hadoop集群环境的搭建
来源:互联网 发布:添加网络打印机步骤xp 编辑:程序博客网 时间:2024/06/05 08:53
一、集群规划
ip安装的软件192.168.52.136 node11 jdk namenode resourcemanager192.168.52.138 node22jdk datanode zookeeper journalnode namenode resourcemanager nodemanager192.168.52.137 node33jdk datanode zookeeper journalnode nodemanager192.168.52.139 node44jdk datanode zookeeper journalnode nodemanager
二、hdfs集群 HA安装步骤
1、绑定ip和主机名映射 修改/etc/hosts文件 如下图
 其他几台机器也这样修改。
其他几台机器也这样修改。
2、修改每台机器的主机名 vi /etc/sysconfig/network 内容如下

重新启动机器 命令reboot 查看主机名修改是否成功 命令hostname 显示如下
 其他机也要修改成对应的主机名
其他机也要修改成对应的主机名
3、配置node11到其他几台机器的免登录命令
[root@node11 .ssh]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
[root@node11 .ssh]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
4、把id_dsa.pub这个文件复制到其他几台机器上 并且把里面的内容加到authorized_keys这个文件里
命令 [root@node11 ~]# cat /opt/id_dsa.pub >> ~/.ssh/authorized_keys (opt文件夹是id_dsa.pub所在文件的父目录)
5、再配置node22到node11的免登录 在node22上执行命令 [root@node22 .ssh]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
[root@node22 .ssh]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
把生成的id_dsa.pub 拷贝到node11上命令[root@node22 .ssh]# scp -r id_dsa.pub node11:/opt/
在node11上执行命令 [root@node11 ~]# cat /opt/id_dsa.pub >> ~/.ssh/authorized_keys
6、上传hadoop-2.5.1_x64.tar.gz文件 解压 命令[root@node1 java]# tar -zxvf hadoop-2.5.1_x64.tar.gz
7、修改/usr/local/java/hadoop-2.5.1/etc/hadoop/hadoop-env.sh 修改内容如下

8、修改/usr/local/java/hadoop-2.5.1/etc/hadoop/core-site.xml (该文件配置的是namenode的上传下载地址) 修改内容如下
<configuration>
<property>
<name>fs.defaultFS</name> #namenode集群主机
<value>hdfs://hadoopservice</value>
</property>
<property>
<name>hadoop.tmp.dir</name> #hadoop存放临时文件的地方
<value>/opt/hadoop-2.5</value>
</property>
<property>
<name>ha.zookeeper.quorum</name> #zookeeper集群地址 zookeeper集群搭建可以参考 #https://my.oschina.net/xiaozhou18/blog/787132 这个地址
<value>node22:2181,node33:2181,node44:2181</value>
</property>
</configuration>
9、修改/usr/local/java/hadoop-2.5.1/etc/hadoop/hdfs-site.xml 修改内容如下
<configuration>
<property>
<name>dfs.nameservices</name> #给hadoop集群服务起个唯一标识
<value>hadoopservice</value>
</property>
<property>
<name>dfs.ha.namenodes.hadoopservice</name> #指定namenode机器的ip地址
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoopservice.nn1</name> #指定nn1的文件上传下载地址
<value>node11:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoopservice.nn2</name> #指定nn2的文件上传下载地址
<value>node22:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoopservice.nn1</name> #指定nn1的图形化界面地址
<value>node11:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoopservice.nn2</name> #指定nn2的图形化界面地址
<value>node22:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node22:8485;node33:8485;node44:8485/abc</value> #指定共享edits文件的地址
</property>
<property>
<name>dfs.client.failover.proxy.provider.hadoopservice</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true) #指定30000毫秒后自动切换 (很重要)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name> #指定journalnode 数据在本地的存放地址
<value>/opt/journalnode</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name> #设置当namenode挂了自动切换到另一台
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value> #和上面那个shell(/bin/true)对应
</property>
</configuration>
10、修改/usr/local/java/hadoop-2.5.1/etc/hadoop/slaves 该配置文件指定datanode主机地址 修改内容如下

11、把node11中的hadoop-2.5.1文件拷贝到其他几台机器上 命令
scp -r hadoop-2.5.1/ node22:/usr/local/java/
scp -r hadoop-2.5.1/ node33:/usr/local/java/
scp -r hadoop-2.5.1/ node44:/usr/local/java/
12、配置hadoop的环境变量 修改/etc/profile 文件内容如下
 其他几台机器也要改
其他几台机器也要改
13、在三台机器上分别启动journalnode 命令 [root@node22 hadoop]# hadoop-daemon.sh start journalnode
14、格式化hadoop 在namenode主机中的一个上 执行命令 hdfs namenode -format 这个命令执行后会创建/opt/hadoop-2.5文件 (这个地址是在core-site.xml文件中hadoop.tmp.dir中指定的)
把生成的hadoop-2.5文件拷贝到其他namenode的机器上 命令 [root@node22 bin]# scp -r /opt/hadoop-2.5/ node11:/opt/
15、格式化zookeeper 在namenode主机其中的一台上执行命令 [root@node11 bin]# ./hdfs zkfc -formatZK
16、启动hdfs 在namenode(这个namenode要设置在其他机器的免登录)的机器上执行 命令 start-dfs.sh
17、查看hdfs集群搭建成功否 在浏览器输入 http://192.168.52.136:50070 显示如图所示 该namenode是active

在浏览器输入 http://192.168.52.138:50070 显示如图所示 该namenode是standby

杀掉active的namenode进程 在浏览器输入 http://192.168.52.138:50070 显示如图所示 该namenode是active 到此hdfs集群高可用配置成功!!!!

