kafka源码分析之一server启动分析
来源:互联网 发布:电脑软件开发工具 编辑:程序博客网 时间:2024/05/18 05:50
0. 关键概念
关键概念
1. 分析kafka源码的目的
深入掌握kafka的内部原理
深入掌握scala运用
2. server的启动
如下所示(本来准备用时序图的,但感觉时序图没有思维图更能反映,故采用了思维图):
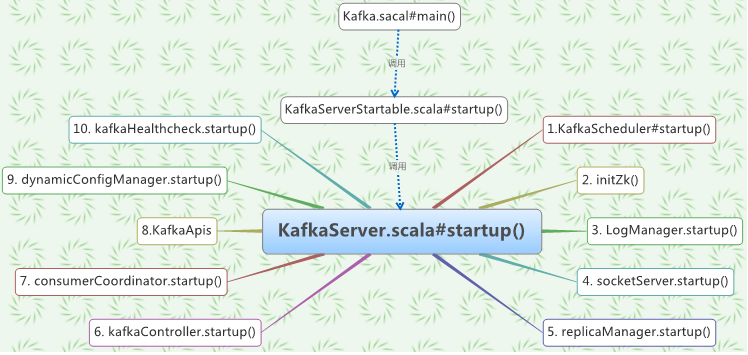
2.1 启动入口Kafka.scala
从上面的思维导图,可以看到Kafka的启动入口是Kafka.scala的main()函数:

def main(args: Array[String]): Unit = { try { val serverProps = getPropsFromArgs(args) val kafkaServerStartable = KafkaServerStartable.fromProps(serverProps) // attach shutdown handler to catch control-c Runtime.getRuntime().addShutdownHook(new Thread() { override def run() = { kafkaServerStartable.shutdown } }) kafkaServerStartable.startup kafkaServerStartable.awaitShutdown } catch { case e: Throwable => fatal(e) System.exit(1) } System.exit(0) }
上面代码主要包含:
从配置文件读取kafka服务器启动参数的getPropsFromArgs()方法;
创建KafkaServerStartable对象;
KafkaServerStartable对象在增加shutdown句柄函数;
启动KafkaServerStartable的starup()方法;
启动KafkaServerStartable的awaitShutdown()方法;
2.2 KafkaServer的包装类KafkaServerStartable
private val server = new KafkaServer(serverConfig) def startup() { try { server.startup() } catch { case e: Throwable => fatal("Fatal error during KafkaServerStartable startup. Prepare to shutdown", e) // KafkaServer already calls shutdown() internally, so this is purely for logging & the exit code System.exit(1) } }
2.3 具体启动类KafkaServer
KafkaServer启动的代码层次比较清晰,加上注释,看懂基本没有问题:
/** * Start up API for bringing up a single instance of the Kafka server. * Instantiates the LogManager, the SocketServer and the request handlers - KafkaRequestHandlers */ def startup() { try { info("starting") if(isShuttingDown.get) throw new IllegalStateException("Kafka server is still shutting down, cannot re-start!") if(startupComplete.get) return val canStartup = isStartingUp.compareAndSet(false, true) if (canStartup) { metrics = new Metrics(metricConfig, reporters, kafkaMetricsTime, true) brokerState.newState(Starting) /* start scheduler */ kafkaScheduler.startup() /* setup zookeeper */ zkUtils = initZk() /* start log manager */ logManager = createLogManager(zkUtils.zkClient, brokerState) logManager.startup() /* generate brokerId */ config.brokerId = getBrokerId this.logIdent = "[Kafka Server " + config.brokerId + "], " socketServer = new SocketServer(config, metrics, kafkaMetricsTime) socketServer.startup() /* start replica manager */ replicaManager = new ReplicaManager(config, metrics, time, kafkaMetricsTime, zkUtils, kafkaScheduler, logManager, isShuttingDown) replicaManager.startup() /* start kafka controller */ kafkaController = new KafkaController(config, zkUtils, brokerState, kafkaMetricsTime, metrics, threadNamePrefix) kafkaController.startup() /* start kafka coordinator */ consumerCoordinator = GroupCoordinator.create(config, zkUtils, replicaManager) consumerCoordinator.startup() /* Get the authorizer and initialize it if one is specified.*/ authorizer = Option(config.authorizerClassName).filter(_.nonEmpty).map { authorizerClassName => val authZ = CoreUtils.createObject[Authorizer](authorizerClassName) authZ.configure(config.originals()) authZ } /* start processing requests */ apis = new KafkaApis(socketServer.requestChannel, replicaManager, consumerCoordinator, kafkaController, zkUtils, config.brokerId, config, metadataCache, metrics, authorizer) requestHandlerPool = new KafkaRequestHandlerPool(config.brokerId, socketServer.requestChannel, apis, config.numIoThreads) brokerState.newState(RunningAsBroker) Mx4jLoader.maybeLoad() /* start dynamic config