自己排序Excel的数据
来源:互联网 发布:flame软件 编辑:程序博客网 时间:2024/06/06 00:06
xlrd 和xlwtcmd中pip 安装,pip install xlrd 和pip install xlwt2、了解需求,Python操作Excel,先要将数据读出来放到列表中,然后对列表中的第8列排序,再读进另外一个Excel中去#!/usr/bin/env python# coding=utf-8# 需求,取第1156行以下的数据,然后取每行前9列的数据,并对第9列数据从小到大排序import xlrdimport xlwta=[]x=[]data = xlrd.open_workbook(r'E:\shuju\test.xls') # 打开xls文件table = data.sheets()[0] # 打开第一张表nrows = table.nrows # 获取表的行数workbook = xlwt.Workbook() # 注意Workbook的开头W要大写sheet1 = workbook.add_sheet('sheet1', cell_overwrite_ok=True)for i in range(nrows): # 循环逐行打印 if i > 3 and i < 1156: # 跳过第3行和前1156行 continue elif i <=3 : # 读前3行 y= table.row_values(i)[:9] # 取前9列 x.append(y) else: b=table.row_values(i)[:9] # 取前9列 a.append(b)3、列表排序a.sort(key=lambda x:x[8])4、对第8列的数据进行分类到第十列中的属性for i in range(len(x)): for j in range(len(x[i])): sheet1.write(i, j, x[i][j])for i in range(len(a)): m=a[i][7] if m>=90: a[i].append(u"5优秀") elif m>=80: a[i].append(u"4良好") elif m >= 70: a[i].append(u"3中等") elif m>=60: a[i].append(u"2及格") else: a[i].append(u"1不及格") for j in range(len(a[i])): sheet1.write(len(x)+i-1, j, a[i][j])workbook.save(r'E:\shuju\test1.xls')print '创建excel文件完成!'其他的Excel操作的知识点附上:pypi.python.org/pypi。下面分别记录python读和写excel.
python读excel——xlrd
这个过程有几个比较麻烦的问题,比如读取日期、读合并单元格内容。下面先看看基本的操作:
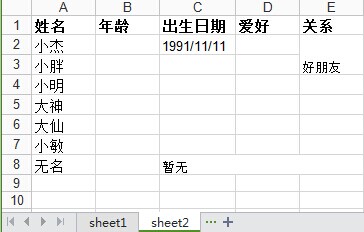
首先读一个excel文件,有两个sheet,测试用第二个sheet,sheet2内容如下:
python 对 excel基本的操作如下:
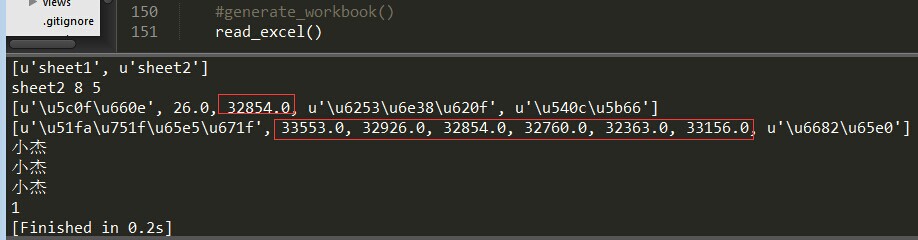
运行结果如下:
那么问题来了,上面的运行结果中红框框中的字段明明是出生日期,可显示的确实浮点数。好的,来解决第一个问题:
1、python读取excel中单元格内容为日期的方式
python读取excel中单元格的内容返回的有5种类型,即上面例子中的ctype:
即date的ctype=3,这时需要使用xlrd的xldate_as_tuple来处理为date格式,先判断表格的ctype=3时xldate才能开始操作。现在命令行看下:
即可以做下简单处理,判断ctype是否等于3,如果等于3,则用时间格式处理:
那么问题又来了,上面 sheet2.cell(2,4).ctype 返回的值是0,说明这个单元格的值是空值,明明是合并的单元格内容"好朋友",这个是我觉得这个包功能不完善的地方,如果是合并的单元格那么应该合并的单元格的内容一样,但是它只是合并的第一个单元格的有值,其它的为空。
2、读取合并单元格的内容
这个是真没技巧,只能获取合并单元格的第一个cell的行列索引,才能读到值,读错了就是空值。
即合并行单元格读取行的第一个索引,合并列单元格读取列的第一个索引,如上述,读取行合并单元格"好朋友"和读取列合并单元格"暂无"只能如下方式:
疑问又来了,合并单元格可能出现空值,但是表格本身的普通单元格也可能是空值,要怎么获取单元格所谓的"第一个行或列的索引"呢?
这就要先知道哪些是单元格是被合并的!