三、mapredurce HA集群安装步骤
1、编辑/hadoop-2.5.1/etc/hadoop 下的yarn-site.xml 内容如下
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name> #指定mapredurce集群的服务名称 不能和其他集群服务重复
<value>hadoopmapred</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name> #mapredurce集群的主机名
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node11</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node22</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name> #zookeeper地址
<value>node22:2181,node33:2181,node44:2181</value>
</property>
</configuration>
2、把/hadoop-2.5.1/etc/hadoop 下的mapred-site-template.xml重名命为 mapred-site.xml命令 mv mapred-site.xml.template mapred-site.xml 修改mapred-site.xml 内容如下
<configuration>
<property>
<name>mapreduce.framework.name</name> #让mapredurce运行在yarn环境上
<value>yarn</value>
</property>
</configuration>
3、启动resourcemanager 命令 start-yarn.sh
4、备resourcemanager不会自动启动要手动启动 在备resourcemanager机器上执行命令
yarn-daemon.sh start resourcemanager
5、测试mapredurce 集群安装是否成功 在浏览器中输入 http://192.168.52.136:8088/ 显示如下界面
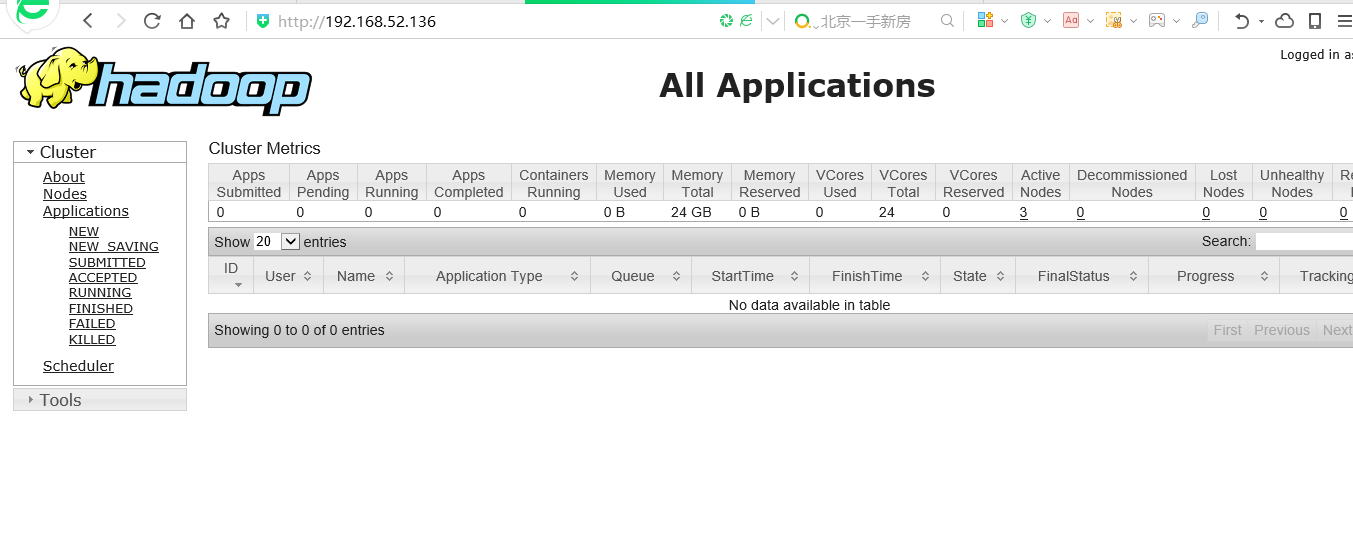
再在浏览器中输入 http://192.168.52.138:8088/ 显示如下

在把 node11中的resourcemanager 进程杀掉后 再在浏览器中输入 http://192.168.52.138:8088/ 显示如下
 mapreduce集群高可用安装成功!!!!!
mapreduce集群高可用安装成功!!!!!
- Hadoop集群环境的搭建
- hadoop集群环境的搭建
- hadoop集群环境的搭建
- hadoop集群环境的搭建
- hadoop集群环境的搭建
- hadoop集群环境的搭建
- hadoop集群环境的搭建
- hadoop集群环境的搭建
- hadoop集群环境的搭建
- Hadoop集群环境的搭建
- hadoop集群环境的搭建
- Hadoop环境搭建-集群
- hadoop集群环境搭建
- 搭建hadoop集群环境
- Hadoop集群环境搭建
- 搭建hadoop集群环境
- 搭建hadoop集群环境
- 搭建hadoop集群环境
- 监听浏览器后退事件,使其转向指定URL,控制某些页面不能返回
- 深度学习环境搭建:linux下 Ubuntu16.04+cuda8.0+cudnn+anaconda+tensorflow并配置远程访问jupyter notebook
- 算法概论课本第八章习题作业 8.8
- C.Primer.Plus(第六版)第11章 编程练习
- MediaPlayer.prepare() throws IllegalStateException
- hadoop集群环境的搭建
- HiveTSI和API编程
- MMU内存管理单元(3)-系统控制协处理器CP15
- matlab支持向量机
- Linux-视频监控系统(4)-摄像头子系统实现
- Java 并发工具包 java.util.concurrent 用户指南
- 这两周服务器被攻击,封锁了600多个IP地址段后今天服务器安静多了
- Spring Boot (教程八: 过滤器、监听器、拦截器)
- forward