manager */ dynamicConfigHandlers = Map[String, ConfigHandler](ConfigType.Topic -> new TopicConfigHandler(logManager), ConfigType.Client -> new ClientIdConfigHandler(apis.quotaManagers)) // Apply all existing client configs to the ClientIdConfigHandler to bootstrap the overrides // TODO: Move this logic to DynamicConfigManager AdminUtils.fetchAllEntityConfigs(zkUtils, ConfigType.Client).foreach { case (clientId, properties) => dynamicConfigHandlers(ConfigType.Client).processConfigChanges(clientId, properties) } // Create the config manager. start listening to notifications dynamicConfigManager = new DynamicConfigManager(zkUtils, dynamicConfigHandlers) dynamicConfigManager.startup() /* tell everyone we are alive */ val listeners = config.advertisedListeners.map {case(protocol, endpoint) => if (endpoint.port == 0) (protocol, EndPoint(endpoint.host, socketServer.boundPort(protocol), endpoint.protocolType)) else (protocol, endpoint) } kafkaHealthcheck = new KafkaHealthcheck(config.brokerId, listeners, zkUtils) kafkaHealthcheck.startup() /* register broker metrics */ registerStats() shutdownLatch = new CountDownLatch(1) startupComplete.set(true) isStartingUp.set(false) AppInfoParser.registerAppInfo(jmxPrefix, config.brokerId.toString) info("started") } } catch { case e: Throwable => fatal("Fatal error during KafkaServer startup. Prepare to shutdown", e) isStartingUp.set(false) shutdown() throw e } }
2.3.1 KafkaScheduler
KafkaScheduler是一个基于java.util.concurrent.ScheduledThreadPoolExecutor的scheduler,它内部是以前缀kafka-scheduler-xx的线程池处理真正的工作。
注意xx是线程序列号。
/** * A scheduler based on java.util.concurrent.ScheduledThreadPoolExecutor * * It has a pool of kafka-scheduler- threads that do the actual work. * * @param threads The number of threads in the thread pool * @param threadNamePrefix The name to use for scheduler threads. This prefix will have a number appended to it. * @param daemon If true the scheduler threads will be "daemon" threads and will not block jvm shutdown. */@threadsafeclass KafkaScheduler(val threads: Int, val threadNamePrefix: String = "kafka-scheduler-", daemon: Boolean = true) extends Scheduler with Logging { private var executor: ScheduledThreadPoolExecutor = null private val schedulerThreadId = new AtomicInteger(0) override def startup() { debug("Initializing task scheduler.") this synchronized { if(isStarted) throw new IllegalStateException("This scheduler has already been started!") executor = new ScheduledThreadPoolExecutor(threads) executor.setContinueExistingPeriodicTasksAfterShutdownPolicy(false) executor.setExecuteExistingDelayedTasksAfterShutdownPolicy(false) executor.setThreadFactory(new ThreadFactory() { def newThread(runnable: Runnable): Thread = Utils.newThread(threadNamePrefix + schedulerThreadId.getAndIncrement(), runnable, daemon) }) } }
2.3.2 zk初始化
zk初始化主要完成两件事情:
val zkUtils = ZkUtils(config.zkConnect, config.zkSessionTimeoutMs, config.zkConnectionTimeoutMs, secureAclsEnabled) zkUtils.setupCommonPaths()一个是连接到zk服务器;二是创建通用节点。
通用节点包括:
// These are persistent ZK paths that should exist on kafka broker startup. val persistentZkPaths = Seq(ConsumersPath, BrokerIdsPath, BrokerTopicsPath, EntityConfigChangesPath, getEntityConfigRootPath(ConfigType.Topic), getEntityConfigRootPath(ConfigType.Client), DeleteTopicsPath, BrokerSequenceIdPath, IsrChangeNotificationPath)
2.3.3 日志管理器LogManager
LogManager是kafka的子系统,负责log的创建,检索及清理。所有的读写操作由单个的日志实例来代理。