3、获取合并的单元格
读取文件的时候需要将formatting_info参数设置为True,默认是False,所以上面获取合并的单元格数组为空,
merged_cells返回的这四个参数的含义是:(row,row_range,col,col_range),其中[row,row_range)包括row,不包括row_range,col也是一样,即(1, 3, 4, 5)的含义是:第1到2行(不包括3)合并,(7, 8, 2, 5)的含义是:第2到4列合并。
利用这个,可以分别获取合并的三个单元格的内容:
发现规律了没?是的,获取merge_cells返回的row和col低位的索引即可! 于是可以这样一劳永逸:
python写excel——xlwt
写excel的难点可能不在构造一个workbook的本身,而是填充的数据,不过这不在范围内。在写excel的操作中也有棘手的问题,比如写入合并的单元格就是比较麻烦的,另外写入还有不同的样式。这些要看源码才能研究的透。
我"构思"了如下面的sheet1,即要用xlwt实现的东西:
基本上看起来还算复杂,而且看起来"很正规",完全是个人杜撰。
代码如下:
需要稍作解释的就是write_merge方法:
write_merge(x, x + m, y, w + n, string, sytle)x表示行,y表示列,m表示跨行个数,n表示跨列个数,string表示要写入的单元格内容,style表示单元格样式。其中,x,y,w,h,都是以0开始计算的。
这个和xlrd中的读合并单元格的不太一样。
如上述:sheet1.write_merge(21,21,0,1,u'合计',set_style('Times New Roman',220,True))
即在22行合并第1,2列,合并后的单元格内容为"合计",并设置了style。
如果需要创建多个sheet,则只要f.add_sheet即可。
如在上述write_excel函数里f.save('demo1.xlsx') 这句之前再创建一个sheet2,效果如下:
代码也是真真的easy的了:
以下是sort的具体实例。
实例1:复制代码代码如下:>>>L = [2,3,1,4]>>>L.sort()>>>L>>>[1,2,3,4]
实例2:复制代码代码如下:>>>L = [2,3,1,4]>>>L.sort(reverse=True)>>>L>>>[4,3,2,1]
实例3:复制代码代码如下:>>>L = [('b',2),('a',1),('c',3),('d',4)]>>>L.sort(cmp=lambda x,y:cmp(x[1],y[1]))>>>L>>>[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
实例4:复制代码代码如下:>>>L = [('b',2),('a',1),('c',3),('d',4)]>>>L.sort(key=lambda x:x[1])>>>L>>>[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
实例5:复制代码代码如下:>>>L = [('b',2),('a',1),('c',3),('d',4)]>>>import operator>>>L.sort(key=operator.itemgetter(1))>>>L>>>[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
实例6:(DSU方法:Decorate-Sort-Undercorate)复制代码代码如下:>>>L = [('b',2),('a',1),('c',3),('d',4)]>>>A = [(x[1],i,x) for i,x in enumerate(L)] #i can confirm the stable sort>>>A.sort()>>>L = [s[2] for s in A]>>>L>>>[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
以上给出了6中对List排序的方法,其中实例3.4.5.6能起到对以List item中的某一项
为比较关键字进行排序.
效率比较:复制代码代码如下:cmp < DSU < key
通过实验比较,方法3比方法6要慢,方法6比方法4要慢,方法4和方法5基本相当
多关键字比较排序:
实例7:复制代码代码如下:>>>L = [('d',2),('a',4),('b',3),('c',2)]>>> L.sort(key=lambda x:x[1])>>> L>>>[('d', 2), ('c', 2), ('b', 3), ('a', 4)]
我们看到,此时排序过的L是仅仅按照第二个关键字来排的,如果我们想用第二个关键字
排过序后再用第一个关键字进行排序呢?有两种方法
实例8:复制代码代码如下:>>> L = [('d',2),('a',4),('b',3),('c',2)]>>> L.sort(key=lambda x:(x[1],x[0]))>>> L>>>[('c', 2), ('d', 2), ('b', 3), ('a', 4)]
实例9:复制代码代码如下:>>> L = [('d',2),('a',4),('b',3),('c',2)]>>> L.sort(key=operator.itemgetter(1,0))>>> L>>>[('c', 2), ('d', 2), ('b', 3), ('a', 4)]
为什么实例8能够工作呢?原因在于tuple是的比较从左到右之一比较的,比较完第一个,如果
相等,比较第二个方法一:
小罗问我怎么从excel中读取数据,然后我百了一番,做下记录
excel数据图(小罗说数据要给客户保密,我随手写了几行数据):
python读取excel文件代码:
excel的写操作等后面用到的时候在做记录
方法二:
使用xlrd读取文件,使用xlwt生成Excel文件(可以控制Excel中单元格的格式)。但是用xlrd读取excel是不能对其进行操作的;而xlwt生成excel文件是不能在已有的excel文件基础上进行修改的,如需要修改文件就要使用xluntils模块。pyExcelerator模块与xlwt类似,也可以用来生成excel文件。
1. [代码]test_xlrd.py
2. [代码]test_xlwt.py
3. [代码]test_xlutils.py
4. [代码]test_pyExcelerator_read.py
5. [代码]test_pyExcelerator.py


- 自己排序Excel的数据
- Excel导入数据自己定义的
- Excel数据排序操作
- 打造自己的读取Excel数据的工具类
- 打造自己的读取Excel数据的工具类
- 自己写了一个获取Excel数据的方法
- 自己写的Excel
- Excel 技巧百例:数据透视表的排序
- 实现数据按照自己的需要进行排序
- 自己用到的excel导入
- 自己完成一个冒泡排序(bubble_sort),可以完成不同类型数据的排序
- 自己实现一个bubble_sort(冒泡排序),可以完成不同类型数据的排序
- 自己造轮子系列:web环境下解析上传的excel文件中的数据的开源库
- matlab对excel数据进行排序求和
- 读取excel 的数据
- 自己整理的数据
- 自己备份的数据
- 训练自己的数据
- nyoj ACM: 三个水杯(回溯算法 bfs )
- 蓝桥杯及其搜索算法总结
- 螺旋数字
- Python函数的几点需要注意的细节
- 移动距离
- 自己排序Excel的数据
- linux入门命令
- POJ 2184 Cow Exhibition(0-1背包,负化正)
- RocketMQ源码分析----Broker处理发送请求
- Fibonacci Again hdu1021
- 字符串的每个单词首字母大写
- 大数据IMF传奇行动绝密课程第89课:SparkStreaming On Kafka之kafka解析和安装实战
- 理解HTTP协议
- 利用sleep函数(Linux平台)结合结构体,编写一个模拟时钟


