服务器技术系列综述(一)
来源:互联网 发布:sql视频课程 编辑:程序博客网 时间:2024/04/29 01:24
本人职业是linux上网络服务器的开发,本文就网络服务器的系统架构设计的细枝末节展开讨论。欢迎任何的点评指导和讨论,尤其是对文中的缺点或者更好的方案。
一 系统框架概述
网络上的服务器,无论是嵌入式的网络设备,还是pc上服务器,整体结构以及主要思想都大体相同:根据业务模型确定主要数据结构,根据数据结构确定线程模型,在各个业务线程内根据围绕主要数据结构进行的操作确定状态机模型,低层使用网络层收发数据完成和其它网元的通讯。线程交互模型简单描述如下图: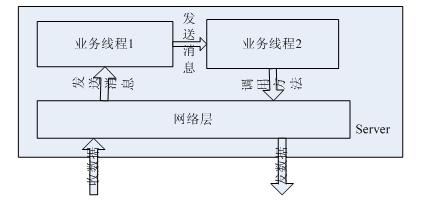
其中网络层包括收发模块,收数据模块是单独线程,而发数据模块则被业务线程调用在其本身线程中发送数据,网络层收到数据后也可能向多个业务线程发送消息,业务线程可能1个,也可能多个,业务线程之间可能存在消息发送,最终会调用网络层的发送方法完成本server的功能。
二 网络层
相对而言,网络层的实现相对呆板、模式化,这个层面的要点在系统调用,实现方式要符合操作系统提供的api允许的使用方式,而不能天马行空想当然,因此提高这部分能力的重点在于系统性的学习(《unix网络编程》),不再于经验。
网络层有3部分构成:连接细节、多路复用函数、协议解析。
(1)连接细节。要实现各个协议的网络层(协议栈),首先要面对的就是承载该协议的传输层协议,udp还是tcp,理论本身就不再多说了。简单说下编程上的差异:udp的网络连接简单、收数据简单,tcp的则网络连接复杂、收数据需要在应用层面确定是否一个收包完毕,tcp部分可以参见《【原创】技术系列之 网络模型(一)基础篇》。
(2)多路复用函数。除了处理udp、tcp本身网络连接的系统调用之外,还存在和udp/tcp无关的多路复用函数(select等),它们可以监控tcp的网络事件,也可以监控udp的网络事件,属于网络层的核心驱动部分。可以参见《【原创】技术系列之 网络模型(三)多路复用模型》
(3)协议解析。这部分相对独立,是网络层中和网络连接、收发消息无关的部分,主要功能则是对该协议各种消息的解包(decode)、打包(encode)。
网络层的主要线程是多路复用监控线程(select/poll/epoll_wait等),网络消息触发该线程的运转,如果是收包,则调用read类函数,收包完毕,进行解包操作,之后根据需要向业务线程发送消息(也可以收包完毕后即把数据包裹在消息中发送给业务线程,由业务线程解包,单仍把解包打包操作归在网络层中)。
性能方面:为了描述方便,引入使用场景:转发rtp码流,这个场景需要尽量大的并发行和实时性。
(1)高性能函数。如果系统支持,使用epoll/port/kqueue等高性能多路复用函数。在此,将多路复用监控线程封装在RtpService类中,将rtp连接,封装在RtpConnection类中。使用模型可以参见《【原创】技术系列之 网络模型(二)》
(2)多线程支持。启动多个RtpService示例,也既是启动多个多路复用监控线程。将RtpConnection对象均匀的插入到各个RtpService中,同时在RtpConnection中记录它属于的RtpService,便于删除的时候找到它所在的RtpService。
(3)收数据线程直接转发。处于实时性的需要,一定要在收数据的线程转发数据,而不是向其它线程发送消息,让其它线程完成发送。这样做一是避免不必要的内存复制,最重要的是,线程调度引起的时间不确定性不能保证转发的实时性。
(4)读写锁代替普通锁。分发数据的时候(转发不需要)势必要扫描一个容器中的对象,进行分发操作,分发发生在不同的线程中,加锁成为必然。读写锁代替普通锁,使扫描操作不必互斥,也避免(2)中的多线程不能发挥多线程的效果。注意:测试发现,linux2.6内核中的读写锁,只有在静态初时化的时候,才能写优先,使用pthread_rwlock_init进行初始化,不管如何设置它的属性(即便是设置属性为写优先),都不能实现写优先效果,因此需要自己使用pthread_mutex_t和pthread_cond_t实现写优先的读写锁,具体实现的细节就不再多说了(可以参考《【原创】技术系列之 线程(二)》中线程消息队列中锁的实现),重要的是想法,不是实现。写优先的必要性是因为转发线程活跃频繁,而读线程可以一直进入读锁,造成写线程永久性的处于等待状态。
(5)使用Epoll的ET模式。再此对epoll多说一点,在《【原创】技术系列之 网络模型(三)多路复用模型》
中因为我当时的测试场景是普通的http交互,得出“LT和ET性能相当”的结论,跟帖中网友bluesky给予更正,非常感谢。在这个rtp转发的场景中,特别适合ET模式,一次触发,必须读尽接收缓冲区的数据,一是保证转发实时性,一是避免剩余数据再次触发(并发高的情况下,多路复用函数的被触发已非常频繁,因此要尽量减少不必要的触发),这个场景下,多一次的读操作微不足道。
