深度学习入门帖子,转自知乎,也希望能与大家共享
来源:互联网 发布:钢铁力量6级天炉数据 编辑:程序博客网 时间:2024/05/29 07:31
因为近期要做一个关于深度学习入门的技术分享,不想堆砌公式,让大家听得一头雾水不知不觉摸裤兜掏手机刷知乎。所以花了大量时间查资料看论文,有的博客或者论文写得非常赞,比如三巨头LeCun,Bengio和Hinton 2015年在Nature上发表综述论文的“Deep Learning”,言简意赅地引用了上百篇论文,但适合阅读,不适合presentation式的分享;再如Michael Nielsen写的电子书《神经网络与深度学习》(中文版,英文版)通俗易懂,用大量的例子解释了深度学习中的相关概念和基本原理,但适合于抽两三天的功夫来细品慢嚼,方能体会到作者的良苦用心;还有Colah写的博客,每一篇详细阐明了一个主题,如果已经入门,这些博客将带你进阶,非常有趣。
还翻了很多知乎问答,非常赞。但发现很多”千赞侯”走的是汇总论文视频教程以及罗列代码路线,本来想两小时入门却一脚踏进了汪洋大海;私以为,这种适合于有一定实践积累后按需查阅。还有很多”百赞户”会拿鸡蛋啊猫啊狗啊的例子来解释深度学习的相关概念,生动形象,但我又觉得有避重就轻之嫌。我想,既然要入门深度学习,得有微积分的基础,会求导数偏导数,知道链式法则,最好还学过线性代数;否则,真的,不建议入门深度学习。
最后,实在没找到我想要的表达方式。我想以图的方式概要而又系统性的呈现深度学习所涉及到的基本模型和相关概念。论文“A Critical Review of Recurrent Neural Networks for Sequence Learning”中的示意图画得简单而又形象,足以说明问题,但这篇文章仅就RNN而展开论述,并未涉及CNN,RBM等其它经典模型;Deeplearning4j上的教程貌似缺少关于编码器相关内容的介绍,而UFLDL教程只是详细介绍了编码器的方方面面。但是如果照抄以上三篇的图例,又涉及到图例中的模块和符号不统一的问题。所以,索性自己画了部分模型图;至于直接引用的图,文中已经给了链接或出处。如有不妥之处,望指正。以下,以飨来访。
1. 从经典的二分类开始说起,为此构建二分类的神经网络单元,并以Sigmoid函数和平方差损失(比较常用的还有交叉熵损失函数)函数来举例说明梯度下降法以及基于链式法则的反向传播(BP),所有涉及到的公式都在这里:
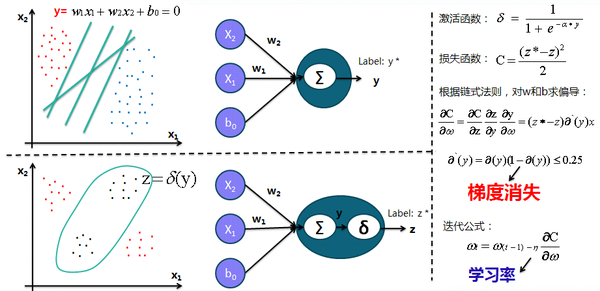
2. 神经元中的非线性变换激活函数(深度学习中的激活函数导引)及其作用(参考颜沁睿的回答),激活函数是神经网络强大的基础,好的激活函数(根据任务来选择)还可以加速训练:
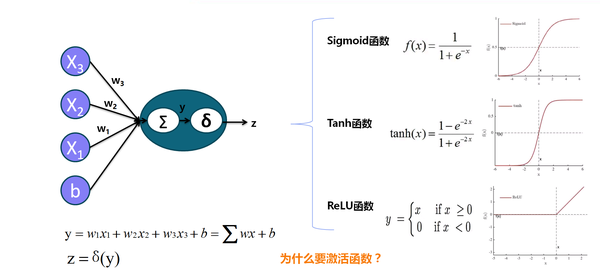 不同的激活函数搭配不同的参数初始化策略,比如Tahn和Xavier初始化方法:
不同的激活函数搭配不同的参数初始化策略,比如Tahn和Xavier初始化方法:
以及ReLU和MSRAFiller初始化(Srurpassing Human)方法。
3. 前馈性神经网络和自动编码器的区别在于输出层,从而引出无监督学习的概念;而降噪编码器和自动编码器的区别又在输入层,即对输入进行部分遮挡或加入噪声;稀疏编码器(引出正则项的概念)和自动编码器的区别在隐藏层,即隐藏层的节点数大于输入层节点数;而编码器都属于无监督学习的范畴。浅层网络的不断栈式叠加构成相应的深度网络。
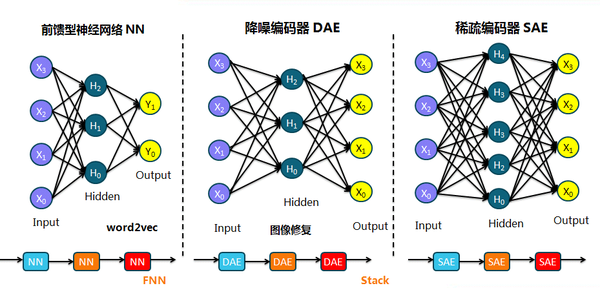 值得一提的是,三层前馈型神经网络(只包含一个隐藏层)的word2vec(数学原理详解)是迈向NLP的大门,包括CBOW和skip-gram两种模型,另外在输出层还分别做了基于Huffman树的Hierarchical Softmax以及negative sampling(就是选择性地更新连接负样本的权重参数)的加速。
值得一提的是,三层前馈型神经网络(只包含一个隐藏层)的word2vec(数学原理详解)是迈向NLP的大门,包括CBOW和skip-gram两种模型,另外在输出层还分别做了基于Huffman树的Hierarchical Softmax以及negative sampling(就是选择性地更新连接负样本的权重参数)的加速。4. 受限波兹曼机RBM属于无监督学习中的生成学习,输入层和隐藏层的传播是双向的,分正向过程和反向过程,学习的是数据分布,因此又引出马尔可夫过程和Gibbs采样的概念,以及KL散度的度量概念:
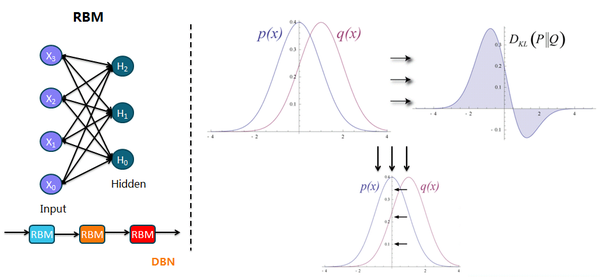 与生成学习对应的是判别学习也就是大多数的分类器,生成对抗网络GAN融合两者;对抗是指生成模型与判别模型的零和博弈,近两年最激动人心的应用是从文本生成图像(Evolving AI Lab - University of Wyoming):
与生成学习对应的是判别学习也就是大多数的分类器,生成对抗网络GAN融合两者;对抗是指生成模型与判别模型的零和博弈,近两年最激动人心的应用是从文本生成图像(Evolving AI Lab - University of Wyoming): 再推荐一个讲DCGAN的超赞教程Image Completion with Deep Learning in TensorFlow:
再推荐一个讲DCGAN的超赞教程Image Completion with Deep Learning in TensorFlow:
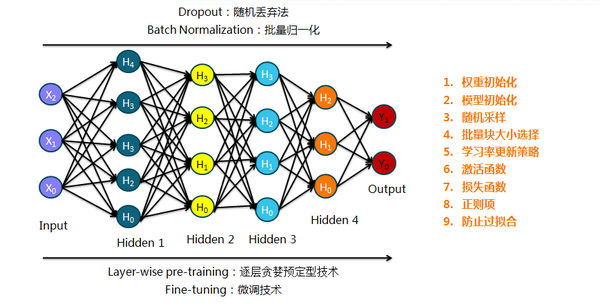
5. 深度网络的实现基于逐层贪心训练算法,而随着模型的深度逐渐增加,会产生梯度消失或梯度爆炸的问题,梯度爆炸一般采用阈值截断的方法解决,而梯度消失不易解决;网络越深,这些问题越严重,这也是深度学习的核心问题,出现一系列技术及衍生模型。
深度制胜,网络越深越好,因此有了深度残差网络将深度扩展到152层,并在ImageNe多项竞赛任务中独孤求败: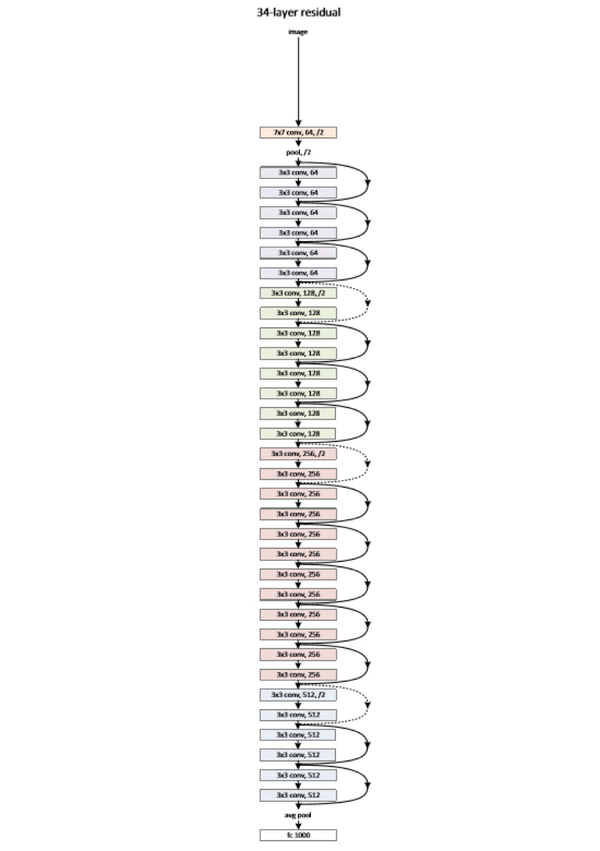
6. 卷积神经网络在层与层之间采取局部链接的方式,即卷积层和采样层,在计算机视觉的相关任务上有突出表现,关于卷积神经网络的更多介绍请参考我的另一篇文章(戳戳戳):
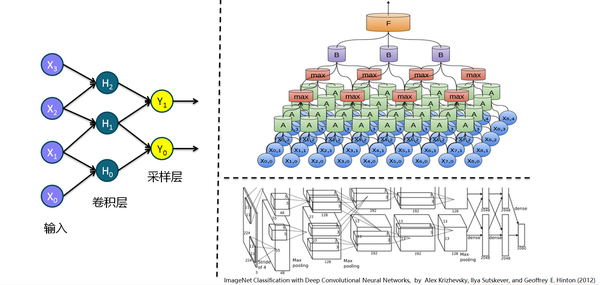
而在NIPS 2016上来自康奈尔大学计算机系的副教授 Killan Weinberger 探讨了深度极深的卷积网络,在数据集CIFAR-10 上训练一个 1202 层深的网络。
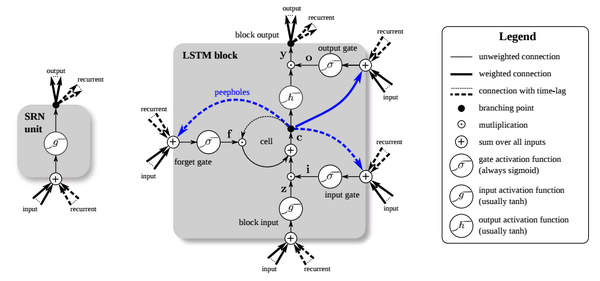
7. 循环神经网络在隐藏层之间建立了链接,以利用时间维度上的历史信息和未来信息,与此同时在时间轴上也会产生梯度消失和梯度爆炸现象,而LSTM和GRU则在一定程度上解决了这个问题,两者与经典RNN的区别在隐藏层的神经元内部结构,在语音识别,NLP(比如RNNLM)和机器翻译上有突出表现(推荐阅读):
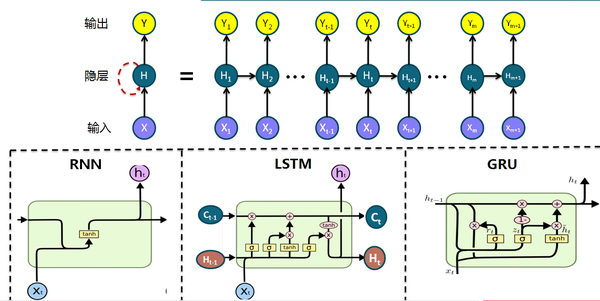 除了RNNLM采用最简单最经典的RNN模型,其他任务隐层神经元往往采用LSTM或者GRU形式,关于LSTM的进化历史,一图胜千言,更多内容可以参阅LSTM: A Search Space Odyssey:
除了RNNLM采用最简单最经典的RNN模型,其他任务隐层神经元往往采用LSTM或者GRU形式,关于LSTM的进化历史,一图胜千言,更多内容可以参阅LSTM: A Search Space Odyssey:
RNN模型在一定程度上也算是分类器,在图像描述(Deep Visual-Semantic Alignments for Generating Image Descriptions)的任务中已经取得了不起的成果(第四节GAN用文本生成图像是逆过程,注意区别):