/** * Start the background threads to flush logs and do log cleanup */ def startup() { /* Schedule the cleanup task to delete old logs */ if(scheduler != null) { info("Starting log cleanup with a period of %d ms.".format(retentionCheckMs)) scheduler.schedule("kafka-log-retention", cleanupLogs, delay = InitialTaskDelayMs, period = retentionCheckMs, TimeUnit.MILLISECONDS) info("Starting log flusher with a default period of %d ms.".format(flushCheckMs)) scheduler.schedule("kafka-log-flusher", flushDirtyLogs, delay = InitialTaskDelayMs, period = flushCheckMs, TimeUnit.MILLISECONDS) scheduler.schedule("kafka-recovery-point-checkpoint", checkpointRecoveryPointOffsets, delay = InitialTaskDelayMs, period = flushCheckpointMs, TimeUnit.MILLISECONDS) } if(cleanerConfig.enableCleaner) cleaner.startup() }
2.3.4 SocketServer
SocketServer是nio的socket服务器,线程模型是:1个Acceptor线程处理新连接,Acceptor还有多个处理器线程,每个处理器线程拥有自己的selector和多个读socket请求Handler线程。handler线程处理请求并产生响应写给处理器线程。
/** * Start the socket server */ def startup() { this.synchronized { connectionQuotas = new ConnectionQuotas(maxConnectionsPerIp, maxConnectionsPerIpOverrides) val sendBufferSize = config.socketSendBufferBytes val recvBufferSize = config.socketReceiveBufferBytes val maxRequestSize = config.socketRequestMaxBytes val connectionsMaxIdleMs = config.connectionsMaxIdleMs val brokerId = config.brokerId var processorBeginIndex = 0 endpoints.values.foreach { endpoint => val protocol = endpoint.protocolType val processorEndIndex = processorBeginIndex + numProcessorThreads for (i <- processorBeginIndex until processorEndIndex) { processors(i) = new Processor(i, time, maxRequestSize, requestChannel, connectionQuotas, connectionsMaxIdleMs, protocol, config.values, metrics ) } val acceptor = new Acceptor(endpoint, sendBufferSize, recvBufferSize, brokerId, processors.slice(processorBeginIndex, processorEndIndex), connectionQuotas) acceptors.put(endpoint, acceptor) Utils.newThread("kafka-socket-acceptor-%s-%d".format(protocol.toString, endpoint.port), acceptor, false).start() acceptor.awaitStartup() processorBeginIndex = processorEndIndex } } newGauge("NetworkProcessorAvgIdlePercent", new Gauge[Double] { def value = allMetricNames.map( metricName => metrics.metrics().get(metricName).value()).sum / totalProcessorThreads } ) info("Started " + acceptors.size + " acceptor threads") }
2.3.5 复制管理器
启动ISR过期线程
def startup() { // start ISR expiration thread scheduler.schedule("isr-expiration", maybeShrinkIsr, period = config.replicaLagTimeMaxMs, unit = TimeUnit.MILLISECONDS) scheduler.schedule("isr-change-propagation", maybePropagateIsrChanges, period = 2500L, unit = TimeUnit.MILLISECONDS) }
2.3.6 kafka控制器
当kafka 服务器的控制器模块启动时激活,但并不认为当前的代理就是控制器。它仅仅注册了session过期监听器和启动控制器选主。
def startup() = { inLock(controllerContext.controllerLock) { info("Controller starting up") registerSessionExpirationListener() isRunning = true controllerElector.startup info("Controller startup complete") } }
session过期监听器注册:
private def registerSessionExpirationListener() = { zkUtils.zkClient.subscribeStateChanges(new SessionExpirationListener()) } public void subscribeStateChanges(final IZkStateListener listener) { synchronized (_stateListener) { _stateListener.add(listener); } }
class SessionExpirationListener() extends IZkStateListener with Logging {
this.logIdent = "[SessionExpirationListener on " + config.brokerId + "], "
@throws(classOf[Exception])
def handleStateChanged(state: KeeperState) {
// do nothing, since zkclient will do reconnect for us.