(6)减少系统调用次数。系统调用是比内存copy性能更差的操作,这个再后面的文章中会再详细描述。网络层中的系统可以减少的就是read/recv/recvfrom类的操作,极端化低性能的操作就是一次读一个字节,造成系统调用的次数大幅上升,一般的做法,是开辟缓存(比如char buf[4096];),一次读取尽可能多的字节。
(7)二进制包使用结构直接解包,字符性包延迟解包。这两点的出发点都是尽量减少内存复制。二进制解包举例:首先根据协议规定的包结构,定义结构体。
比如(注:网友powervv 跟帖指出,要点在于大小端主机序、网络序和主机序之间的转换、以及字节对齐问题,避免误导读者,举例做出修改):
 struct RTPHeader
struct RTPHeader {
{
 #if __BYTE_ORDER == __BIG_ENDIAN unsigned char v:2; unsigned char p:1; unsigned char x:1; unsigned char cc:4; unsigned char m:1; unsigned char pt:7; #else unsigned char cc:4; unsigned char x:1; unsigned char p:1; unsigned char v:2; unsigned char pt:7; unsigned char m:1;#endif unsigned seq:16; unsigned tm:32; unsigned ssrc:32;
#if __BYTE_ORDER == __BIG_ENDIAN unsigned char v:2; unsigned char p:1; unsigned char x:1; unsigned char cc:4; unsigned char m:1; unsigned char pt:7; #else unsigned char cc:4; unsigned char x:1; unsigned char p:1; unsigned char v:2; unsigned char pt:7; unsigned char m:1;#endif unsigned seq:16; unsigned tm:32; unsigned ssrc:32; };
};收数据到buf,解包过程则是:
Packet *pack=(Packet *)buf完成解包,读取seq的时候,需要ntohs转化,tm同样要ntohl。
打包相同:
char buf[12];Packet *pack=(Packet *)buf;packe->v=2; .pack->seq=htons(1);
.pack->seq=htons(1);字符性包解包,则一般是预解包扫描buf,将每个字段的偏移和长度记录下来,等需要的时候在进行内存复制操作(常用的则是立即复制出来)。通常将字段使用枚举定义,比如有字段MAX_FIEDS_NUM个,定义开始位置和偏移结构:
struct FieldLoc{ int loc; int len;};则定义 FieldLoc[MAX_FIEDS_NUM],准备保存各个字段的偏移和长度。至于扫描字段引起的性能损耗和内存复制引起的性能比较将在后面阐述。
(8)内存池相关、系统调用以及内存复制等的代价这些通用性能部分后面会再有描述。
(本文首次发表于http://www.cppblog.com/CppExplore/archive/2008/10/23/64783.html)
- 服务器技术系列综述(一)
- 服务器技术系列综述(一)
- 服务器技术系列综述(二)
- 服务器技术系列综述(三)
- 服务器技术系列综述(二)
- 服务器技术系列综述(三)
- 计算机视觉入门系列(一) 综述
- CoordinatorLayout 使用综述系列(一)
- 服务器设计系列:架构综述
- iCloud(一)综述
- UML(一) 综述
- Hadoop综述(一)
- 计算机网络(一):综述
- 特征离散化系列(一)方法综述
- 特征离散化系列(一)方法综述
- webRTC:一、房间服务器的搭建(综述)
- ct技术综述(1)
- 从服务器构建说起(一).企业服务器综述
- 沃尔玛的信息技术:启迪中国零售业(转载)
- 职业之路
- 技术系列之 必备外围功能-log
- MB,怎么才能凑足积分下载啊
- 12个球一个天平,现知道只有一个和其它的重量不同,问怎样称才能用三次就找到那个球?
- 服务器技术系列综述(一)
- 项目整体流程
- 服务器技术系列综述(二)
- 关于Nginx+PHP的虚拟主机目录权限控制的探究
- 服务器技术系列综述(三)
- [转旧闻]Sun收购MySQL事件之透视与分析
- php 中的数组令人惊叹
- 《java与模式》读书笔记
- 项目管理之 个人小结


