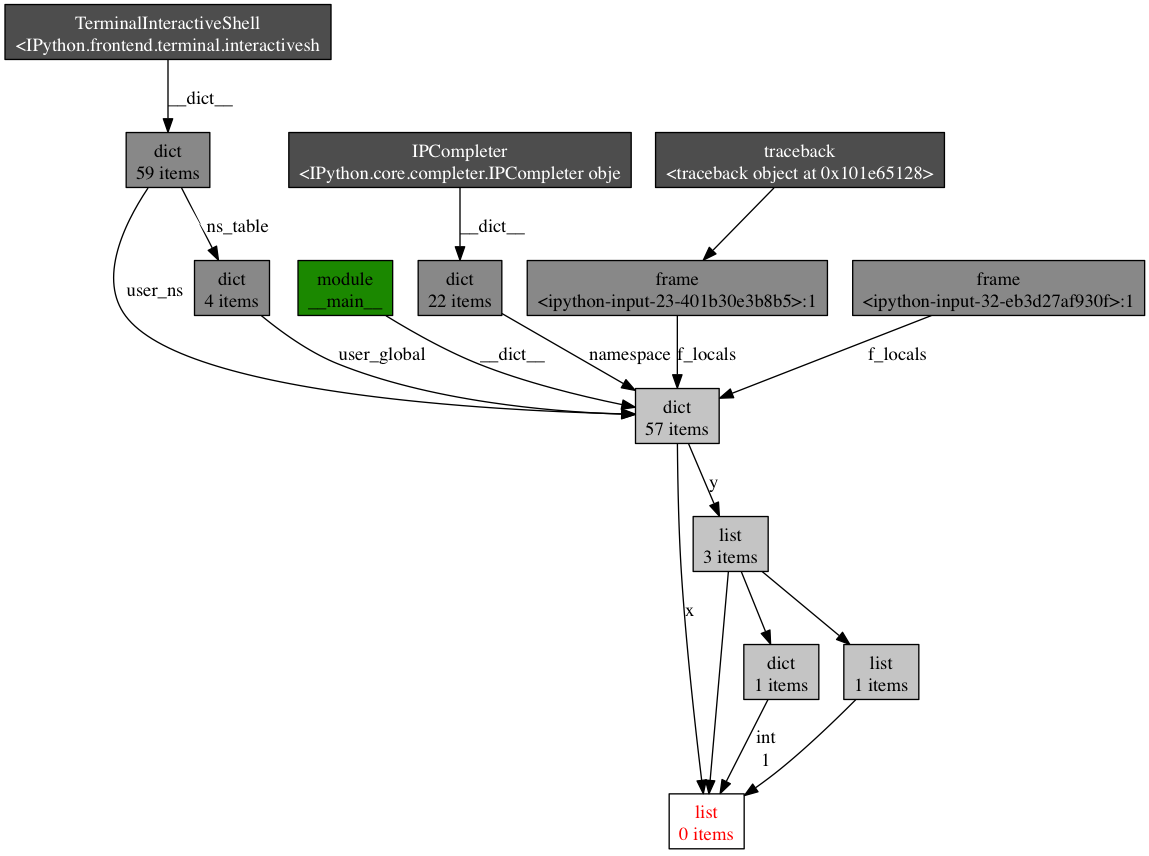
最下面有红字的盒子是我们感兴趣的对象。我们可以看到,它被符号x引用了一次,被列表y引用了三次。如果是x引起了一个内存泄漏,我们可以使用这个方法,通过跟踪它的所有引用,来检查为什么它没有自动的被释放。
回顾一下,objgraph 使我们可以:
- 显示占据python程序内存的头N个对象
- 显示一段时间以后哪些对象被删除活增加了
- 在我们的脚本中显示某个给定对象的所有引用
努力与精度
在本帖中,我给你显示了怎样用几个工具来分析python程序的性能。通过这些工具与技术的武装,你可以获得所有需要的信息,来跟踪一个python程序中大多数的内存泄漏,以及识别出其速度瓶颈。
对许多其他观点来说,运行一次性能分析就意味着在努力目标与事实精度之间做出平衡。如果感到困惑,那么就实现能适应你目前需求的最简单的解决方案。
参考
- stack overflow - time explained(堆栈溢出 - 时间解释)
- line_profiler(线性分析器)
- memory_profiler(内存分析器)
- objgraph(对象图)
- Python性能分析指南
- Python性能分析指南
- Python性能分析指南
- Python性能分析指南
- Python性能分析指南
- Python性能分析指南
- Python 性能分析入门指南
- Python 性能分析入门指南
- Python && Golang性能分析指南
- Python程序的性能分析指南
- Python程序的性能分析指南
- Python程序的性能分析指南
- Python程序的性能分析指南
- Python程序的性能分析指南
- Python程序的性能分析指南
- Python程序的性能分析指南
- Python性能优化指南
- python性能优化指南
- 《Effective C++ 改善程序与设计的55个具体做法》——第三章笔记
- 语音的Mfcc特征学习与理解
- java类的继承
- POJ 1517 u Calculate e
- hdoj 2064 汉诺塔III
- Python性能分析指南
- mysql索引
- 电池充电时扩散页面动画效果相关
- MySQL Windows ZIP 免安装版的设置和启动
- swap
- google 著名技术
- 如何用笔记本建立虚拟wifi(新手教程)
- hdu 1247 字典树模版
- 国外程序员整理的 C++ 资源大全