}
选主过程:
def startup { inLock(controllerContext.controllerLock) { controllerContext.zkUtils.zkClient.subscribeDataChanges(electionPath, leaderChangeListener) elect } }def elect: Boolean = { val timestamp = SystemTime.milliseconds.toString val electString = Json.encode(Map("version" -> 1, "brokerid" -> brokerId, "timestamp" -> timestamp)) leaderId = getControllerID /* * We can get here during the initial startup and the handleDeleted ZK callback. Because of the potential race condition, * it's possible that the controller has already been elected when we get here. This check will prevent the following * createEphemeralPath method from getting into an infinite loop if this broker is already the controller. */ if(leaderId != -1) { debug("Broker %d has been elected as leader, so stopping the election process.".format(leaderId)) return amILeader } try { val zkCheckedEphemeral = new ZKCheckedEphemeral(electionPath, electString, controllerContext.zkUtils.zkConnection.getZookeeper, JaasUtils.isZkSecurityEnabled()) zkCheckedEphemeral.create() info(brokerId + " successfully elected as leader") leaderId = brokerId onBecomingLeader() } catch { case e: ZkNodeExistsException => // If someone else has written the path, then leaderId = getControllerID if (leaderId != -1) debug("Broker %d was elected as leader instead of broker %d".format(leaderId, brokerId)) else warn("A leader has been elected but just resigned, this will result in another round of election") case e2: Throwable => error("Error while electing or becoming leader on broker %d".format(brokerId), e2) resign() } amILeader } def amILeader : Boolean = leaderId == brokerId
2.3.7 GroupCoordinator
GroupCoordinator处理组成员管理和offset管理,每个kafka服务器初始化一个协作器来负责一系列组别。每组基于它们的组名来赋予协作器。
def startup() { info("Starting up.") heartbeatPurgatory = new DelayedOperationPurgatory[DelayedHeartbeat]("Heartbeat", brokerId) joinPurgatory = new DelayedOperationPurgatory[DelayedJoin]("Rebalance", brokerId) isActive.set(true) info("Startup complete.") }
注意:若同时需要一个组锁和元数据锁,请务必保证先获取组锁,然后获取元数据锁来防止死锁。
2.3.8 KafkaApis消息处理接口
/** * Top-level method that handles all requests and multiplexes to the right api */ def handle(request: RequestChannel.Request) { try{ trace("Handling request:%s from connection %s;securityProtocol:%s,principal:%s". format(request.requestObj, request.connectionId, request.securityProtocol, request.session.principal)) request.requestId match { case RequestKeys.ProduceKey => handleProducerRequest(request) case RequestKeys.FetchKey => handleFetchRequest(request) case RequestKeys.OffsetsKey => handleOffsetRequest(request) case RequestKeys.MetadataKey => handleTopicMetadataRequest(request) case RequestKeys.LeaderAndIsrKey => handleLeaderAndIsrRequest(request) case RequestKeys.StopReplicaKey => handleStopReplicaRequest(request) case RequestKeys.UpdateMetadataKey => handleUpdateMetadataRequest(request) case RequestKeys.ControlledShutdownKey => handleControlledShutdownRequest(request) case RequestKeys.OffsetCommitKey => handleOffsetCommitRequest(request) case RequestKeys.OffsetFetchKey => handleOffsetFetchRequest(request) case RequestKeys.GroupCoordinatorKey => handleGroupCoordinatorRequest(request) case RequestKeys.JoinGroupKey => handleJoinGroupRequest(request) case RequestKeys.HeartbeatKey => handleHeartbeatRequest(request) case RequestKeys.LeaveGroupKey => handleLeaveGroupRequest(request) case RequestKeys.SyncGroupKey => handleSyncGroupRequest(request) case RequestKeys.DescribeGroupsKey => handleDescribeGroupRequest(request) case RequestKeys.ListGroupsKey => handleListGroupsRequest(request) case requestId => throw new KafkaException("Unknown api code " + requestId) } } catch { case e: Throwable => if ( request.requestObj != null) request.requestObj.handleError(e, requestChannel, request) else { val response = request.body.getErrorResponse(request.header.apiVersion, e) val respHeader = new ResponseHeader(request.header.correlationId) /* If request doesn't have a default error response, we just close the connection. For example, when produce request has acks set to 0 */ if (response == null) requestChannel.closeConnection(request.processor, request) else requestChannel.sendResponse(new Response(request, new ResponseSend(request.connectionId, respHeader, response))) } error("error when handling request %s".format(request.requestObj), e) } finally request.apiLocalCompleteTimeMs = SystemTime.milliseconds }
