爬虫总结
来源:互联网 发布:mysql外键怎么设置 编辑:程序博客网 时间:2024/06/06 02:49
一开始接触用python 写爬虫用的是bs4 request urllib2 这些库,简单爬取网页简直不要太简单
类似这种:
# -*- coding: utf-8 -*-#---------------------------------------# 程序:百度贴吧爬虫# 版本:0.1# 作者:why# 日期:2013-05-14# 语言:Python 2.7# 操作:输入带分页的地址,去掉最后面的数字,设置一下起始页数和终点页数。# 功能:下载对应页码内的所有页面并存储为html文件。#--------------------------------------- import string, urllib2 #定义百度函数def baidu_tieba(url,begin_page,end_page): for i in range(begin_page, end_page+1): sName = string.zfill(i,5) + '.html'#自动填充成六位的文件名 print u'正在下载第' + str(i) + u'个网页,并将其存储为' + sName + '......' f = open(sName,'w+') m = urllib2.urlopen(url + str(i)).read() f.write(m) f.close() #-------- 在这里输入参数 ------------------print u"""#---------------------------------------# 程序:百度贴吧爬虫# 版本:0.1# 作者:why# 日期:2013-05-14# 语言:Python 2.7# 操作:输入带分页的地址,去掉最后面的数字,设置一下起始页数和终点页数。# 功能:下载对应页码内的所有页面并存储为html文件。#---------------------------------------"""# 这个是山东大学的百度贴吧中某一个帖子的地址#bdurl = 'http://tieba.baidu.com/p/2296017831?pn='#iPostBegin = 1#iPostEnd = 10print u'例如:http://tieba.baidu.com/p/2296017831?pn='print u'请输入贴吧的地址,去掉pn=后面的数字:'bdurl = str(raw_input(u' '))print u'请输入开始的页数:'begin_page = int(raw_input(u' '))print u'请输入终点的页数:'end_page = int(raw_input(u' '))#-------- 在这里输入参数 ------------------ #调用baidu_tieba(bdurl,begin_page,end_page)
自己在上家写的那些找不到了,逻辑是 Python 爬虫脚本 爬取解析网页,提取有效字段,整理写入csv文件供市场部门使用
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Scrapy爬虫框架:
安装:
爬虫框架scrapy安装
入门使用:
新建工程:
scrapy startproject tutorial
建好的工程目录用IDE打开(这里我用的是pycharm)
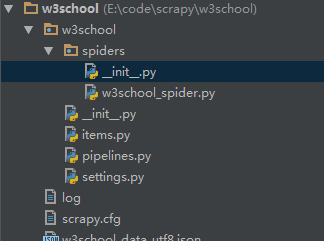
- scrapy.cfg: 项目配置文件
- items.py: 项目items文件,Items是将要装载抓取的数据的容器,它工作方式像python里面的字典
- pipelines.py: 项目管道文件
- settings.py: 项目配置文件
- spiders: 放置spider的目录
代码:
##items# -*- coding: utf-8 -*-# Define here the models for your scraped items## See documentation in:# http://doc.scrapy.org/en/latest/topics/items.htmlimport scrapyclass W3SchoolItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() link = scrapy.Field() desc = scrapy.Field()###################################pipelines.py# -*- coding: utf-8 -*-# Define your item pipelines here## Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.htmlimport jsonimport codecsclass W3SchoolPipeline(object): def __init__(self): self.file = codecs.open('w3school_data_utf8.json','wb',encoding='utf-8') def process_item(self, item, spider): line = json.dumps(dict(item)) + '\n' self.file.write(line.decode("unicode_escape")) return ite#################################################settings.py# -*- coding: utf-8 -*-# Scrapy settings for w3school project## For simplicity, this file contains only settings considered important or# commonly used. You can find more settings consulting the documentation:## http://doc.scrapy.org/en/latest/topics/settings.html# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.htmlBOT_NAME = 'w3school'SPIDER_MODULES = ['w3school.spiders']NEWSPIDER_MODULE = 'w3school.spiders'# Crawl responsibly by identifying yourself (and your website) on the user-agent#USER_AGENT = 'w3school (+http://www.yourdomain.com)'# Configure maximum concurrent requests performed by Scrapy (default: 16)#CONCURRENT_REQUESTS=32# Configure a delay for requests for the same website (default: 0)# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay# See also autothrottle settings and docs#DOWNLOAD_DELAY=3# The download delay setting will honor only one