论文引介 | Dual Learning for Machine Translation
来源:互联网 发布:上海和数软件 编辑:程序博客网 时间:2024/05/17 08:49
文章原名:Dual Learning for Machine Translation
作者:Yingce Xia1, Di He2,Tao Qin3, Liwei Wang2, Nenghai Yu1, Tie-Yan Liu3, Wei-Ying Ma3
单位:1University of Science and Technology of China, 2Peking University, 3Microsoft Research
译者:涂存超
链接:https://arxiv.org/pdf/1611.00179v1.pdf(可戳下方阅读原文)
1
导读
本文是NIPS2016的一篇十分受瞩目的工作。
机器翻译系统的训练,通常需要上百万的平行句对。然而,人工标注代价昂贵。为了克服训练数据的瓶颈,这篇论文提出了对偶学习机制,能够使得翻译系统自动的从无标注数据中进行学习。这个机制受如下观察的启发:任何的机器翻译任务都有一个对偶的任务,例如英法翻译对应着法英翻译。原任务的对偶任务能够形成一个闭环,即使没有人类标注者的参与,也能够生成有信息量的反馈信号,来训练翻译模型。在对偶学习机制中,我们利用一个agent代表原任务模型,利用另一个agent代表对偶任务,让他们通过强化学习过程来互相教学。基于这个过程生成的反馈信号,我们能够迭代的更新两个模型直到收敛。我们把该方法称作dual-NMT。实验结果表明,dual-NMT在英法互译任务上表现良好。值得注意的是,利用10%的对齐数据来热启动,利用单语数据进行学习,该模型能够达到与传统NMT模型可比的效果。
2
模型
这篇文章设计了一个包含两个agent的翻译游戏,包括前向翻译的步骤以及反向翻译的步骤。
假设存在语言A的语料DA以及语言B的语料DB。和分别代表由A到B和由B到A的神经翻译模型。此外,LMA()和LMB()代表两个训练好的语言模型。
在游戏开始时,给定一个DA中的句子s,假设smid是中间的翻译结果。那么这个中间的翻译步骤会有一个奖励r1=LMB(smid),来代表输出的句子在语言B中的流利程度。此外,利用由smid恢复s的对数似然值,来代表交流的奖励,也就是。这里,直接用一个简单的线性加和来表示最终的奖励,也就是。然后,利用policy gradientmethods对奖励进行最大化,来优化翻译模型。
通过翻译模型来采样smid,然后通过期望奖励E[r]来对参数求梯度,如下所示:

这里为了得到更合理的中间结果smid,采用了beam search方法,来求近似的梯度。在每次循环中,会从DA和DB中分别采样一个句子,然后分别根据这两个句子,更新翻译模型中的参数。
3
实验
本文与标准的神经机器翻译方法(NMT)以及生成伪对齐语料来辅助NMT训练的pseudo-NMT进行对比。采用的任务是英法和法英翻译。实验结果如下:
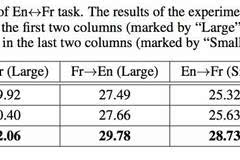

可以看到,dual-NMT在所有的实验设置上效果都好于其他基准方法。此外,在只有10%对齐语料的情况下,dual-NMT取得了与NMT可比的效果。这表明了dual-NMT算法的有效性。
4
贡献
本文提出了一种对偶学习的机制,利用大量无标注数据及少量标注数据,来训练高效的神经翻译模型。这个工作极大减少了对对齐双语语料的依赖,从一个新的视角展现了如何利用非对齐的数据来训练翻译模型。此外,这篇工作也体现了深度强化学习的威力。以往的强化学习大部分集中在视频或棋盘游戏上。在一些没有显著的奖励信息的更复杂的应用上还面临着挑战。这篇工作也证明了对偶学习为强化学习提供了一个有效的抽取奖励的途径。
- 论文引介 | Dual Learning for Machine Translation
- 论文阅读:Dual Learning for Machine Translation
- dual learning for machine translation
- #Paper Reading# Dual Learning for Machine Translation
- 论文笔记:Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
- DualGAN: Unsupervised Dual Learning for Image-to-Image Translation 阅读笔记
- 【论文阅读】Neural Machine Translation By Jointly Learning To Align and Translate
- 论文阅读:《Neural Machine Translation by Jointly Learning to Align and Translate》
- 论文《NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE》总结
- 论文阅读:Dual Supervised Learning
- Sampled Softmax 论文笔记:On Using Very Large Target Vocabulary for Neural Machine Translation
- Sampled Softmax 论文笔记:On Using Very Large Target Vocabulary for Neural Machine Translation
- 【nlp论文阅读】Adversal Neural Machine Translation
- Neural Machine Translation论文阅读笔记
- Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
- Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
- 翻译:Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
- BNN & Dual Learning论文下载地址
- 再探win32绘制正弦图像的最优雅方法:DPtoLP
- 细说JDK动态代理的实现原理
- 接口
- 前端页面和数据库同步进行增删改查
- 软件工程视频小结
- 论文引介 | Dual Learning for Machine Translation
- 关于云风在 Lua 中实现面向对象的源码分析
- Java泛型对方法重载的影响(二)
- Android内存优化(一)
- Android 最火的快速开发框架XUtils
- 在Linux下用C语言实现简单的进度条
- Allegro16.6和17.0和17.2中将板框导出DXF文件
- hdu1584
- poj1088 dp