我们以处理消费者请求为例:
/** * Handle a produce request */ def handleProducerRequest(request: RequestChannel.Request) { val produceRequest = request.requestObj.asInstanceOf[ProducerRequest] val numBytesAppended = produceRequest.sizeInBytes val (authorizedRequestInfo, unauthorizedRequestInfo) = produceRequest.data.partition { case (topicAndPartition, _) => authorize(request.session, Write, new Resource(Topic, topicAndPartition.topic)) } // the callback for sending a produce response def sendResponseCallback(responseStatus: Map[TopicAndPartition, ProducerResponseStatus]) { val mergedResponseStatus = responseStatus ++ unauthorizedRequestInfo.mapValues(_ => ProducerResponseStatus(ErrorMapping.TopicAuthorizationCode, -1)) var errorInResponse = false mergedResponseStatus.foreach { case (topicAndPartition, status) => if (status.error != ErrorMapping.NoError) { errorInResponse = true debug("Produce request with correlation id %d from client %s on partition %s failed due to %s".format( produceRequest.correlationId, produceRequest.clientId, topicAndPartition, ErrorMapping.exceptionNameFor(status.error))) } } def produceResponseCallback(delayTimeMs: Int) { if (produceRequest.requiredAcks == 0) { // no operation needed if producer request.required.acks = 0; however, if there is any error in handling // the request, since no response is expected by the producer, the server will close socket server so that // the producer client will know that some error has happened and will refresh its metadata if (errorInResponse) { val exceptionsSummary = mergedResponseStatus.map { case (topicAndPartition, status) => topicAndPartition -> ErrorMapping.exceptionNameFor(status.error) }.mkString(", ") info( s"Closing connection due to error during produce request with correlation id ${produceRequest.correlationId} " + s"from client id ${produceRequest.clientId} with ack=0\n" + s"Topic and partition to exceptions: $exceptionsSummary" ) requestChannel.closeConnection(request.processor, request) } else { requestChannel.noOperation(request.processor, request) } } else { val response = ProducerResponse(produceRequest.correlationId, mergedResponseStatus, produceRequest.versionId, delayTimeMs) requestChannel.sendResponse(new RequestChannel.Response(request, new RequestOrResponseSend(request.connectionId, response))) } } // When this callback is triggered, the remote API call has completed request.apiRemoteCompleteTimeMs = SystemTime.milliseconds quotaManagers(RequestKeys.ProduceKey).recordAndMaybeThrottle(produceRequest.clientId, numBytesAppended, produceResponseCallback) } if (authorizedRequestInfo.isEmpty) sendResponseCallback(Map.empty) else { val internalTopicsAllowed = produceRequest.clientId == AdminUtils.AdminClientId // call the replica manager to append messages to the replicas replicaManager.appendMessages( produceRequest.ackTimeoutMs.toLong, produceRequest.requiredAcks, internalTopicsAllowed, authorizedRequestInfo, sendResponseCallback) // if the request is put into the purgatory, it will have a held reference // and hence cannot be garbage collected; hence we clear its data here in // order to let GC re-claim its memory since it is already appended to log produceRequest.emptyData() } }
对应kafka producer的acks配置:
The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the durability of records that are sent. The following settings are common:acks=0 If set to zero then the producer will not wait for any acknowledgment from the server at all. The record will be immediately added to the socket buffer and considered sent. No guarantee can be made that the server has received the record in this case, and the retries configuration will not take effect (as the client won't generally know of any failures). The offset given back for each record will always be set to -1.acks=1 This will mean the leader will write the record to its local log but will respond without awaiting full acknowledgement from all followers. In this case should the leader fail immediately after acknowledging the record but before the followers have replicated it then the record will be lost.acks=all This means the leader will wait for the full set of in-sync replicas to acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica remains alive. This is the strongest available guarantee.