of:#CONCURRENT_REQUESTS_PER_DOMAIN=16#CONCURRENT_REQUESTS_PER_IP=16# Disable cookies (enabled by default)#COOKIES_ENABLED=False# Disable Telnet Console (enabled by default)#TELNETCONSOLE_ENABLED=False# Override the default request headers:#DEFAULT_REQUEST_HEADERS = {# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',# 'Accept-Language': 'en',#}# Enable or disable spider middlewares# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html#SPIDER_MIDDLEWARES = {# 'w3school.middlewares.MyCustomSpiderMiddleware': 543,#}# Enable or disable downloader middlewares# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#DOWNLOADER_MIDDLEWARES = {# 'w3school.middlewares.MyCustomDownloaderMiddleware': 543,#}# Enable or disable extensions# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html#EXTENSIONS = {# 'scrapy.telnet.TelnetConsole': None,#}# Configure item pipelines# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.htmlITEM_PIPELINES = { 'w3school.pipelines.W3SchoolPipeline': 300,}# Enable and configure the AutoThrottle extension (disabled by default)# See http://doc.scrapy.org/en/latest/topics/autothrottle.html# NOTE: AutoThrottle will honour the standard settings for concurrency and delay#AUTOTHROTTLE_ENABLED=True# The initial download delay#AUTOTHROTTLE_START_DELAY=5# The maximum download delay to be set in case of high latencies#AUTOTHROTTLE_MAX_DELAY=60# Enable showing throttling stats for every response received:#AUTOTHROTTLE_DEBUG=False# Enable and configure HTTP caching (disabled by default)# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings#HTTPCACHE_ENABLED=True#HTTPCACHE_EXPIRATION_SECS=0#HTTPCACHE_DIR='httpcache'#HTTPCACHE_IGNORE_HTTP_CODES=[]#HTTPCACHE_STORAGE='scrapy.extensions.httpcache.FilesystemCacheStorage'#################################################w3school_spider.pyfrom scrapy.selector import Selectorfrom scrapy import Spiderfrom w3school.items import W3SchoolItemclass W3schoolSpider(Spider): name = "w3school" allowed_domains = ["localhost"] start_urls = ["http://127.0.0.1:8080/myregister.html"] def parse(self, response): sel = Selector(response) sites = sel.xpath('//div[@id="navsecond"]/div[@id="course"]/ul[1]/li') items = [] for site in sites: item = W3SchoolItem() title = site.xpath('a/text()').extract() link = site.xpath('a/@href').extract() desc = site.xpath('a/@title').extract() item['title'] = [t.encode('utf-8') for t in title] item['link'] = [l.encode('utf-8') for l in link] item['desc'] = [d.encode('utf-8') for d in desc] items.append(item) #log.msg("Appending item...",level='INFO') #log.msg("Append done.",level='INFO') return items其中有使用XPATH解析,跟XML很像,不太熟悉的话可以去W3school学习下
参考:
知乎:http://www.zhihu.com/question/20899988
scapy:http://www.cnblogs.com/txw1958/archive/2012/07/16/scrapy-tutorial.html
阅读全文
0 0
- 爬虫总结
- 爬虫总结
- 爬虫总结
- 爬虫总结(四)-- 分布式爬虫
- 高考爬虫总结
- python爬虫技术总结
- java网络爬虫-总结
- python爬虫问题总结
- python 爬虫总结(一)
- Python爬虫技巧总结
- python爬虫总结
- Python爬虫学习总结
- 网络爬虫技术总结
- 爬虫总结(二)-- scrapy
- 大规模爬虫流程总结
- 反爬虫策略总结
- Java网络爬虫-总结
- [Python]网络爬虫总结
- JAVA 并发
- 51nod 1106质数检测(小素数)
- Java中设置classpath、path、JAVA_HOME的作用
- 爬虫框架scrapy安装
- Mysql安装图解(win7系统下)
- 爬虫总结
- 【后台】Apache&tomcat&jboss&nignx
- 用python训练机器学习
- ubuntu操作系统下spark源码走读环境搭建
- 剑指offer 之 二叉树的镜像
- MySQL数据库入门练习200句
- bzoj 1409 Password 矩阵快速幂+欧拉函数
- CF --- 832D Misha, Grisha and Underground 【LCA + 思维】
- 图像基础7 图像分类——余弦相似度


