DFS&BFS入门
来源:互联网 发布:facebook知乎 编辑:程序博客网 时间:2024/05/07 22:35
以下内容约是入门内容的一半吧。
简而言之,bfs和dfs 是对于在树或者图之类结构上的数据进行搜索得出想要的答案的搜索方法。不同的是,如果把搜索对象范围比喻成为一个多分支的洞穴的话,dfs就是放一只由程序跟踪的老鼠进去,走到每个尽头再返回继续探索下一个,而bfs就是从洞口向里面倒由程序跟踪的水,同步进行到各个分枝洞穴。
1.关于DFS。
其函数常常会是这样的:
void dfs(int start){
if(no)
return;
Dosomethinginteresting();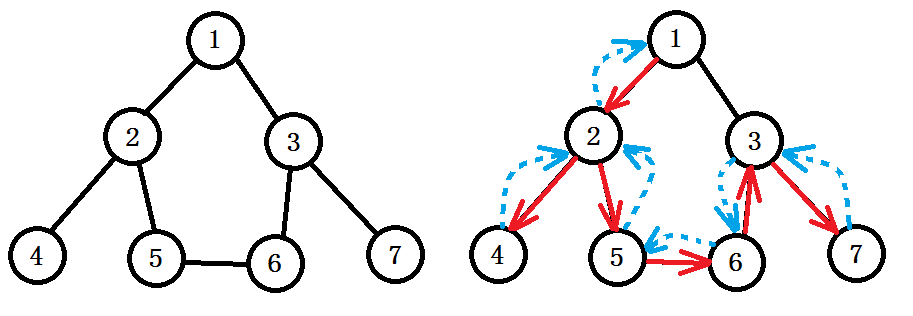
for(i=0;i<n;i++)
if(ok)
{
// visited=1;
dfs(next);
// visited=0;
}
}
其实际执行情况就如同右图。红色箭头就表示dfs程序的执行过程。对于深搜dfs,具体描述应该是:
(1)指定一个当前节点,标记已经访问。
(2)把当前节点的每个未被访问的子节点当做当前节点进行递归,执行(1)。
(3)不满足条件时进行回溯。
由于深搜在进行过程中都是沿着数据结构的指定方向前进的,所以能够很清楚的记录下来走过的路以及走过的时间。但是,在数据量太大的时候,由于用的是递归的单线搜索,很容易出现运行时间很长的情况。而对于求最短路径的问题,dfs需要枚举所有可能的路径然后进行比较,过程会比较繁琐。
为了使得dfs运行时间更快,有一个常用方法那就是剪枝。剪枝在程序里面的体现往往就是一个if(no) break; 或者if(no) return;剪枝规避了一些不符合要求的深搜路径使得程序不会去走那些已经知道是错误的路。比如有时候题目要求在偶数步数走到一个距离奇数步数的节点,这是不可能的,所以不需要进行任何深搜。
另外,记忆化也是一个有效的改进方法。对于在一个相互连接的图样结构中,各个路径有可能访问相同的节点,那么为了避免走同样的路,第一次走过这个节点的时候就可以将它的值存在一个数组之中,那么就可以避免重复递归了。程序实现就是定义二维数组a[m][n],初始化全部为0。当程序走到节点(m,n)时,如果a[m][n]==0,那么把值存进去,如果不为零,直接读取使用即可。
2、关于BFS
其函数大概是这样的:
void BFS(? asd)
{
queue<?> a;//? 为一种数据类型
a.push(asd);
while(1)
{
? point = a.front();
if(a yes )
{
DoSomethingExciting();
break;
}
for(i=0;i<n;i++)
if(yes){
? fd = initial();
a.push(fd);
}
if(!a.empty())
a.pop();
if(a.empty())
{
DosometingBad();
break;
}
}
}
上面的伪代码用的是队列结构来存储过程变量。也可以用数组结构来储存。
如果用数组来存储的话,这里就需要用到两个关键变量num 和 low。
low=now=0;
while(1)
{
int th = low;
if(yes(asd[th])){
Dosomethingmagic();
break;
}
for(i=0;i<n;i++)
if(yes)
asd[++now]=deal(asd[th]);
if(low>now)
break;
low++;
}
期中asd[]就是类似于队列的存在。
上图就是bfs的执行路径。
具体来说,BFS执行过程如下:
(1)如果队列不是空的,那么弹出一个a记为当前节点。
(2)将当前节点的所有未被访问的子节点全部存入队列中。执行(1)
广搜最适用的情况就是求最短路径的题目。由于是各个支线同步进行,它能够最快的找到目标。但是也是因为如此,它无差别记录了所有节点会占用较大的内存。另外,由于没有从遵守目标结构的顺序,所以在获取路径的时候需要额外的操作量。即每一个节点必须要存储上一个节点的位置。另外在数据量比较大的时候,应该把队列定义位全局变量,以免栈溢出。
BFS一个简单的优化就是双向广搜,在知道目标点和初始点时适用。在一个图类结构中,现在定义两个队列,一个以初始点为开始点,一个以结束点为开始点,两个队列同时进入循环。只要有一个队列为空,那么就知道无法达到,可以直接跳出循环。然而这里有一个问题就是,两个搜索指针是很难走到一起,那么我们必须知道搜索的节点是否已经被对方搜索过了,如果题目对象仅仅占用一个节点,那么标记是很简单的;如果题目对象占用多个节点或者其他复杂情况那么判断起来会有一些难度。
另外,在广搜节点的储存之前加上if判断语句来剪枝也是和dfs类似的,不再叙述。
总结:
bfs占空间,dfs占时间,这是个令人头疼的问题。但是,做搜索类题目还有一个困难就是读题。如何把题目的研究对象抽象成一段代码,如何把题目对象的研究范围抽象成为一种数据结构,我觉得这是解题的基础也是关键。
一个简单的实例:
一个m*n的坐标图上
给定开始点@,’#’代表不能走的路,只能上下左右移动,问在输入的图中最多能走到多少块砖头上。
DFS版本:
#include<iostream>using namespace std;char map[21][21]={'\0'};int wayi[4]={0,-1,0,1};int wayj[4]={1,0,-1,0};//左上右下int num=0;int a,b;int yes=1;void go(int xi,int xj){if(yes)for(int i=0;i<4;i++){if( xi+wayi[i] >= 0 && xi+wayi[i] < b && xj+wayj[i] >= 0 && xj+wayj[i] < a )if(map[xi+wayi[i]][xj+wayj[i]]!='#') {if(map[xi+wayi[i]][xj+wayj[i]]=='.')num++;map[xi+wayi[i]][xj+wayj[i]]='#';if(num==a*b)yes=0;go(xi+wayi[i],xj+wayj[i]);}}} int main(){int starti,startj;while(cin>>a>>b&&a!=0&&b!=0){num=0;yes=1;int i,j;for(i=0;i<b;i++)for(j=0;j<a;j++){cin>>map[i][j];if(map[i][j]=='@'){starti=i;startj=j;}}map[starti][startj]=',';go(starti,startj);cout<<num+1<<endl;}return 0;}#include<iostream>using namespace std;char map[21][21]={'\0'};int wayi[4]={0,-1,0,1};int wayj[4]={1,0,-1,0};int num=0;int a,b;int zhizhen=0;int savei[400]={0};int savej[400]={0};int main(){while(cin>>a>>b&&a!=0&&b!=0){num=0;zhizhen=0;int i,j;for(i=0;i<b;i++)for(j=0;j<a;j++) {cin>>map[i][j];if(map[i][j]=='@'){savei[num]=i;savej[num]=j;}}map[savei[num]][savej[num]]='#';while(1){int xi=savei[zhizhen],xj=savej[zhizhen];for(i=0;i<4;i++){if( xi+wayi[i] >= 0 && xi+wayi[i] < b && xj+wayj[i] >= 0 && xj+wayj[i] < a )if(map[xi+wayi[i]][xj+wayj[i]]!='#'){savei[++num]=xi+wayi[i];savej[num]=xj+wayj[i];map[xi+wayi[i]][xj+wayj[i]]='#';}}zhizhen++;if(zhizhen>num)break;}cout<<num+1<<endl;}return 0;}
BFS版本
推荐一个详细解说的网站http://www.cppblog.com/menjitianya/archive/2015/10/09/211980.html
- DFS&BFS入门
- BFS和DFS入门
- poj3083 非常好 的入门级dfs+bfs
- hdu 1312 BFS DFS搜索入门
- POJ ROADS DFS BFS 优先队列 入门
- BFS-DFS
- BFS DFS
- DFS+BFS
- BFS DFS
- DFS BFS
- DFS & BFS
- BFS,DFS
- dfs bfs
- BFS&DFS
- DFS BFS
- BFS && DFS
- BFS DFS
- DFS & BFS
- Android编译系统
- java 二维数组的介绍和使用
- 图片标注工具LabelImg使用教程
- jQuery的61种选择器
- 关于GridView内容居中问题
- DFS&BFS入门
- spring mvc配置静态资源文件
- C#:解决方案、项目、类的组成,
- Redis 3.2.1集群搭建(单机)
- sudo: unable to resolve host
- 3.1 spark core 之 boardcast
- CSS的TEXT
- [Java]读取文件方法大全
- 搭建双塔(Vijos-1037)


