聚类算法
来源:互联网 发布:nginx lua function 编辑:程序博客网 时间:2024/06/06 01:08
聚类算法
聚类算法属于机器学习或数据挖掘领域内,范畴比较小,一般都算作机器学习的一部分或数据挖掘领域中的一类算法,可结合机器学习进行学习
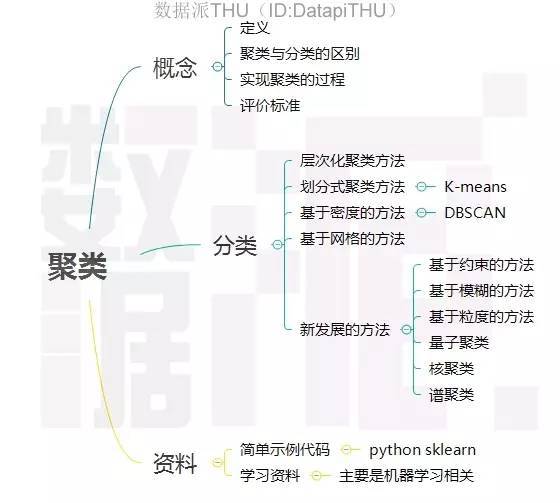
1.1 聚类的基本概念
聚类是数据挖掘中的概念,就是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。
1.2 聚类和分类的区别
- Clustering (聚类),简单地说就是把相似的东西分到一组,聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到一起;unsupervised learning (无监督学习)
- Classification (分类),对于一个classifier,通常需要你告诉它“这个东西被分为某某类”这样一些例子;supervised learning (监督学习)
1.3 聚类算法分类
层次化聚类算法, 又称树聚类算法,透过一种层次架构方式,反复将数据进行分裂或聚合。
划分式聚类算法,预先指定聚类数目或聚类中心,反复迭代逐步降低目标函数误差值直至收敛,得到最终结果。
基于模型的聚类算法, 为每簇假定了一个模型,寻找数据对给定模型的最佳拟合,同一”类“的数据属于同一种概率分布,即假设数据是根据潜在的概率分布生成的。
基于密度聚类算法,只要邻近区域的密度(对象或数据点的数目)超过某个阈值,就继续聚类
擅于解决不规则形状的聚类问题。
-基于网格的聚类算法,基于网格的方法把对象空间量化为有限数目的单元,形成一个网格结构。
阅读全文
0 0
- 聚类算法:DBScan算法
- isoData算法整理 常用算法 聚类算法 kmeans算法
- 聚类算法之K邻近算法
- 聚类算法 K-Means算法
- 聚类算法之K-mean算法
- 聚类算法之k-medoids算法
- 进化聚类算法的相关算法
- 聚类算法:K-Means算法
- 聚类算法与贪心算法
- 聚类算法和分类算法总结
- 聚类算法(二):DBSCAN算法
- 常用聚类算法以及算法评价
- 【机器学习】聚类算法:ISODATA算法
- 从DBSCAN算法谈谈聚类算法
- 聚类算法之AP算法
- 常用聚类算法以及算法评价
- R聚类算法-DBSCAN算法
- 聚类算法-dbscan算法的研究
- android:详细解读DialogFragment
- Ubuntu 16.04扩展swap分区
- AlertDialogDemo
- 进制之间的转换
- Push failed. Failed with error: fatal: Could not read from remote repository.
- 聚类算法
- docker lxc cgroup namespace入门
- java 创建线程的三种方法Callable,Runnable,Thread比较及用法
- android刮刮卡效果
- 对中级 Linux 用户非常有用的 20 个命令
- 依赖和本项目的recyclerView的版本不同解决办法
- 前端打印控件lodop的相关使用问题和相关的知识领域
- 反转二叉树
- 电影《南京 南京》对于角川最后自杀的一点个人见解