2.3.9 动态配置管理DynamicConfigManager
利用zookeeper做动态配置中心
/** * Begin watching for config changes */ def startup() { zkUtils.makeSurePersistentPathExists(ZkUtils.EntityConfigChangesPath) zkUtils.zkClient.subscribeChildChanges(ZkUtils.EntityConfigChangesPath, ConfigChangeListener) processAllConfigChanges() } /** * Process all config changes */ private def processAllConfigChanges() { val configChanges = zkUtils.zkClient.getChildren(ZkUtils.EntityConfigChangesPath) import JavaConversions._ processConfigChanges((configChanges: mutable.Buffer[String]).sorted) } /** * Process the given list of config changes */ private def processConfigChanges(notifications: Seq[String]) { if (notifications.size > 0) { info("Processing config change notification(s)...") val now = time.milliseconds for (notification <- notifications) { val changeId = changeNumber(notification) if (changeId > lastExecutedChange) { val changeZnode = ZkUtils.EntityConfigChangesPath + "/" + notification val (jsonOpt, stat) = zkUtils.readDataMaybeNull(changeZnode) processNotification(jsonOpt) } lastExecutedChange = changeId } purgeObsoleteNotifications(now, notifications) } }
2.3.10 心跳检测KafkaHealthcheck
心跳检测也使用zookeeper维持:
def startup() { zkUtils.zkClient.subscribeStateChanges(sessionExpireListener) register() } /** * Register this broker as "alive" in zookeeper */ def register() { val jmxPort = System.getProperty("com.sun.management.jmxremote.port", "-1").toInt val updatedEndpoints = advertisedEndpoints.mapValues(endpoint => if (endpoint.host == null || endpoint.host.trim.isEmpty) EndPoint(InetAddress.getLocalHost.getCanonicalHostName, endpoint.port, endpoint.protocolType) else endpoint ) // the default host and port are here for compatibility with older client // only PLAINTEXT is supported as default // if the broker doesn't listen on PLAINTEXT protocol, an empty endpoint will be registered and older clients will be unable to connect val plaintextEndpoint = updatedEndpoints.getOrElse(SecurityProtocol.PLAINTEXT, new EndPoint(null,-1,null)) zkUtils.registerBrokerInZk(brokerId, plaintextEndpoint.host, plaintextEndpoint.port, updatedEndpoints, jmxPort) }
3. 小结
kafka中KafkaServer类,采用门面模式,是网络处理,io处理等得入口.
ReplicaManager 副本管理
KafkaApis 处理所有request的Proxy类,根据requestKey决定调⽤用具体的handler
KafkaRequestHandlerPool 处理request的线程池,请求处理池 <-- num.io.threads io线程数量
LogManager kafka文件存储系统管理,负责处理和存储所有Kafka的topic的partiton数据
TopicConfigManager 监听此zk节点的⼦子节点/config/changes/,通过LogManager更新topic的配置信息,topic粒度配置管理,具体请查看topic级别配置
KafkaHealthcheck 监听zk session expire,在zk上创建broker信息,便于其他broker和consumer获取其信息
KafkaController kafka集群中央控制器选举,leader选举,副本分配。
KafkaScheduler 负责副本管理和日志管理调度等等
ZkClient 负责注册zk相关信息.
BrokerTopicStats topic信息统计和监控
ControllerStats 中央控制器统计和监控
参考文献
【1】https://zqhxuyuan1.gitbooks.io/kafka/content/chapter1-intro.html
【2】http://blog.csdn.net/lizhitao/article/details/37911993
- kafka源码分析之一server启动分析
- Zookeeper源码分析之一Server启动
- kafka源码分析之kafka启动-SocketServer
- Tomcat Server源码启动分析
- lighttpd 源码分析之一 server.c
- zookeeper源码分析之一启动过程
- kafka源码分析
- kafka源码分析
- storm-kafka源码分析
- Kafka源码分析
- kafka源码分析
- kafka源码分析一
- kafka源码分析二
- kafka源码分析三
- System Server进程启动过程源码分析
- System Server进程启动过程源码分析
- [android源码分析]sdp Server的启动分析
- [android源码分析]sdp Server的启动分析
- 枚举类型
- idea Failed to start component
- codevs1222 二分图匹配
- iOS——Storyboard使用
- PAT(Python)-1020:月饼(25)
- kafka源码分析之一server启动分析
- 欢迎使用CSDN-markdown编辑器
- nyoj-背包问题(贪心)
- Snackbar源码解析
- 关于Jdbc调用存储过程得到返回值为0(null)的问题
- c语言文件的读写操作
- bzoj3527 [Zjoi2014]力
- 在现有系统基础上扩展storm
- JavaScript学习one