另外,关于RNN的最新研究是基于attention机制来建立模型(推荐阅读文章),即能够在时间轴上选择有效信息加以利用,比如百度App中的"为你写诗"的功能核心模型就是attention-based RNN encoder-decoder:
8. 总结了深度学习中的基本模型并再次解释部分相关的技术概念:
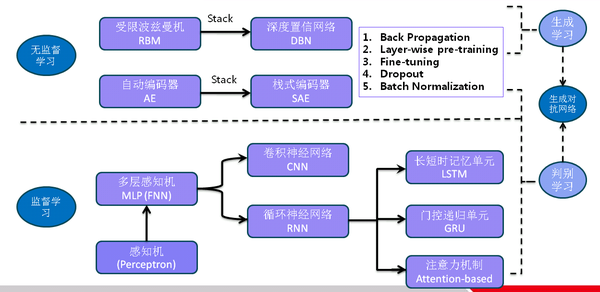
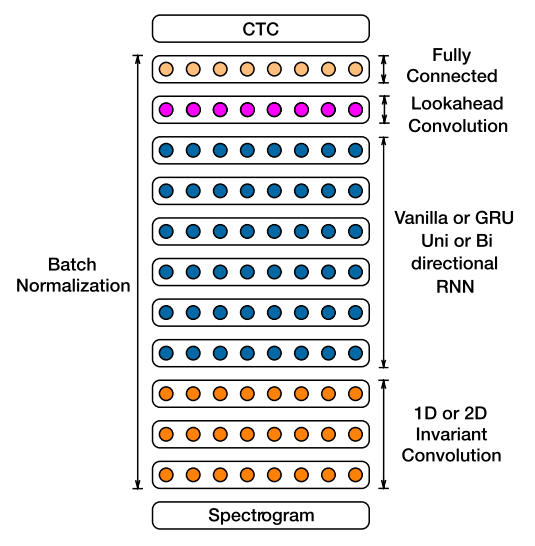
最后,现在深度学习在工业中的应用往往是整合多个模型到产品中去,比如在语音识别的端到端系统中,利用无监督模型或者CNN作为前期处理提取特征,然后用RNN模型进行逻辑推理和判断,从而达到可媲美人类交流的水平,如百度的DeepSpeech2:
画图是个细活慢活,周末加班很辛苦,觉得好就动动手指给个赞吧。
不喜请喷,转载请注明出处,谢谢。
转自https://www.zhihu.com/question/26006703/answer/135825424
- 深度学习入门帖子,转自知乎,也希望能与大家共享
- 如何学习源码----转自知乎
- 转自知乎的吉他学习篇
- 技术交流 ,希望与大家共享
- 转自知乎
- 转自知乎
- 希望大家能共同学习 一起进步
- 希望能和大家一起学习Java
- 如何学习安卓软件开发?(转自知乎)
- 建网站学习指导(转自知乎)
- 大牛学习爬虫经验,转自知乎
- 如何系统学习大数据(转自知乎)
- 机器学习的第一天--转自知乎
- 极大似然估计与最小二乘法(转自知乎)
- 中国教育(转自知乎)
- PopupWindow(第一篇CSDN博客,希望能坚持写下去,也希望大家多多支持)
- 来自知乎的Android学习总结
- 来自知乎的Android学习总结
- Android Activity启动、关闭、Activity返回结果到启动它的Activity
- MongoDB用户管理
- BZOJ 1231: [Usaco2008 Nov]mixup2 混乱的奶牛 状压DP
- 【OpenGL】OpenGL系列——05像素操作
- ZooKeeper 故障恢复
- 深度学习入门帖子,转自知乎,也希望能与大家共享
- C++求斐波那切数列及前n项和
- 哈希表及处理冲突的方法
- C语言入门之--指针
- List和tuple
- 关于Android中图片大小、内存占用与drawable文件夹关系的研究与分析
- es搜索引擎的使用
- 【OpenGL】OpenGL系列——06纹理映射
- Android动画-View动画的使用场景


